Comment développer son Chatbot avec Rasa ? Première partie : concepts et overview
De nombreuses solutions permettant de développer des Chatbots sont disponibles, notamment celles des grands éditeurs comme IBM, Amazon, Microsoft ou encore Google. Nous nous intéresserons dans cet article à l’implémentation d’un challenger issu du monde open source : Rasa.
Mais Rasa, c’est quoi ?
Il s’agit d’une entreprise allemande fournissant une solution de Chatbot. Elle accompagne ses clients dans la mise en place d’une plateforme pour l’intégration de son agent conversationnel, notamment en fournissant des conteneurs Docker qui permettent de le déployer rapidement et de passer à l’échelle industrielle. Elle fournit également le support de sa solution pour résoudre les incidents, déployer sans délai avec une installation automatisée et notifier des prochaines mises à jour. La plateforme payante Rasa Platform est constituée des composants suivants :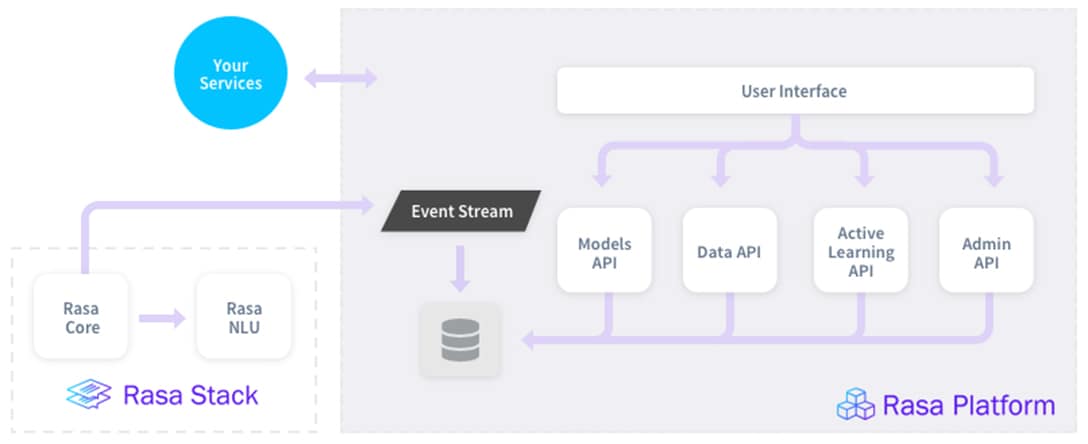
- Models API : cet outil permet de tester un nouveau modèle et de comprendre quand il échoue. Il permet aussi d’update ou rollback le modèle via l’interface d’administration ou via une API.
- Active Learning API : permet l’analyse des logs de tous les utilisateurs, l’aide au débogage et fournit des améliorations du modèle grâce à la suggestion de dialogue. Il est aussi possible de tester le Chatbot dans l’interface d’administration.
- Data API : cet outil de Data Versioning permet de contrôler la qualité et l’accès aux données. Il assure par ailleurs l’intégrité du backend.
- Rasa NLU qui gère la partie compréhension du langage de l’agent ;
- Rasa CORE qui s’occupe de la partie stockage d’information, du choix de la réponse et de la connexion avec l’interface de discussion.
Les concepts du NLP
Le NLP (Natural Language Processing, ou « Traitement du Langage Naturel ») est une branche de l’informatique axée sur le développement de systèmes permettant aux ordinateurs de communiquer avec des personnes en utilisant le langage de tous les jours. Typiquement, ces systèmes peuvent répondre à des questions, extraire des informations, analyser des sentiments, traduire, analyser des contextes ou encore résumer des textes. Le système de conversation intelligent est le socle sur lequel est construit tout Chatbot. Il permet de comprendre les demandes des utilisateurs et de leur répondre de manière pertinente. Ce type de système est souvent construit au-dessus d’un algorithme de compréhension et de catégorisation. Focalisons-nous maintenant sur les différents éléments de traitement du langage : le NLG et le NLU.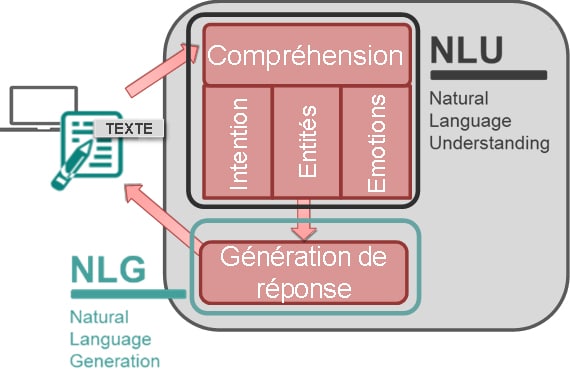
Le NLG (Natural Language Generation) permet l’écriture automatique de texte de qualité similaire à celui écrit par un humain à partir de données structurées. Nous n’entrerons pas plus dans les détails ici, car cette brique ne fait pas partie de la solution Rasa.
