Le Graal : disposer d’une vue unifiée des données
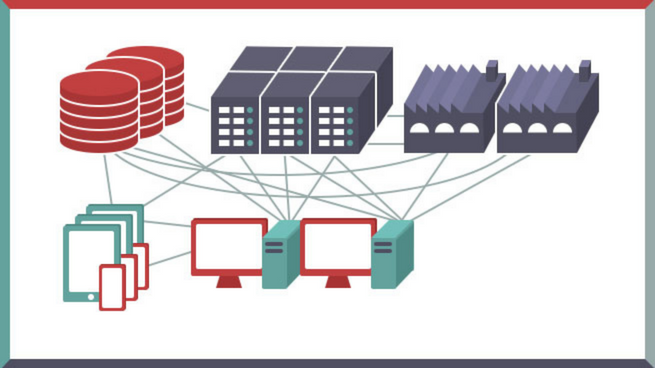
Bien souvent les entreprises disposent d’une grande quantité de données mais ne savent pas comment les exploiter efficacement.
Et pour cause : les données sont dispersées dans le SI, suivant une répartition en silos. Autrement dit, des données provenant de divisions et d’outils distincts sont stockées et traitées distinctement sans communication entre chaque silo. Résultat, les données sont également analysées indépendamment de façon décorrélée les unes des autres. Il est alors difficile de détecter des événements survenant de manière globale. Et même si l’on dispose d’une visualisation unifiée des données de son SI, aucun outil ne permet de mettre automatiquement en évidence des événements corrélés.
En outre, l’émergence des données non structurées apporte un nouveau challenge d’un point de vue analytique. Les outils d’analyse doivent être capables de lire ces dernières et de pouvoir en extraire le contenu de façon automatique.
Il est donc primordial d’avoir une vision unifiée et intelligente de ses données, pour les analyser efficacement et générer de la valeur. Les outils tels que Splunk et la Suite Elastic (anciennement ELK) répondent à ces problématiques.
Comment Splunk et la suite Elastic valorisent
vos données ?
Splunk et la Suite Elastic proposent principalement une réponse aux mêmes besoins, et peuvent donc être considérés comme des concurrents (même s’ils fonctionnent différemment, et que Splunk se veut plus complet).
Leur but premier est de transformer les données (notamment les logs de tous types) pour apporter une visibilité en temps réel et produire de l’intelligence opérationnelle. Avec, à la clé, un large panel d’usages.
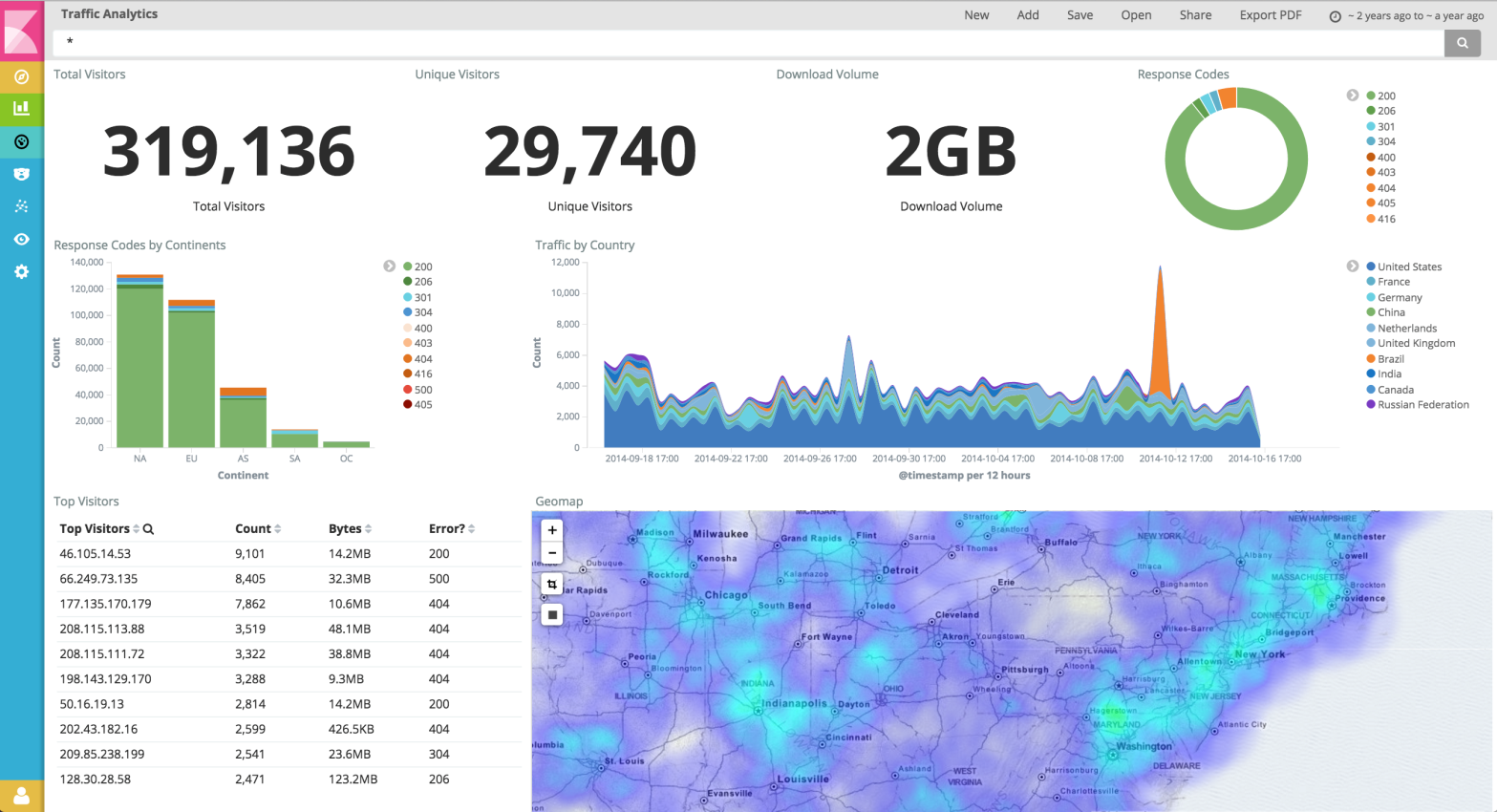
