De cette problématique d’exploitation des données émerge notamment l’enjeu relatif à la capacité de les traiter en temps réel. L’exemple d’Epic Games à travers son jeu Fornite va en ce sens. Avec 125 millions de joueurs, 92 millions d’événements à la minute et des pics de collecte de 37 térabytes de données à la seconde, la société se doit de traiter et de stocker les données générées par son application à travers des outils de Data Streaming. Ceci afin d’améliorer l’expérience utilisateur en luttant notamment contre les menaces de cyberattaque ou les tentatives de triche. De même, le secteur bancaire illustre aussi très bien ce besoin, par la détection de fraude en temps réel. Alors quels sont les concepts derrière l’ingestion, le stockage et le traitement de données en temps réel ?
Cet article vise à présenter les grands principes d’Architecture autour de ces concepts et les plateformes permettant de les implémenter.
L’Architecture Data traditionnelle atteint ses limites
En général, les Architectures (Big) Data sont faites pour traiter les données par lots de manière périodique (batch).
Ce traitement par lots ne s’adapte pas à la problématique du temps réel. En effet les traitements par lot sont souvent longs et ne permettent donc pas d’exploiter les données au fil de l’eau et de réaliser des traitements temps réels.
Pour pallier ce problème, de nouvelles Architectures sont apparues : l’Architecture Lambda et l’Architecture Kappa.
Temps réel et traitements complexes : l’Architecture Lambda
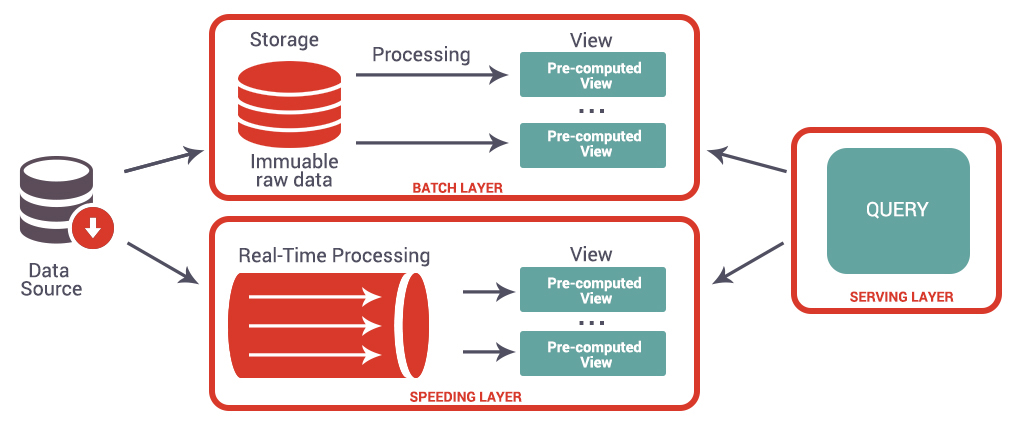
L’Architecture Lambda a été conçue pour faire cohabiter le traitement par batch et le traitement en temps réel. Elle se décompose en 3 couches principales :
- Batch Layer
- Speed Layer
- Serving Layer
La couche « Batch Layer » reprend les principes de l’Architecture traditionnelle, elle a deux buts principaux :
- Stocker les données massivement collectées (données brutes) comme par exemple les logs d’une application
- Traiter les données qui ne viennent pas du canal temps réel et croiser différentes sources de données
Une fois que les traitements ont été réalisés, les résultats sont transmis à la couche « Serving layer ».
La couche « Speed Layer » a pour rôle de collecter et traiter la donnée temps réel. Elle calcule des vues incrémentales qui vont venir compléter les vues batch avec les données les plus récentes.
La couche « Serving Layer » récupère, stocke et agrège les résultats fournis par les couches « Batch Layer » et « Speed Layer ». Les vues ainsi créées sont agrégées et le résultat restitué à l’utilisateur.
L’avantage de cette Architecture est qu’elle reste compatible avec les Architectures Data traditionnelles, tout en les complétant avec la couche temps réel. De plus, cette Architecture est complètement indépendante des technologies sous-jacentes aux différentes couches. Cependant, l’Architecture Lambda demande de maîtriser plus d’outils et de maintenir deux couches (Batch Layer et le Speed Layer) au lieu d’une seule. Par sa complexité, cette Architecture n’est ainsi pas adaptée à tous les cas d’usage.
