Même si les phases d’expérimentation se multiplient et sont de plus en plus éprouvées dans les entreprises, la pérennisation de services basés sur du Machine Learning est un processus beaucoup moins maîtrisé. Nous développons dans cet article comment MLOps permet de fiabiliser les traitements de Machine Learning pour assurer aux entreprises des bénéfices sur le long terme.
Qu’est-ce que MLOps ?
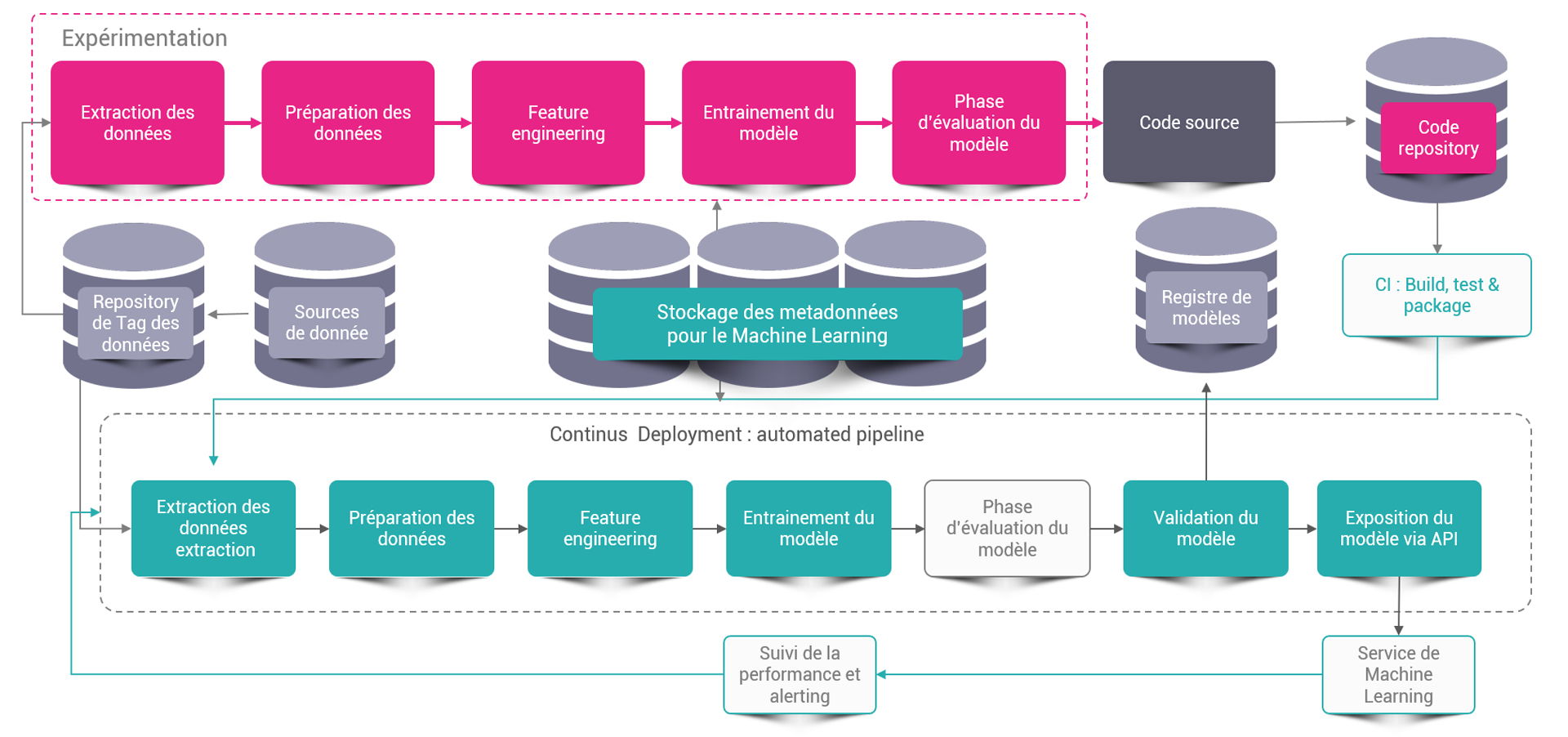
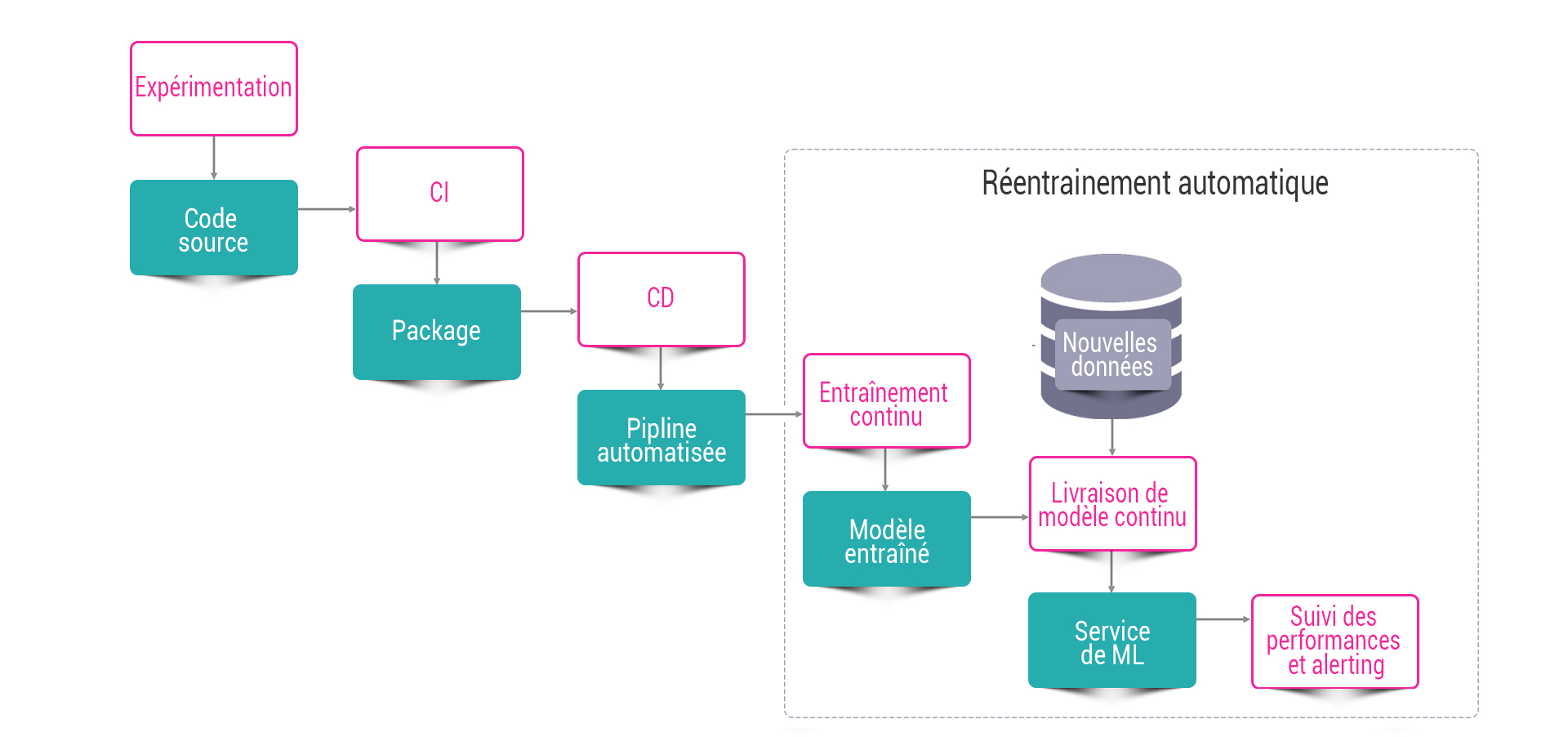
MLOps est une pratique de collaboration et de communication entre les Data Scientists et les opérations destinée à fiabiliser le cycle de vie des services de Machine Learning. Similaire aux approches DevOps ou DataOps, MLOps vise à augmenter l’automatisation et à améliorer la qualité de la mise en production du Machine Learning.
Pourquoi les modèles de Machine Learning ne restent-ils pas fiables éternellement ?
Les modèles de Machine Learning apprennent et son mis au point à partir de jeux de données or si ces derniers ne sont pas ou plus représentatifs de l’information cible à prédire, alors le modèle n’est plus performant. On parle dans ce cas, de dérive des modèles.
Imaginons, par exemple, qu’une entreprise souhaite prédire les départs à la retraite de ses employés. Pour atteindre cet objectif, elle entraine un modèle de Machine Learning en se basant sur les données des 5 dernières années. Une fois le modèle développé, l’entreprise observe qu’il prédit un âge moyen de départ autour de 62 ans.
