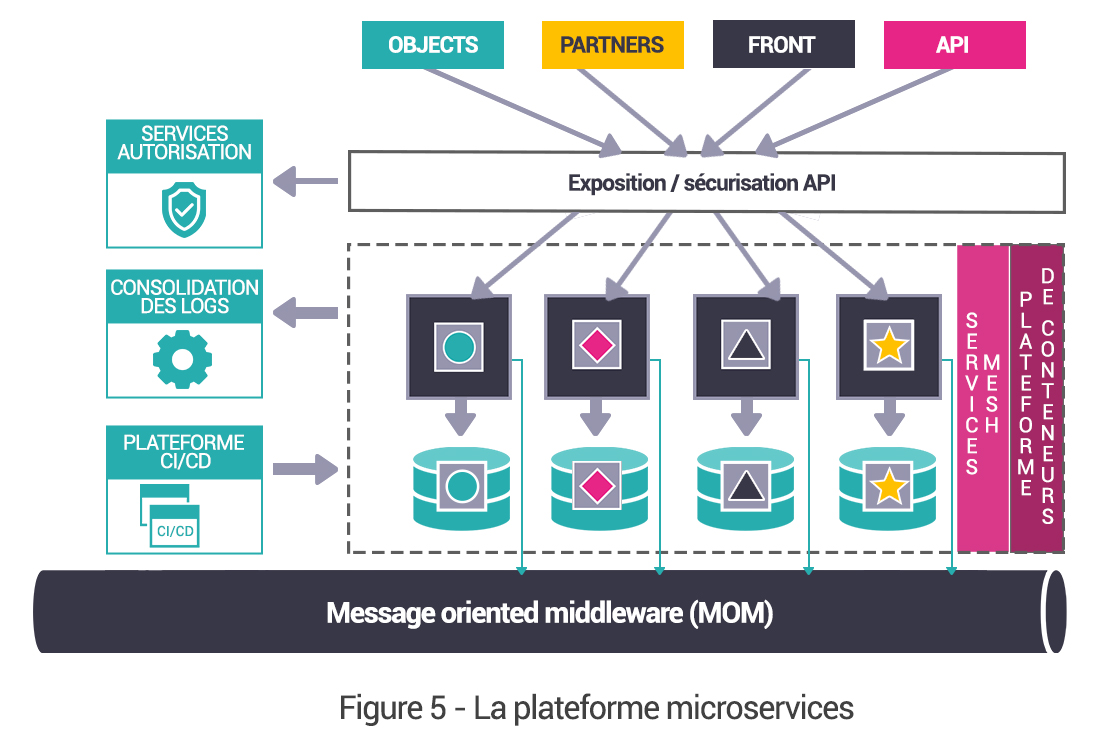
La version courte
Pour définir le concept en une phrase, on peut dire que c’est un modèle d’Architecture permettant de garantir qualité, scalabilité et Agilité du SI en isolant des domaines « fonctionnels » et en les rendant autonomes.
