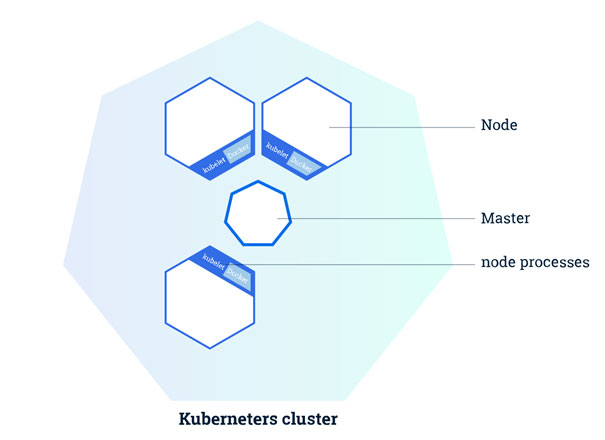
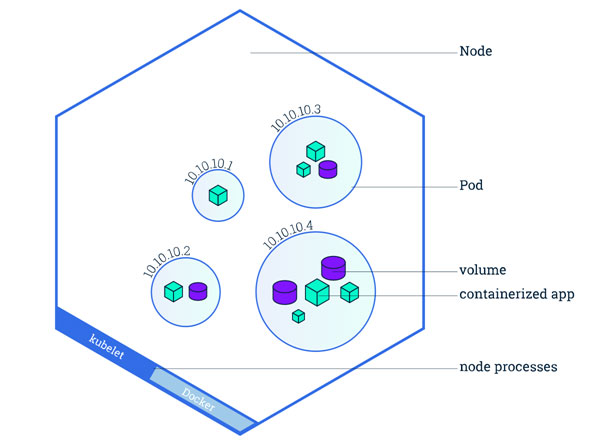
Pour résumer, les pods s’exécutent toujours sur des nœuds. Un nœud (« node ») est une unité de travail dans Kubernetes pouvant être assimilée à une VM ou une machine physique. Chaque nœud exécute des pods et est géré par le nœud maître (« Master »). Il peut y avoir plusieurs pods dans un même nœud. L’ordonnancement des nœuds (le fait d’ordonner des tâches à exécuter aux nœuds selon certaines contraintes) est effectué de manière automatique par le master en fonction des ressources disponibles sur les nœuds.
Chaque nœud exécute au minimum :
- Un conteneur d’exécution (Docker), qui permettra de récupérer l’ensemble des conteneurs à déployer depuis un registre
- Kubelet, un agent qui servira de pont entre le master et l’ensemble des nodes du cluster. Il gère l’état des pods (et des conteneurs) exécutés sur une machine
Une Architecture Applicative fiable permise grâce à la réplication
Pourquoi répliquer nos applications ?
Avant de nous intéresser au fonctionnement de la réplication dans Kubernetes, rappelons brièvement pourquoi répliquer nos conteneurs.
3 bénéfices principaux peuvent être rendus :
- Une meilleure fiabilité : en dupliquant n fois notre application, on peut anticiper les problèmes (et les pannes de service) si l’une d’entre elles venait à échouer
- Du Load-Balancing : posséder plusieurs répliques d’une même application permet d’envoyer du trafic aux différentes instances, au lieu de surcharger une seule et même instance ou nœud. C’est une des fonctionnalités majeures proposée par Kubernetes
- Le redimensionnement : Quand la charge devient trop importante pour le nombre de répliques existantes, Kubernetes permet d’effectuer la mise à échelle automatique sur l’application en ajoutant autant d’instances supplémentaires que nécessaire
Les types de réplication proposées par Kubernetes :
« Replication Controller »
Le Replication Controller correspond à la méthode originale de réplication dans Kubernetes. C’est une structure permettant de créer aisément plusieurs répliques d’un même pod, et qui s’assure que ce nombre de répliques en exécution soit toujours cohérent. Si l’on veut créer n répliques (n pouvant être variable), le Replication Controller redémarrera ou détruira des conteneurs afin qu’il y ait toujours n répliques opérationnelles du pod.
