Our groupeonepoint.com website and our partner use cookies and similar technologies to help us improve your browsing experience and features on the site to enhance its performance. While cookies strictly necessary for our website to function are related to our legitimate interest, technical functionality cookies and statistical (performance) cookies are all subject to your consent.
Retention
We keep your chosen options for up to 6 months. You can modify them at any time by clicking on “Cookie management” present at the bottom of each page of our website.
Shared
Google Analitycs and HubSpot uses cookies on our site.
For more information on our cookie management, see our Cookie policy, present at the bottom of each page of our website.
The Data Mesh: Trendy or a Real Tool for transforming your Business Model?
Amidst the growth of data sources and users, the range of transformations, the efficiency of data management is crucial. Proactively responding to events and to the constant evolution of the technological landscape are challenges that are difficult to manage for companies that have not set up an appropriate operating model, processes and culture.
Data allows the streamline of the daily operational functioning of a company. But, how do organisations become data centric, make data driven decisions and become AI-empowered?
There are many challenges that need to be explored in depth. Many “superficial” initiatives have ended in failure. This created some questioning toward the data function. Data management is a complex subject: in fact, to transform the company, it is not enough to equip your employees with a data visualisation tool, to appoint a chief data officer or to hire data scientists.
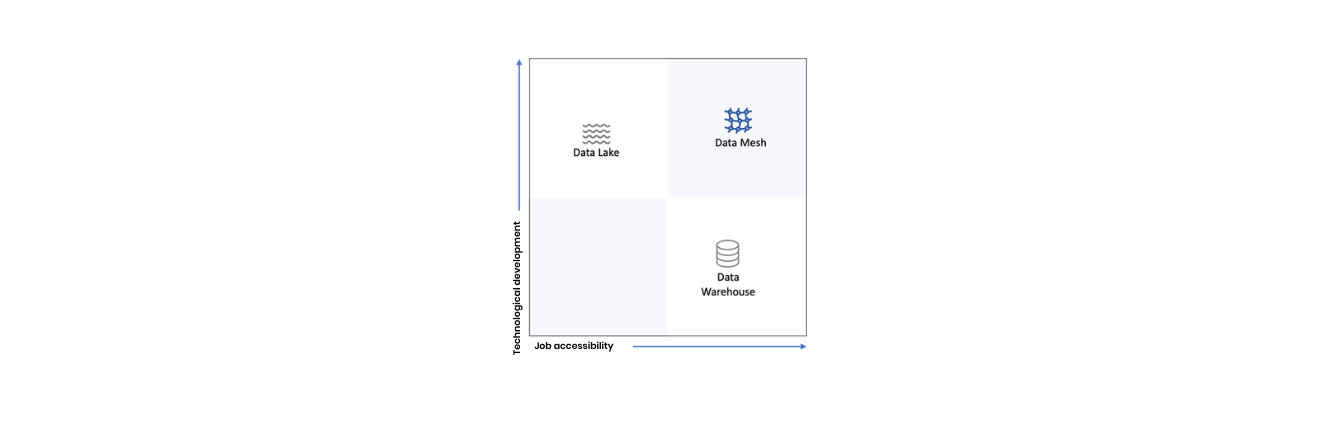
Let’s explore the brief history of the obsession of “putting data at the center” and where data is stored in the company.
Since the invention of the data warehouse at the end of the 1980s, the initial purpose of which was to make available source serving as a single reference, it has been mainly used by organisations as a reporting tool to make dashboard and take decisions from it. Its primary purpose was to establish a data center used as a centralised supply store (datamart), infocenter or data sink.
But datamarts and data sinks have multiplied, no longer ensuring the consistency or a single version of data. Later, the data lake “recentralised” the data sources by collecting them and locating them all in the same place. But the main customers of data lakes have unfortunately been the IT department themselves! For more than ten years Hadoop Distributions have delighted Big Data teams, who continue to access their historical data warehouses. A bit less the other business teams who have seen it only as a technical solution for technical people by technical people. It is therefore clear that none of the solutions discussed above are up to the challenge that the fourth industrial revolution offers us: in the data economy, data must be an accessible and reliable source that creates value.
This is the value proposition of the Data Mesh, a paradigm that makes it possible to get out of the centralisation obsession by leaving the data “where it is”. That is to stay close to the business and their systems. Thus, ensuring its quality and reliable storage by the subsidiarity principle while empowering a better access governance.
If you want to break down the information silos and business challenges related to data usage, would the Data Mesh be the magic solution to democratise and scale the use of data within an organisation?
What is the Data Mesh?