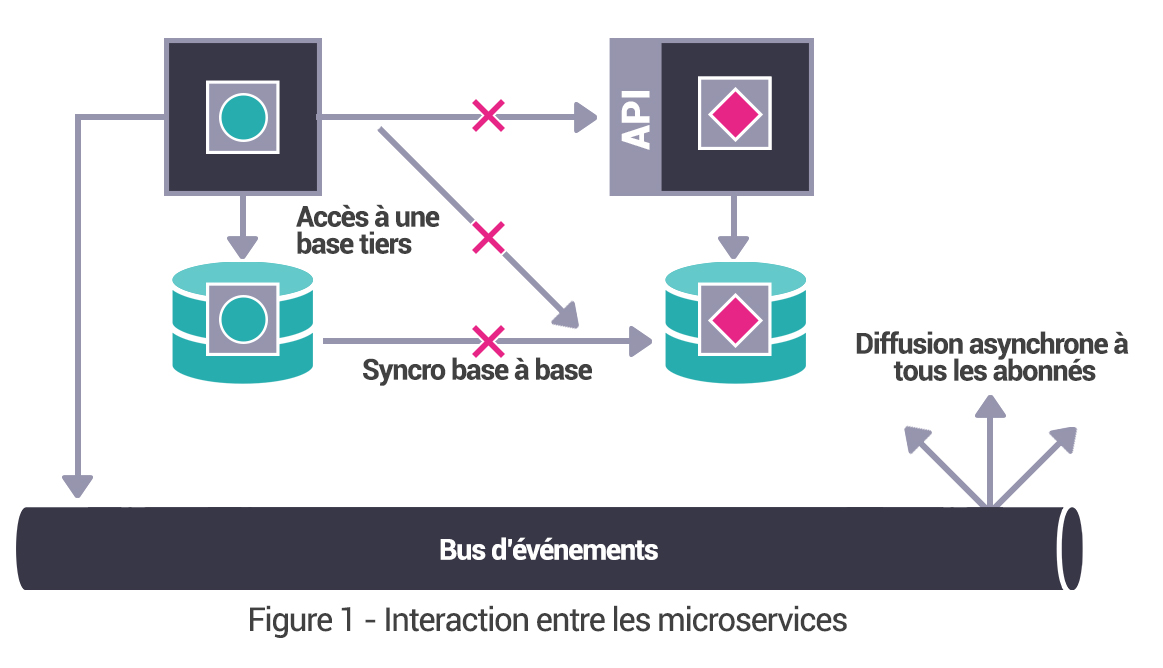
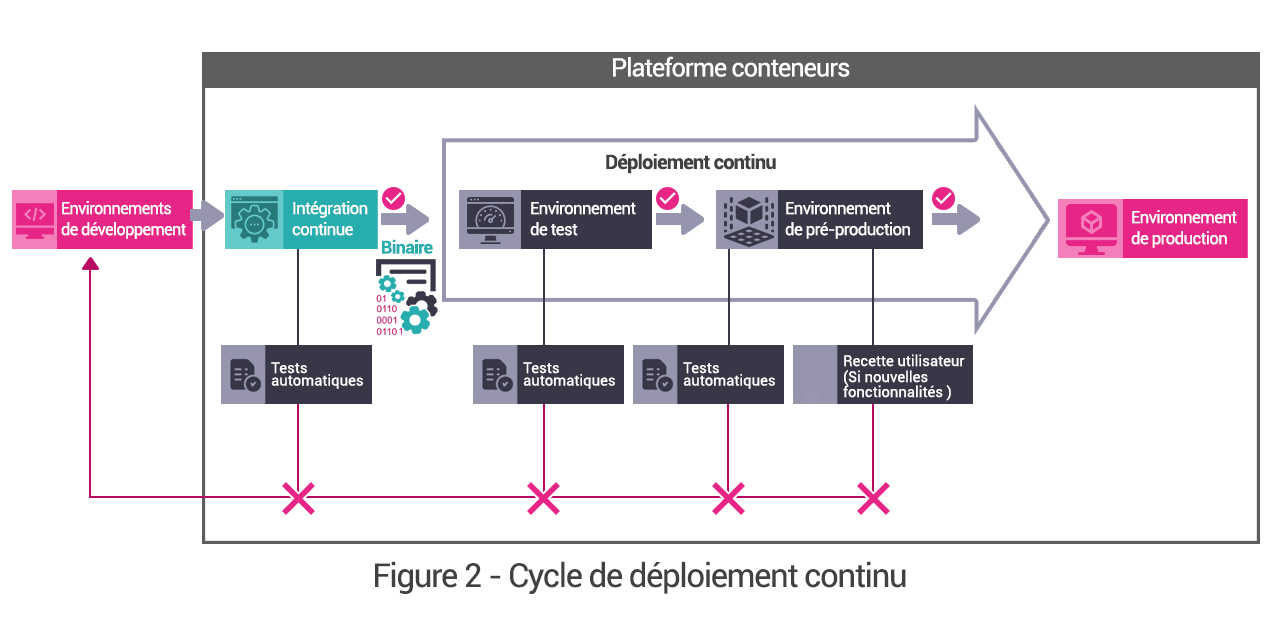
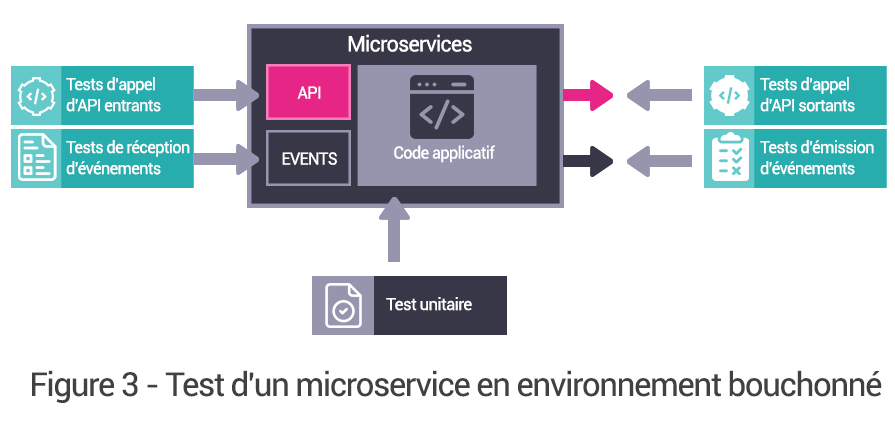
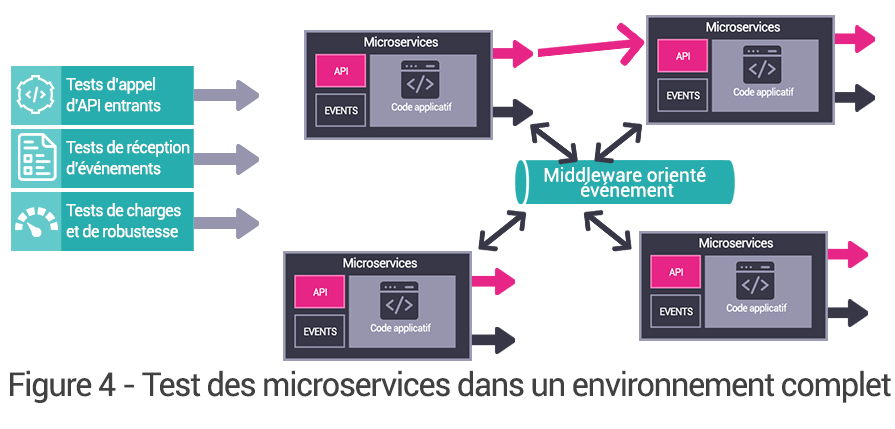
À travers cette définition, on retrouve, de manière transverse, deux sujets connexes aux micro services, qui sont les environnements conteneurisés et la méthodologie de mise en œuvre DevOps. Automatisation, tests et qualités sont en effet les maîtres mots d’une Architecture micro services pérenne.
Dans quels cas mettre en œuvre des microservices ? Pour quels résultats ?
L’apport couramment constaté lors de la mise en œuvre d’une Architecture micro services est le gain en termes de time to delivery. Sur le principe du « diviser pour mieux régner », l’évolution d’un micro service nécessite un effort moindre. Des services applicatifs autonomes et de taille réduite sont naturellement plus simples à prendre en main pour les développeurs, plus simples à faire évoluer techniquement, et plus facile à tester.
Autre élément important : qui dit service plus petit et plus simple, dit amélioration des temps de démarrage et donc des possibilités de scalabilité automatique.
Avec des services plus évolutifs et s’adaptant mieux à la charge, l’Architecture micro services est surtout bénéfique aux services à haute valeur concurrentielle et à ceux recevant le plus de charge de travail, qui sont bien souvent les mêmes.