
Peut-on détecter les textes écrits par une IA ?
Un sujet important et… controversé !
A l’occasion d’un colloque qui s’est tenu pendant l’été 1956 dans le New Hampshire une poignée de chercheurs en informatique et en science cognitives ont formulé le premier programme de recherche en IA de l’histoire. Leur ambition n’était ni plus, ni moins que de concevoir des machines « à même de résoudre des problèmes habituellement réservés aux humains et capables d’utiliser le langage naturel ». Soixante-sept ans se sont écoulés depuis cet évènement fondateur. Au vu des difficultés et des désillusions qui ont jalonné la recherche en IA durant toutes ces décennies on peut être tenté de sourire à lecture de cette ambition prométhéenne, tant elle nous apparaît rétrospectivement naïve. Cependant, on peut aussi regretter cet optimisme, cette foi dans la science et la technologie, qui caractérisait la genèse de la discipline.
Autres temps, autres mœurs, alors qu’en 2023 une partie de cet objectif pourrait bien se concrétiser avec l’avènement des gros modèles de langues (LLM pour Large Language Models) comme GPT-4, LLAMA ou Bloom, une frange de notre société se préoccupe moins des possibilités émancipatrices de cette nouvelle donne technologique que de l’ouverture de la boite de Pandore consécutive à son dévoiement en tant que plagiaire universel : tsunami de « fake news » et de faux commentaires submergeant internet, tricheries aux examens, ingénierie sociale, manipulations d’élections sont des menaces désormais tout à fait crédibles. Sans parler des mouvements complotistes qui, encouragés par le discrédit généralisé touchant désormais toutes les sources d’information, y trouveront un terreau fertile pour leurs élucubrations toxiques.
Devant ce vertige certains chercheurs, et non des moindres, en sont venus récemment à réclamer une pause dans la course [1] effrénée et irréfléchie à la puissance des LLM. S’il devait y avoir une pause, sans doute faudrait-il prioritairement la mettre à profit pour débattre des moyens techniques, s’ils existent, pour identifier les textes générés par ces LLM. Sans attendre une telle pause, au demeurant fort hypothétique, de nombreuses équipes de chercheurs se sont cependant déjà attelés à la tâche. Sans qu’aucun consensus clair n’émerge pour l’instant quant à sa faisabilité, différentes équipes de chercheurs parvenant à des conclusions en apparence contradictoires.
L’objectif de cet article est de faire le point sur ces travaux en utilisant un minimum de formalisme. Dans la section suivante nous décrirons trois approches proposées récemment pour construire un détecteur de textes rédigés par un LLM. Dans la section qui suit nous mettrons en évidence plusieurs vulnérabilités de ces schémas de protection vis-à-vis d’attaques astucieuses. Nous examinerons ensuite les limites fondamentales et les compromis incontournables qui contraignent toute tentative de détection. Enfin, nous proposerons quelques mots de conclusion sur des approches alternatives.
Trois méthodes de détection d’un texte rédigé par un LLM
Des LLM on retiendra simplement qu’il s’agit de modèles statistiques qui construisent une réponse à un prompt en générant de manière récursive une suite de mots probables à partir de ceux qui ont déjà été générés. Entraînés sur des corpus de textes à l’échelle d’internet, ces LLM manifestent des propriétés émergentes surprenantes au sens où ils semblent dotés d’une forme de bon sens qui était longtemps l’un des Graal de l’IA. C’est le mérite des chercheurs d’OpenAI que d’avoir les premiers [5,6] fait cette observation et d’avoir développé l’infrastructure logicielle et matérielle pour explorer cette approche au traitement du langage naturel à une échelle inédite [7].
Pour détecter des textes générés par un LLM il existe à ce jour trois approches principales.
- La première méthode est la plus simple d’un point de vue conceptuel. Elle envisage le problème de détection de textes générés par une IA comme un problème de classification binaire supervisé [5]. Elle consiste donc à entrainer un gros réseau de neurones (RN) pour lui apprendre à distinguer les textes générés par un LLM des documents rédigés par des humains. Il faudra pour cela entraîner un nouveau réseau de neurones, typiquement par fine-tuning du LLM dont on souhaite détecter la production.