Si un pod venait à être détruit, le Replication Controller le remplace immédiatement. Il permet également d’effectuer la mise à échelle automatique sur les pods, la mise à jour ou encore des suppressions de pods.
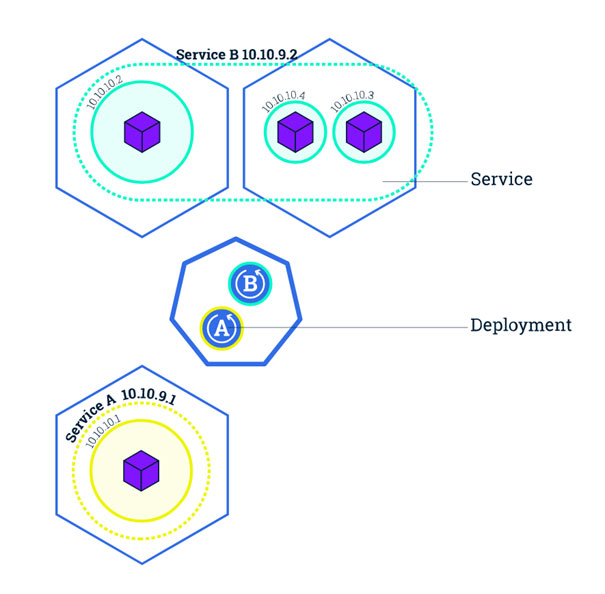
« Replica Set » et « deployments »
Le Replica Set est la « nouvelle génération » de la réplication dans Kubernetes. Ils permettent les mêmes fonctionnalités de réplications que les Replication Controllers, en plus d’être dotés d’un nouveau type de « selector » (élément permettant de cibler le(s) pod(s) à répliquer). Il ne disposent cependant pas de fonctionnalités de mise à jour ou de suppression.
Ce sont les « deployments », qui définissent les Replica Set, et qui permettent l’ensemble des actions de mise à jour, de « roll back » (retour arrière lors de mauvaises manipulations) et de suppression.
Cette séparation entre les Replica Set et les deployments permet d’introduire une plus grande flexibilité au niveau de la gestion de la réplication. On préconisera donc cette démarche.
Exposition d’applications avec les services
Même si les pods ont leur propre adresse IP à travers le cluster, ces IP ne sont pas exposées à l’extérieur de Kubernetes. En tenant compte du fait que les pods peuvent être détruits ou remplacés par d’autres pods, il faut pouvoir permettre à l’ensemble des pods (et des applications) de se découvrir automatiquement entre eux.
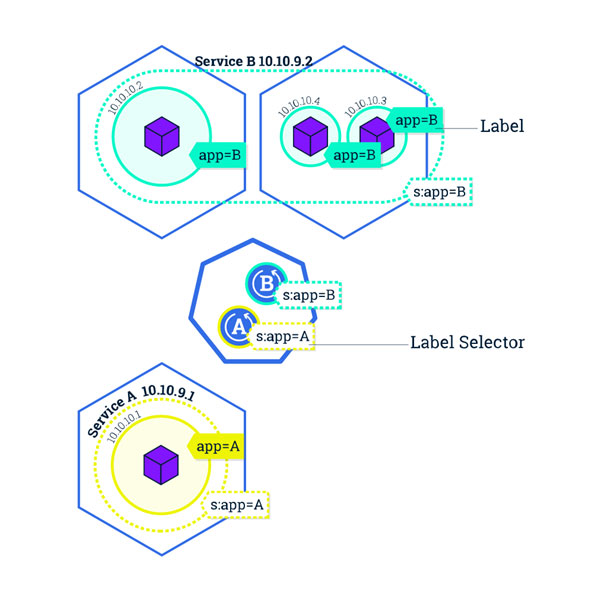
Kubernetes répond à cette problématique en regroupant les pods dans des « services ». Un service Kubernetes est une couche d’abstraction qui définit une collection logique de pods et permet leur exposition à un trafic externe, du load-balancing et de la découverte de service entre eux.
Chaque service a sa propre adresse IP (unique pour le cluster) et expose un ou plusieurs ports afin de recevoir du trafic.