Leurs fonctionnalités de base permettent de collecter les données (depuis de nombreux types de source), de les stocker de façon centralisée, de les analyser et de restituer visuellement ces informations en temps réel sous forme de dashboards personnalisables.
Les deux solutions s’accompagnent évidemment de nombreuses fonctionnalités supplémentaires (sécurité, alerting, monitoring, enrichissement des données, Machine Learning, etc…).
Suite Elastic, une solution très modulaire
La Suite Elastic se caractérise, comme son nom l’indique, par sa conception modulaire. Elle propose l’utilisation conjointe et complémentaire de 4 outils partageant le même éditeur (Elastic) :
- Beats,
- Logstash,
- Elasticsearch,
- Kibana
Ces 4 solutions sont open source et gratuites.
A noter que chaque outil est autonome dans sa fonction et peut être utilisé indépendamment des autres. Il est donc possible selon ses besoins de se passer d’un élément de la Suite ou de le remplacer par un autre outil de son choix.
Beats est un agent installé sur chaque machine, qui collecte localement les données et les transfère à Logstash. Il offre des fonctions inhérentes au transfert de données comme le load balancing, le transfert par lots, de façon synchrone/asynchrone, etc.
Logstash prend en charge le formatage et l’enrichissement des données. Il peut être considéré comme un ETL (Extract Transform Load). Il reçoit des données de sources variées envoyées par Beats, y applique diverses transformations, et les transfère à Elasticsearch. Ces transformations peuvent être par exemple un parsing de données pour identifier leur contenu (détection des dates, adresses IP, ports, URLs etc.), une localisation géographique à partir d’une IP, l’anonymisation d’une partie des données, une standardisation du format, etc… Logstash étant open source, il est possible de développer ses propres filtres – de fait, ses possibilités sont en constante évolution.