- La deuxième approche, dite détection zero-shot, possède l’avantage de n’exiger aucune collecte de données, ni aucun entraînement supplémentaire [6]. Elle se contente d’utiliser le LLM source pour construire le détecteur et évite, entre autres, certains problèmes de surapprentissage observés dans l’approche précédente qui utilise un second RN. Rappelons que chaque LLM définit une distribution de probabilité qui assigne un score p(x) à chaque texte x. L’intuition derrière l’approche zero-shot est qu’un texte x_ « fake » généré par ce LLM aura une probabilité p(x_« fake » plus grande que celle de paraphrases mineures en son voisinage. En revanche, un texte x_« human » généré par un humain ne possèderait pas cette propriété. De fait, cette intuition se vérifie expérimentalement et l’idée peut être implémentée pour détecter les textes générés par un LLM. Dit autrement, un LLM laisse un empreinte statistique implicite dans les textes qu’il génère et ceci devrait permettre son identification. L’une des faiblesses de cette approche est qu’elle demande d’avoir accès à la fonction de probabilité p(x). Son implémentation ne pourra donc être faite que par le concepteur du LLM ou par une tierce partie pour autant que coût d’accès au LLM via une API ne soit pas prohibitif.
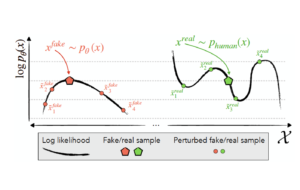
- La dernière approche était l’une des plus prometteuse [7] jusqu’à récemment. Elle propose d’insérer un filigrane statistique (watermarking) dans les textes générés par un LLM. Concrètement, l’insertion d’un tel filigrane va consister à modifier, légèrement, les probabilités avec lesquelles les mots sont générés. Pour que le filigrane soit efficace il faut alors concilier deux impératifs en tension : d’une part, ne pas dégrader la qualité perçue du texte et, d’autre part, permettre une détection fiable du filigrane, au moins pour les textes assez longs. Rappelons qu’à chaque étape t de son processus génératif un LLM sélectionne dans son vocabulaire le mot w(t) le plus probable en fonction de la liste de mots générés auparavant. Dans une implémentation simpliste de cette idée de filigrane on définit à chaque instant t, juste avant que le LLM ne génère le mot w(t), une partition du vocabulaire en mots « verts », ceux que le modèle a le droit de générer, et en mots « rouges », ceux qui lui sont interdits. Cette partition est pseudo-aléatoire et est réinitialisée à chaque instant à l’aide d’une fonction de hachage dépendant du mot w(t-1) généré à l’étape précédente. On conçoit aisément cependant que cette première approche n’est pas vraiment réaliste. Les chances sont élevées en effet pour que le texte soit mutilé par cette contrainte. Considérons le mot « Barack ». Dans un texte non marqué, il a de grandes chances d’être suivi du mot « Obama ». Dans ce cas on ne pourra impunément lui substituer un mot différent sous peine d’altérer la crédibilité du texte. Ce problème n’est toutefois pas insurmontable et l’on peut affiner l’idée précédente en substituant l’autorisation et l’interdiction strictes des listes « vertes » et « rouges » par une approche dite de « soft watermarking » qui ne fait que les favoriser ou défavoriser légèrement l’apparition des mots dans ces les catégories. Dans cette version améliorée du filigrane, un mot très probable comme « Obama » ne sera plus substitué, seuls les mots ayant une probabilité plus faible pourront l’être. Un texte comportant une proportion de mots « verts » significativement plus grande que celle dictée par le simple hasard sera alors identifié comme ayant été généré par un LLM. Les premières expériences pratiques se sont révélées plutôt encourageantes [7].