L’année suivante, l’état Français vote une loi, à effet immédiat, stipulant que toutes les personnes partant à la retraite avant 65 ans ne toucheront plus un taux compris entre 37,5 et 50 % de leur salaire initial mais un taux fixe à 40 %.
Cet événement a de fortes chances de fausser les prédictions du modèle, les personnes proches de 65 ans décidant alors de ne pas partir à la retraite l’année d’entrée en vigueur de la loi, s’estimant désavantagées par le nouveau taux calculé.
Pourquoi faut-il automatiser et systématiser l’entrainement de vos modèles ?
Dans l’exemple précédent, nous avons parlé d’un événement externe impactant les prédictions sur les données sur plusieurs années. Dans d’autres contextes, comme la personnalisation de produits ou encore la détection de fraude, les caractéristiques des données cibles à prédire peuvent évoluer beaucoup plus rapidement (mois, jours, voire heure).
Il est donc essentiel de réentraîner régulièrement les modèles sur des données intégrant les nouvelles caractéristiques afin de maximiser leur performance et d’assurer de leur véracité dans le temps.
MLOps : La réponse aux besoins de déploiement et de réentrainement du Machine Learning.
MLOps peut être défini comme une extension de DevOps pour le Machine Learning. Cependant, même si l’on y retrouve les grands principes de DevOps, MLOps apporte un axe de réflexion supplémentaire relatif aux données et métadonnées du Machine Learning.