Une Architecture simplifiée : l’Architecture Kappa
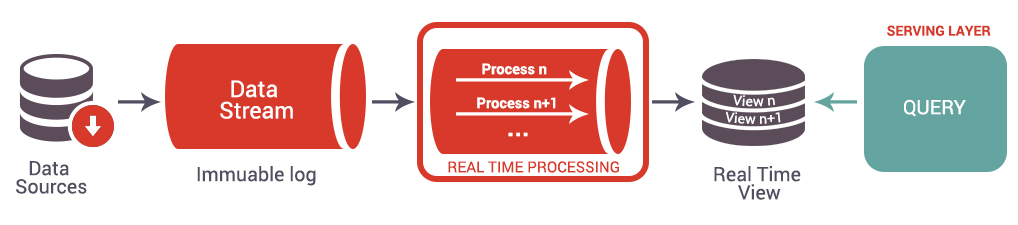
L’Architecture Kappa propose une alternative à la complexité de l’Architecture Lambda en fusionnant les couches temps réel et batch. Dans l’Architecture Kappa, il est possible d’utiliser la brique de Data Stream comme lieu de persistance. En pratique, la rétention sur ce type de système est limitée, seul Kafka permet de stocker un historique profond de données à l’aide d’un cluster dimensionné pour ce cas d’usage. Les données sont donc acheminées et stockées via des outils tel qu’Apache Kafka avant d’être traitées et envoyées à la « Serving Layer ».
Une vision pragmatique de l’Architecture Data temps réel
Même si l’Architecture Kappa ne prévoit pas de stockage permanent des données temps réel, elle peut être adaptée en fonction des besoins. En effet, dès lors qu’il y a un besoin complémentaire à celui de traitement en temps réel, comme entraîner un modèle de Machine Learning ou garder une trace des actions réalisées pour les reconsulter ultérieurement, il sera nécessaire de créer un historique profond des données. Bien que certaines entreprises utilisent aujourd’hui Kafka pour stocker leurs données brutes, il est aussi possible de stocker les données en streaming avec des moyens de stockage plus classiques, sans pour autant modifier les autres traitements.
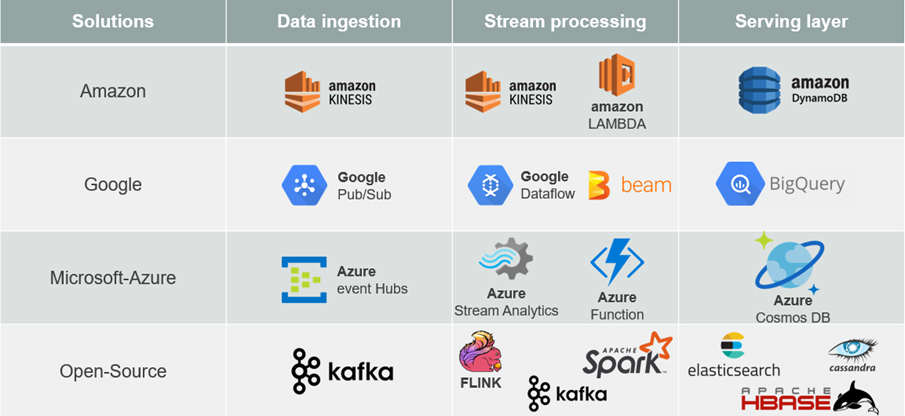
Les outils du marché pour implémenter les Architectures Data temps réel
Conclusion
Le traitement des données en temps réel devient aujourd’hui un enjeu majeur et les Architectures traditionnelles ne sont pas en mesure d’y répondre. Deux grands types d’Architecture proposent donc des alternatives à ce besoin émergeant : l’Architecture Lambda et l’Architecture Kappa. L’Architecture Lambda est toute indiquée lorsqu’un Data Lake est déjà en place et dans lequel sont réalisés des croisements sur les données. L’Architecture Kappa quant à elle est plus adaptée à un besoin temps réel sans stockage permanent. Finalement, cette dernière peut être adaptée pour une Architecture plus pertinente en conservant les avantages de l’Architecture Kappa tout en bénéficiant du stockage de l’historique des données. Ceci permet notamment d’entraîner des algorithmes de Machine Learning à partir de cet historique.