Let’s cut short the preconceived idea: the Data Mesh is not a new type of architecture. It is a paradigm aiming to make data available and accessible, at scale. The objectives are the following:
Respond to the complexity, volatility, and uncertainty of doing business
Remain proactive as a business grows
Create more value, in proportion to the investment
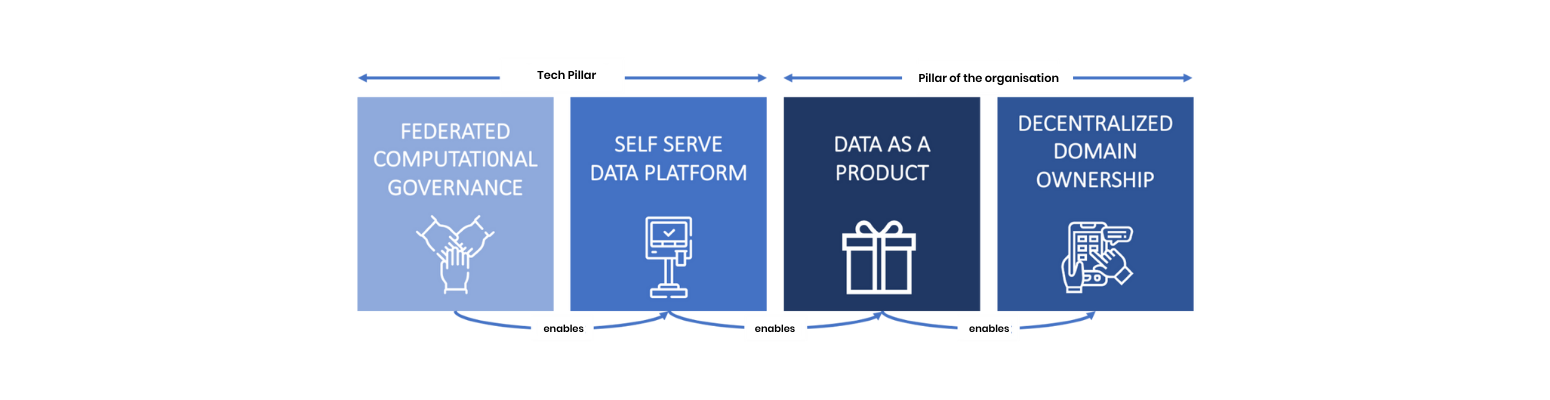
The Data Mesh is based on four founding pillars:
DECENTRALISED DOMAIN OWNERSHIP: inspired by Domain Driven Design, the main pillar of Data Mesh is the decentralisation and distribution of responsibilities, as close as possible to the data. For this, it is necessary to rely on an architecture that logically divides data storage and computing resources by domain. This non-technical division will allow the domain teams to be autonomous, and thus to allow scaling.
DATA AS A PRODUCT: the Data Mesh implies managing the data as a product. The data is thus no longer the energy that will help propel the product, but is the product itself. It is therefore necessary to set up various services to access it (APIs, Data Marketplaces, etc.) and allow the other products of the company to be augmented using this data.
DATA SELF SERVICE: having a catalog of services for developers, acting as a high-level abstraction layer of the data service infrastructure. Services should simplify data management to make it efficient and easy to perform. The goal is to allow the autonomy of the domains vis-à-vis the Infra teams.
FEDERATED COMPUTATIONAL GOVERNANCE: making governance automated and having each domain autonomous. The rules of governance must be standardised to be interoperable, hence the need for federation.
What are the advantages?
The Data Mesh promises certain advantages relating to the exploitation of data in business:
1) With DECENTRALISED DOMAIN OWNERSHIP, data is accessible by both business teams and data experts, thus facilitating collaboration. Domain teams responsible for the data improves its quality. The autonomy of domain teams also makes the data growth management easier.
2) Thanks to DATA AS A PRODUCT, domain experts are closer to product design because they are included in agile teams, hence becoming more autonomous. The IS is also becoming more flexible due to data being managed, being considered as their own products. Finally, experimentation is easier and can be performed more easily in production.
3) With the SELF-SERVE DATA PLATFORM, relations between urban planners and architects are better. Data Engineers are more productive and autonomous because they have the tools and templates that facilitate and secure their development. This increases the growth in new products.
4) FEDERATED COMPUTATIONAL GOVERNANCE brings consistency in governance rules, industrialised monitoring, reduction of errors and costs, and increased confidence due to rules designed at the level of each domain. Business applications are designed to exchange data, which facilitates internal and external collaboration. This is ending the single central data team, as shared responsibility is emerging, thus ensuring better quality and more data collaboration. In summary, the Data Mesh facilitates autonomy, industrialization, and the adoption of data use cases with more collaboration and efficiency.
How to get to the net to initiate this transformation?