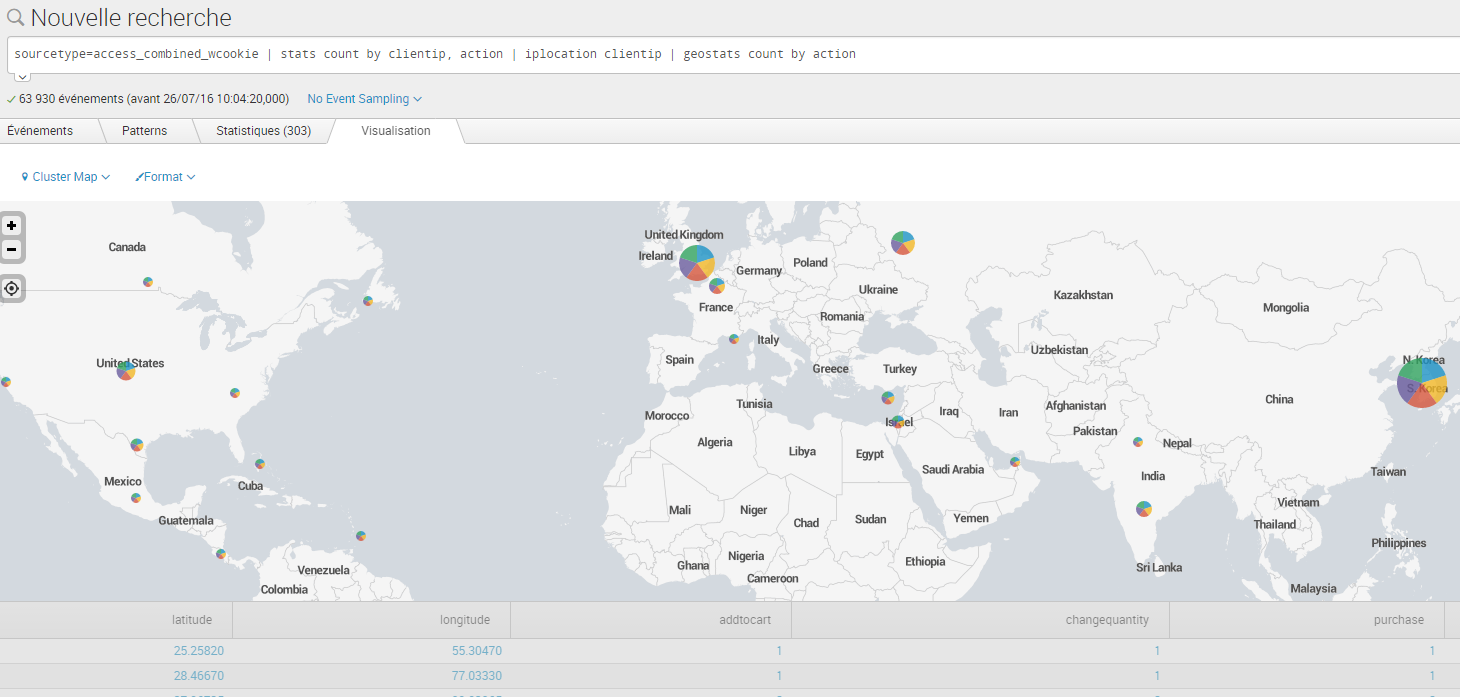
Elasticsearch constitue le cœur de la Suite Elastic. C’est un moteur de recherche et d’analyse distribuée, qui stocke les données de manière centralisée. Basé sur la bibliothèque Apache Lucene, et utilisant une base de données orientée documents, Elasticsearch peut effectuer des recherches sur des données structurées ou non-structurées, explorer des tendances, identifier des modèles dans les données, le tout en temps réel (de l’ordre de la seconde). Les interactions avec Elasticsearch se font via des API REST, et Elastic adresse ses clients dans divers langages. Il est également possible de l’interfacer avec Hadoop (stockage sur Hadoop et recherche avec Elasticsearch).