L’imagination sans limites des hackers
De nombreuses attaques
ont été imaginées pour échapper aux détecteurs de textes générés par un LLM. Une analyse raisonnablement exhaustive remplirait aisément un article scientifique de plusieurs dizaines de pages. Aussi, nous nous bornerons ici à décrire trois types d’attaques importantes afin d’illustrer la vulnérabilité des principes de détection décrits précédemment.
Pour éviter que son texte ne soit démasqué par un détecteur de filigrane, un fraudeur devra l’effacer ou au moins l’atténuer. Pour y parvenir il devra augmenter de manière significative la fraction de mots « rouges » du texte ce qui abaissera le seuil de détection. Plus généralement, il s’agit de masquer toute empreinte statistique que pourraient détecter les approches zero-shot et les classifieur binaires.
- L’attaque par émoticônes [7] fragilise spécifiquement la protection par filigrane en perturbant intentionnellement le mécanisme de hachage qui détermine les listes de mots « verts » et « rouges ». Pour cela on peut tirer parti de la puissance des LLM récents et leur demander de rajouter un pattern d’émoticônes (ou tout autre suite de symboles) à la fin de chaque mot. Le mécanisme de hachage du filigrane utilisera alors ces pseudo-mots qui se terminent par ces émoticônes, plutôt que les mots eux-mêmes. Une fois ces émoticônes enlevées, une tâche simple car réversible, chaque mot sera alors, au hasard « vert » ou « rouge » selon la partition que détermineraient les mots non affublés d’émoticônes. Le filigrane aura donc été complètement effacé ! Cette attaque présuppose néanmoins que le LLM est assez puissant pour procéder à l’insertion des symboles trompeurs sans dégrader la qualité du texte.
- L’attaque par smart-prompting [8] : Plus subtile que l’attaque précédente, elle cherche à également exploiter une faiblesse inhérente à l’approche par filigrane. Rappelons qu’un filigrane est inséré avant la génération des mots par le LLM en favorisant légèrement les mots « verts » au détriment des mots « rouges ». En pratique, un tel filigrane ne pourra toutefois être inséré que dans un texte dit à haute entropie, autrement dit un texte pour lequel le LLM n’est capable de prédire les mots à générer qu’avec une incertitude moyenne relativement importante. Pour rendre difficile l’insertion d’un filigrane efficace on peut alors chercher à exploiter la puissance d’un LLM en le sollicitant à l’aide d’un prompt astucieux conçu pour réduire cette incertitude autant qu’il est possible. Une solution simple consiste par exemple à rédiger un prompt par lequel on demandera au LLM de n’utiliser que les mots figurant dans une certaine liste, ce qui réduira considérablement l’entropie du texte de la réponse et diminuera d’autant l’empreinte du filigrane.
- L’attaque par paraphrases [7, 8] : Simple mais redoutable, l’attaque par paraphrase fragilise toutes les techniques de détection. Elle présuppose que l’attaquant dispose de son propre LLM « léger » pour automatiser la rédaction de paraphrases du texte généré par le LLM original, ceci afin d’éliminer toute empreinte statistique du « gros » LLM original. En pratique la reformulation procèdera phrase par phrase et l’attaque ne réussira que si la fluidité du texte n’est pas trop altérée pour éveiller les soupçons d’un lecteur humain vigilant. Remarquons au passage qu’utiliser un LLM très puissant pour rédiger des paraphrases n’a guère de sens car l’attaquant, s’il disposait d’un tel outil, pourrait l’utiliser directement pour produire un document dépourvu de filigrane.
Le génie créatif humain n’étant jamais autant stimulé que lorsqu’il s’agit de duper son prochain, il y a fort à parier que d’autres attaques ont été conçues sans être divulguées.