The Data Mesh is implemented iteratively by building on the existing one. There is therefore no single way to address this approach. The action plan must be adapted to the size of the company, data maturity, agile and data governance maturity. However, this transformation must be guided by the required return on investment, as IT investment is crucial to a business. It is also necessary to understand challenges of the data economy during the Data Mesh transformation.
Data Mesh also involves data accessibility which means that the related tools, technologies, and processes must be as accessible as possible. They must be highly adaptable to their users, to facilitate real adoption. Here are some tips to get you started on the organisational pillars:
A – The Data Mesh to capture the sources of value: make sure to demonstrate the ROI of the approach at each stage and to each stakeholder
Awareness of the concepts of Data Mesh and ROI of the approach to decision-makers
The Data Mesh can potentially influence your business organisation. Hence, make sure to develop a data-centric organisation, with decision makers and actors, like partnerships with other organisations.
Focus on the four pillars of Data Mesh in the company to measure maturity and determine the actions to be taken
Take the four axes and evaluate your organisation collectively via self-assessment questionnaires. Analyse the results and launch an action plan to tackle your business priorities and objectives.
Address the four axes in an agile, incremental way and guide the transformation by case studies.
Guide yourself with concrete case studies, implement agility processes at scale to ensure transparent governance, value prioritisation and excellent visibility at the scale of the company.
B – The Data Mesh as a framework for the data sector: make sure to optimise the user experience by making processes, technologies and roles accessible.
Create a Data Marketplace accessible to all. Even if the process for data is decentralised, data won’t necessarily be accessible via a multitude of routes. Like an e-commerce site, create a place of transaction to facilitate the use of data. Make technologies, roles, concepts, definitions and processes easily accessible to consume and produce data by and for the company.
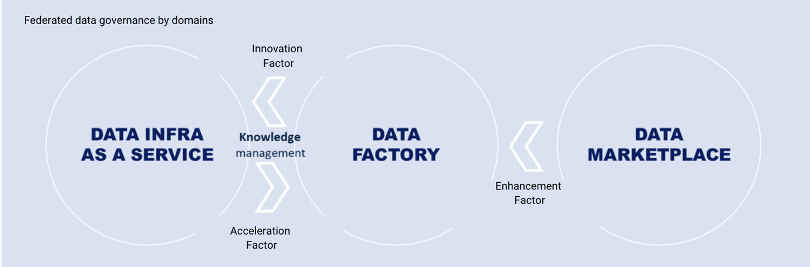
Get started with three key teams that can help you quickly make this transformation possible
A Data Infrastructure-as-a Service team helps set up the self-service infrastructure and provides an architectural framework for the enterprise. It provides technical components that meet the five non-functional compliance requirements (reliability, security, confidentiality, integrity and maintainability).
A Data Factory team supports businesses in their Data as a Product & Federated Computational Governance approaches. It brings out the value of data and responds to business uses while providing a framework for the range of domain-driven micro-services.
A team and an internal Data Marketplace site highlights all the company’s data tools (self-bi tools, data cataloging tools, business dictionary), processes for using them (how to request access to data from a business domain, how to make an open data ingestion request), the roles of the company in terms of governance (data stewards, data owners) in one place.
Again, these are logical teams that can exist within the central governance body and domains.
C – The Data Mesh to develop the data culture of the company: Make sure to understand and adopt the structuring points
Strengthen your methodologies, processes, and tools to increase collective intelligence. Spread responsibility for information assets within all business lines from the start of your transformation.
Knowledge Management – Use your Data Marketplace to disseminate business data usage processes, including patterns, models and tools accessible on the infrastructure-as- a-service platform.
Governance by design – Involve all responsible players in the creation and industrialization of data-intensive applications.
Agility at scale – Take inspiration from agile methodologies and ceremonies to organise your data production and delivery cycles with stakeholders across the enterprise.
Data transformation is above all cultural transformations. Make technologies, and concepts as accessible as possible so that it becomes the new standard in the company.
Towards the informational exoskeleton of the company in the data era
The Data Mesh is neither an enterprise architectural canon nor a goal. Because it is not self-decreed (no company can decide to “set up a Data Mesh”), Data Mesh’s purpose is to bring the data and the organisation together.
Beyond the architectural concepts, the Data Mesh provides organisational, cultural, conceptual and technological elements so that the data can facilitate business transformations, thereby making it possible to reconcile developers and users.
The Data Mesh cannot be reduced to its instrumental scope. It has the capacity to self-produce, continuously and in interaction with its ecosystem, thus allowing it to maintain its purpose of access and exposure to data despite the evolution of the environment. This is what could make it possible to outline the real informational exoskeleton of the company.
Written by Maria José Lopez (Leader Product), Christophe Heng (Leader Data) & Gontran Peublez (Partner)