Kibana est l’interface graphique permettant de visualiser les données stockées et analysées par Elasticsearch. L’interface est user-friendly et les divers graphiques sont présentés sous forme de dashboards personnalisables.
Enfin, Elastic propose un pack d’extension sous le nom d’X-Pack qui apporte un certain nombre de fonctionnalités (dont certaines peuvent être considérées comme essentielles) sous la forme d’outils. Il en existe 6 actuellement : sécurité, monitoring, alerting, reporting, analyse orientée graphes et Machine Learning. Contrairement au reste de la Suite Elastic, ces extensions sont payantes, de même que le support.
Splunk : des agents, un index et des solutions Premium
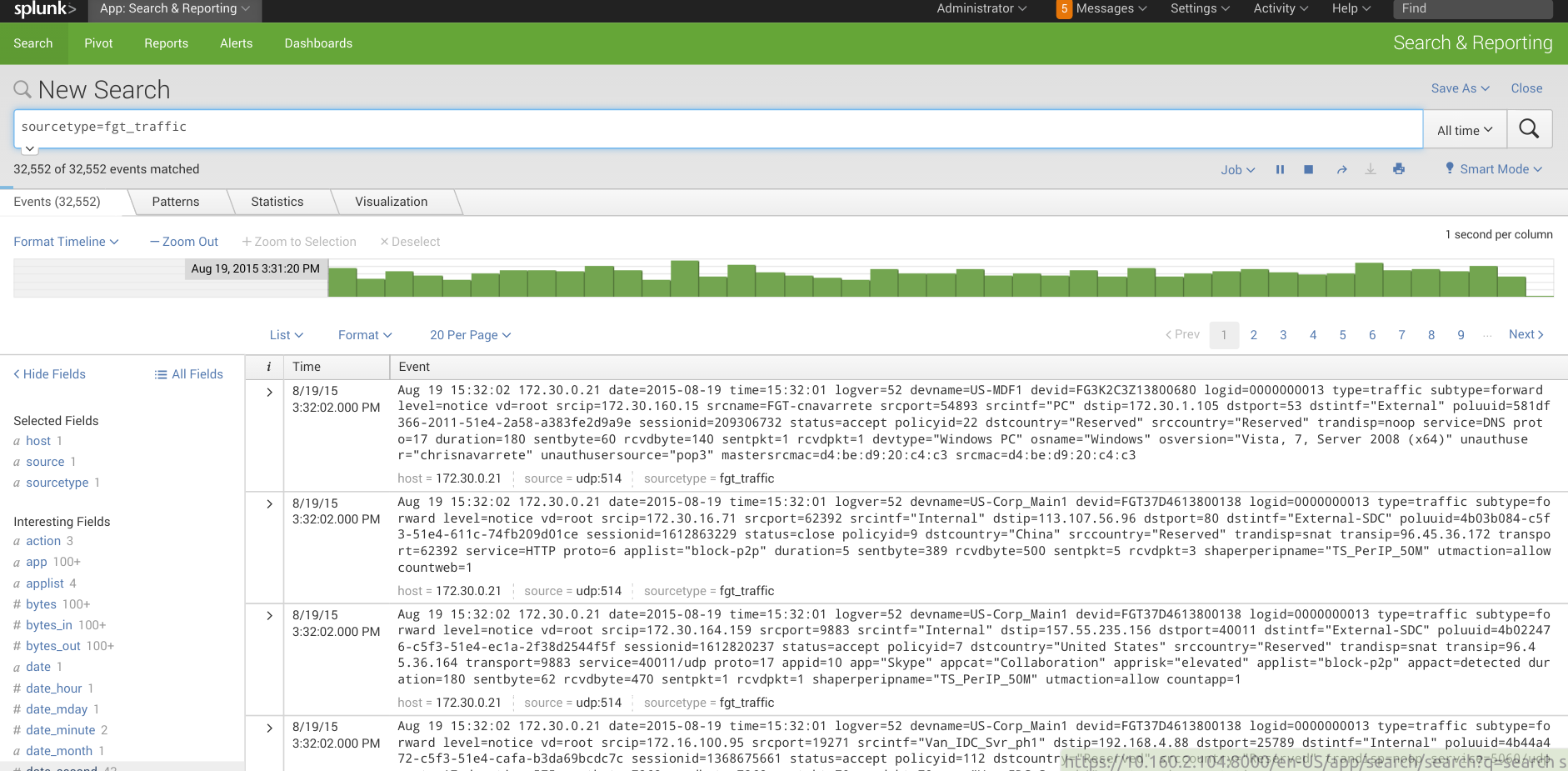
Splunk, au même titre que la suite Elastic, utilise des agents légers installés sur chaque machine, qui transmettent les données pour les stocker dans un index central. Index dans lequel les données, qui peuvent être structurées ou non structurées, pourront être recherchées rapidement. A noter que Splunk est une solution tout-en-un, et non une association de plusieurs briques indépendantes et autonomes comme c’est le cas pour la suite Elastic (la version SaaS est donc fonctionnelle immédiatement avec un minimum de paramétrage. Il est possible de l’essayer gratuitement).