Des limites et des compromis inévitables
Une difficulté fondamentale à laquelle doit se confronter toute technique de détection d’un texte généré par un LLM est qu’il est par nature impossible d’anticiper tous les moyens possibles pour l’esquiver. Une branche de salut pourrait provenir d’un résultat théorique, idéalement un théorème, qui prouverait que la détection est effectivement possible, au moins en principe. Un tel résultat garantirait alors que la quête n’est pas vouée à l’échec à priori. Charge aux esprits imaginatifs de trouver le moyen de réaliser le détecteur. Hélas, dans le cas de la détection de textes générés par des LLM, la réalité mathématique est têtue et tend plutôt à démontrer l’inverse [8]. Il nous faut donc faire le deuil de notre espoir de concevoir des détecteurs parfaitement fiables. Tout est-il perdu pour autant ? Non, car un détecteur, même imparfait, pourrait malgré tout être utile en pratique.
Pour y voir clair et pour énoncer précisément les compromis qui structurent notre problème de détection, nous rappelons ci-dessous quelques définitions élémentaires en relation avec la détection d’anomalies. Dans notre contexte l’anomalie sera assimilée à la présence d’un pattern statistique dans un texte, comme un filigrane par exemple.
Un tel pattern est toujours détecté à l’aide d’un score z qui devra dépasser un certain seuil γ. Concrètement, pour un texte généré par un LLM muni d’un filigrane, ce signal z pourrait être l’écart entre la fraction de mots « verts » dénombrés dans un texte suspect et la proportion attendue en l’absence de filigrane (50% si les listes « rouges » et « vertes » sont de tailles égales). En faisant varier la valeur de ce seuil γ on peut régler la sensibilité du détecteur et ainsi ajuster le compromis entre les erreurs de type I (False Positive Rate = FPR), celles où l’on attribue à un LLM un texté rédigé par un humain, et les erreurs de type II (False Negative Rate = FNR), celles où un texte généré par un LLM échappe à la détection. La figure ci-dessous illustre ces définitions.
En faisant varier le seuil γ, les valeurs TPR(γ) (égale à 1–FNR(γ)) et FPR(γ), reportées respectivement sur l’axe vertical et sur l’axe horizontal, tracent une courbe qu’on appelle la courbe ROC. Un détecteur idéal correspondrait à une courbe ROC formant un angle droit dans le coin supérieur gauche de la figure et dans ce cas la superficie AUC sous cette courbe vaudrait 1. Un détecteur qui ferait des prédictions au hasard décrirait lui la droite en pointillé et aurait un AUC égal à ½. Un détecteur avec un AUC plus grand que 0.9 peut être considéré comme satisfaisant.
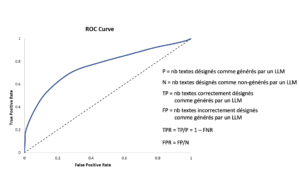
La courbe ROC exhibe donc le compromis n°1, élémentaire et incontournable, entre les erreurs de type I et II. Ce compromis n’est cependant en rien spécifique à la détection de textes rédigés par un LLM !
Pour formuler d’autres compromis, on fait l’hypothèse que les textes générés par un LLM et par un humain le sont selon deux lois de probabilités distinctes. Notons les M et H respectivement. Si γ désigne le seuil de détection alors TPR(γ) est la probabilité pour que le signal z excède γ lorsque les phrases sont échantillonnées selon M et FPR(γ) est la probabilité pour que le signal z excède γ lorsque les phrases sont échantillonnées selon H. Il est clair intuitivement que si les distribution M et H sont proches, autrement dit si le LLM génère des phrases semblables à celles que rédigent les humains, alors la détection sera difficile, voire impossible.
Reste encore à préciser comment on choisit de mesurer cet écart entre les distributions M et H. Une métrique classique en théorie des probabilités est la distance en variation totale, notons la VT. Intuitivement, c’est la somme, sur toutes les textes s possibles, des différences des scores |L(s) – H(s)| attribués par les deux distributions. Récemment, les auteurs de l’article [8] ont montré à l’aide d’un calcul élémentaire que AUC < ½ + VT. Comme on le constate, si la distance VT est très faible, l’AUC sera proche de ½ et par conséquent la qualité du prédicteur n’excèdera pas celle d’un prédicteur qui procèderait au hasard !
C’est le compromis n°2 qui est intuitivement presqu’évident s’énonce alors ainsi :
Si un LLM génère des textes proches de ceux rédigés par les humains, au sens où la VT entre H et M est très faible, alors ces textes seront indétectables en pratique.