Le NLU (Natural Language Understanging) est la sous-entité du NLP axée sur la compréhension de phrases parlées ou écrites. Le système effectue un « mapping » de langage naturel en une représentation intention/entités, de la même façon qu’une classification. C’est une façon d’extraire de l’information d’un texte écrit.
Les intentions sont des classes d’énoncés qui correspondent souvent au verbe utilisé par l’utilisateur pour écrire l’action qu’il souhaite faire. Par exemple :
- « Je veux réserver un hôtel sur New York pour le prochain Noël » ==> l’intention ici est « réservation d’une chambre d’hôtel »
- « Peux-tu me divertir en me racontant une blague ? » ==> l’intention ici est « divertir »
- « Où en est ma demande de remboursement des lunettes de mon fils ? » ==> l’intention ici est « suivi de dossier »
- « New York”, « prochain Noël »
- « blague »
- « remboursement », « lunettes », « fils »
Déclinaison dans le framework Rasa
Les deux concepts « intention » et « entités » reliés à l’utilisateur sont présents dans Rasa sous leurs terminologies anglaises intent et entity. Il existe également des concepts propres à Rasa : les slots et les actions. Les slots agissent comme un dépôt de valeurs importantes, pouvant être utilisés pour stocker les informations fournies par l’utilisateur (par exemple, leur ville de résidence) ainsi que les informations recueillies sur le monde extérieur (par exemple, le résultat d’une requête de base de données). La plupart du temps, les slots ont une influence sur la progression de la discussion. Les actions permettent de remplir les slots et de choisir la réponse qui sera envoyée à l’utilisateur. Il en existe trois types :- Les actions par défaut : listen, restart et fallback, pour respectivement se mettre à l’écoute, redémarrer une conversation et ignorer le dernier message utilisateur.
- Les actions basiques : consistent à renvoyer un message à l’utilisateur uniquement à partir de l’intention.
- Les actions custom : permettent de faire des opérations assez complexes à partir de l’intention et des slots.
Les étapes clés de l’apprentissage
La première partie consiste à créer les modèles de NLU et de discussion, communément appelée la phase d’apprentissage (training en anglais). Rasa étant basé sur du Machine Learning, il a besoin de données d’apprentissage (ou d’entrainement).- Pour la partie NLU (Rasa-NLU), les données d’entraînement sont des phrases types que l’utilisateur pourrait énoncer et dans lesquelles l’intention ainsi que les entités sont précisées. Il faut également un fichier de configuration pour régler les paramètres des algorithmes.
- Pour la partie discussion (Rasa-CORE), il faut définir un ensemble de stories pour que l’agent apprenne à choisir sa prochaine action à effectuer. Le fichier de configuration accompagnant les stories contient les listes des intentions, des entités, des slots et des actions.
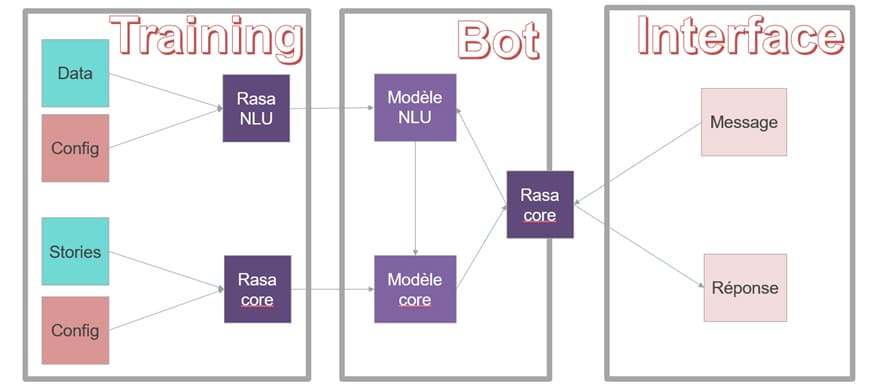
Une fois l’apprentissage terminé, l’agent conversationnel est constitué des deux modèles NLU et Core, ainsi que les connecteurs avec l’interface d’exposition des conversations. En effet, pour interagir avec Rasa, l’utilisateur doit passer par une interface telle que Facebook, Slack, Skype… A noter qu’il est possible d’interagir avec Rasa en local via les lignes de commande, bien pratiques lors des phases de développement et de debug.
Quand l’utilisateur envoie un message (1), Rasa le récupère grâce à un connecteur. Le message est traité par le modèle NLU (2) qui extrait l’intention et les entités du message. Le résultat est envoyé au modèle de discussion qui va effectuer des actions (3), comme par exemple de remplir des slots et choisir le message à renvoyer à l’utilisateur. La réponse est ensuite envoyée à l’utilisateur sur le canal d’origine (4).
Conclusion
Dans cet article, nous avons présenté les concepts liés à la création d’agents conversationnels de façon théorique, la partie Rasa NLU pour la compréhension du langage ainsi que Rasa CORE pour l’enchaînement des conversations. Nous irons plus en détails dans l’implémentation de Rasa dans : Comment développer son Chatbot avec Rasa ? Seconde partie : de l’entraînement au déploiementAuteur
-

onepoint
beyond the obvious