Mais Splunk ne se limite plus à un simple outil d’exploration des logs, comme il l’était à ses débuts. Il permet de corréler les données, de détecter automatiquement des patterns, et associe ces mécanismes à des fonctionnalités de Machine Learning. En découlent des capacités d’apprentissage, de déduction et de prédiction. Splunk procure de quoi de détecter des tendances, prédire une défaillance future, envoyer des alertes de manière anticipée…
En plus de ses fonctionnalités natives, Splunk fonctionne sur un modèle d’Apps (en quelque sorte, des templates préconfigurés spécifiquement pour un besoin) et d’add-ons. Ces Apps et add-ons peuvent être développés par Splunk, les partenaires, ainsi que par la communauté.
Enfin, Splunk propose trois Solutions Premium, payantes. Elles apportent des fonctionnalités beaucoup plus avancées, notamment dans le domaine de la sécurité (comme de l’analyse de comportement) :
- Splunk IT Service Intelligence: Monitoring avancé (avec Machine Learning et analyse d’événements)
- Splunk Enterprise Security: SIEM (Security Information and Event Management) pour détecter les attaques externes/internes. SIEM fournit des informations en temps réel sur les réseaux, les terminaux, les accès, les logiciels malveillants, les vulnérabilités et les identités.
- Splunk User Behavior Analytics (UBA): Basé sur Hadoop et l’utilisation du Machine Learning, il détecte des menaces internes par modélisation du comportement, analyse de groupes de pairs, corrélations, etc.
Splunk a obtenu plusieurs certifications, comme la certification Common Criteria (ISO 15408) qui atteste d’un très haut niveau de sécurité – la solution est d’ailleurs utilisée par des agences gouvernementales telles que la NSA.
Le tout est proposé au travers d’une interface user-friendly accessible depuis un navigateur web. Il faut cependant noter que les recherches sur les données se font à l’aide d’un langage propriétaire, le Splunk Search Processing Language (SPL).
« Tout-en-un » versus « Do It Yourself »
Il faut donc bien comprendre qu’il n’y a pas une solution meilleure que l’autre, dans l’absolu. Les solutions sont toutes deux viables et populaires dans le contexte actuel, et disposent l’une comme l’autre d’une bonne communauté. Chacune, de par ses spécificités, saura répondre à des besoins différents.
Par exemple, la Suite Elastic est accessible gratuitement, mais va mobiliser davantage de ressources pour son installation, sa configuration et son utilisation, en raison de son approche « do-it-yourself ». Alors que Splunk, au contraire, impose un prix d’entrée élevé, mais constitue une solution tout-en-un complète et mature qui sera prête rapidement et accessible à des profils moins techniques. Tout dépend donc de la complexité des besoins et des ressources humaines ou financières qu’on souhaite allouer.
Il faut donc avant tout bien qualifier ses besoins et contraintes, afin de choisir la solution la plus adaptée. Rien ne sert d’adopter une solution surpuissante pour répondre à un cas d’usage simple.