Une fois encore, ce compromis n’est en rien spécifique à la détection de textes rédigés par un LLM. C’est un compromis bien connu des statisticiens et qui s’applique chaque fois que l’on souhaite distinguer deux types d’évènements (associés à des lois de probabilités différentes) à l’aide d’un seuil de détection.
Les auteurs de [8] en déduisent encore deux autres du même acabit :
Le compromis n°3 est formulé dans le cadre d’une attaque qui cherche à effacer un filigrane :
Si un attaquant dispose d’un modèle de paraphrases qui génère des phrases proches de celles qu’écrivent les humains (au sens de la VT) alors, soit l’on accepte que certains textes humains soient faussement attribués à un LLM (erreur de type I), soit le filigrane peut être effacé.
Le compromis n°4 est formulé dans un cadre général de la détection de textes rédigés par LLM. C’est en fait une reformulation précise du compromis n°1 :
Si le LLM génère des textes proches (au sens VT) de ceux des humains alors, soit certains textes humains seront faussement attribués à un LLM, soit certains textes générés par un LLM ne seront pas détectés (erreur de type II).
Ces compris sont tous des conséquences directes du résultat théorique AUC < ½ + VT. Ce résultat doit il nous surprendre ? Non assurément ! La formule précédente est jolie, certes, mais elle n’implique rien que le bon sens ne puisse anticiper. Par ailleurs, elle présuppose que la distance VT est effectivement pertinente pour la question qui nous intéresse. Or rien n’est moins sûr. Il est en effet envisageable qu’un texte rédigé par un LLM et doté d’une empreinte puisse être détectable, grâce à une distance VT importante entre M et H, mais sans que cela ne se traduise par une perte de la fluidité ou par une altération perceptible du sens des textes générés par M.
En linguistique computationnelle on utilise couramment une autre métrique, la perplexité [9], pour évaluer la qualité d’un texte généré par un modèle de langue LM. Intuitivement, cette perplexité est la moyenne du degré de surprise (= inverse de la probabilité¹) avec lequel apparaissent les mots produits par LM. Plus la perplexité est faible, moindre sera la surprise et donc meilleure sera la qualité perçue du texte. La perplexité est une métrique plus pertinente que la VT car c’est un estimateur de la qualité subjective d’un texte.
On peut alors exprimer le compromis n°5 qui s’applique à tous les principes de détection mentionnés précédemment :
Paraphraser un texte généré par un LLM diminue ses chances d’être détecté mais cela se paie par une augmentation de sa perplexité et donc par une diminution de sa fluidité.
La figure ci-dessous illustre ce compromis.
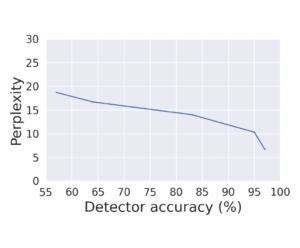
On considère généralement qu’une augmentation de 3 points de perplexité correspond à une diminution perceptible de la qualité du texte. La figure précédente illustre comment la perplexité du modèle OPT-1.3B, un LLM récent basé sur un Transformer avec 1.3 milliards de paramètres, diminue à mesure qu’augmente la proportion de texte paraphrasé à l’aide d’un modèle PEGASUS, un LLM avec seulement 220 millions de paramètres. Pour faire chuter la précision de 97% à 80% il faudra que l’attaquant consente à perdre 3.5 points de perplexité du texte paraphrasé.
Si l’on estime qu’un détecteur avec une précision de 80% est inutile et qu’une perte qualité de 3.5 points de perplexité reste essentiellement indétectable pour des humains, alors on peut affirmer que la technique de filigrane a été prise en défaut. Cependant, lorsqu’on regarde de près les exemples donnés dans [8] (table 2, page 5 et table 3, page 6), on s’aperçoit que la reformulation engendre parfois des répétitions ou des fautes d’orthographe qui éveilleront probablement les soupçons d’un humain vigilant.
