Avant de continuer, qu’est-ce que le Edge Computing ?
Le Edge Computing peut être considéré comme un réseau de mini Data Centers (entre un serveur et moins d’une dizaine d’instances, généralement 2 ou 4 machines), qui stockent et traitent les données au plus près des infrastructures où les capteurs sont déployés.
Il est le plus souvent utilisé dans l’univers de l’IoT où la connectivité est faible et la latence importante. Les flux de données remontés par les capteurs sont traités localement, afin de réduire le trafic en direction des serveurs centraux (Data Centers et/ou Cloud) et ainsi permettre une analyse des données importantes et une réaction proche du temps réel.
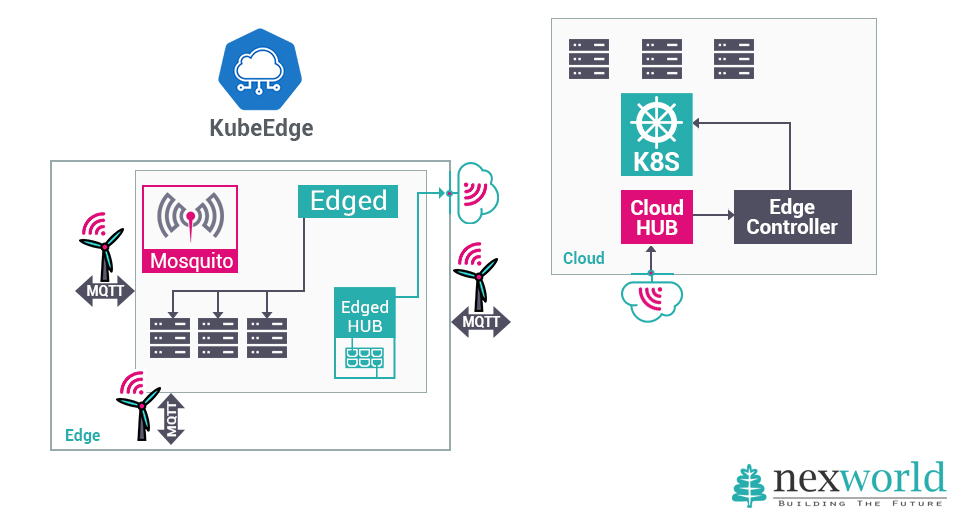
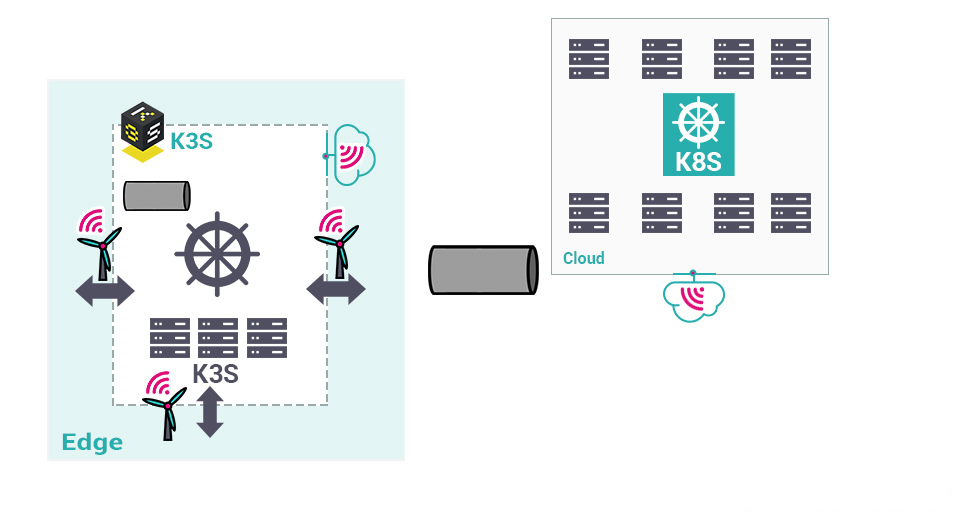
A l’instar des Data Centers et du Cloud avec Kubernetes (sur Kubernetes, lire l’article Transformez votre architecture applicative avec Kubernetes), le Edge Computing doit répondre aux besoins d’automatisation, d’industrialisation, de standardisation, de fiabilisation et de sécurisation. Des distributions de Kubernetes dédiées au Edge sont apparues début 2019, telle KubeEdge et K3s.
Contrairement à un Data Center où provisionner les ressources nécessaires au bon fonctionnement de Kubernetes est relativement aisé, les ressources Edge sont en quantité finie et limitée. Déployer des serveurs nombreux et performants dans des champs ou en lisière d’autoroutes n’est pas quelque chose d’aisée !