Remarquons enfin que le LLM utilisé pour réaliser une attaque par paraphrases, même s’il est plus petit d’un facteur 2 ou 5 que le LLM cible, devra être tellement gros pour attaquer des modèles comme GPT-3 ou 4 que ce genre d’attaque ne sera pas à la portée du premier venu.
D’autres garde-fous ?
A ce stade, il semble par conséquent difficile de formuler une conclusion définitive quant à la protection qu’offrent les trois approches de détection évoquées. Peut-on imaginer qu’un très gros LLM comme GPT-4, LLAMA ou Bloom fine-tuné comme classifieur de textes IA/humain puisse être performant ? A ce stade la question est sans réponse claire, mais il y a fort à parier qu’au vu de la taille de ces modèles et du coût d’entraînement qu’ils impliquent ceux-ci devraient être mis en ligne par les concepteurs de LLM.
Sans doute serait-il sage de ne pas miser d’espoirs inconsidérés sur les détecteurs qui utilisent des méthodes statistiques.
Mais alors, hormis cette approche par détection de patterns, quelles autres pistes peut-on envisager ? Pour commencer, il y a sans doute une mission d’information à mener à l’échelle de toute la population sur les risques inhérents à l’IA générative, au-delà des seuls LLM. Pour les plus jeunes, promouvoir leur esprit critique, les inviter à la vigilance à l’aide d’exemples de textes crédibles mais factuellement faux produits par des LLM est de la première importance.
Sur le plan juridique il semblerait judicieux d’élaborer rapidement une règlementation qui exige de désigner sans ambiguïté comme tel tout texte produit par un LLM.
De manière complémentaire, il serait souhaitable de disposer d’un mécanisme universel de certification permettant d’attester qu’un texte qui revêt une importance particulière a bien été rédigé par une autorité reconnue. Cela pourrait être le cas par exemple d’un avis émis par une organisme médical concernant l’efficacité ou de l’innocuité d’un vaccin. A l’instar du petit cadenas affiché devant l’URL dans les navigateurs web, on peut imaginer ici un badge qui permettrait d’avoir l’assurance que tout ou une partie d’un texte émane effectivement d’une telle autorité. Pour garantir l’intégrité d’un texte, on pourra utiliser la technique des fonctions de hachage. Pour certifier l’origine d’un texte, on pourra faire appel aux outils de signature à base de chiffrement asymétrique (p.ex. RSA) qui permettent à une autorité de certification reconnue d’attester de la provenance d’un texte. Ces garanties peuvent être portées par une blockchain qui en assurera l’immuabilité. C’est par exemple ce que proposent les solutions Safe.press d’Orange ou ANSAcheck en Italie ². Bien que ces solutions n’aient visiblement pas encore trouvé l’écho qu’elles méritent dans le contexte actuel, elles pourraient offrir des solutions éprouvées pour garantir les sources d’articles de presse et pour lutter contre les fake news.
Pour le texte que vous venez de lire aussi patiemment, je ne peux que solliciter pour l’instant votre confiance lorsque je vous assure qu’il n’a pas été rédigé par ChatGPT.
Remerciements
² Merci à Vincent Rémon, notre expert cybersécurité chez onepoint, pour ses précieuses lumières sur ce sujet !
Références
- Pause Giant AI Experiments: An Open Letter.
- Language Models are Unsupervised Multitask Learners (GPT-2)
- Language Models are Few-Shot Learners (GPT-3)
- Sparks of Artificial General Intelligence: Early experiments with GPT-4
- Automatic Detection of Machine Generated Text: A Critical Survey
- DetectGPT: Zero-Shot Machine-Generated Text Detection using Probability Curvature
- A Watermark for Large Language Models
- Can AI-Generated Text be Reliably Detected?
- Perplexity of language models revisited
- ANSA Check
- Orange safe.press
¹ Cette probabilité est évaluée à l’aide d’un LLM plus gros, ici OPT-2.7B, qu’OPT-1.3B qui génère le texte original.
