Traces d’achats, commentaire en ligne, saisie de recherche, localisation… Nos actions quotidiennes laissent de nombreuses traces numériques. Celles-ci sont intégrées à d’immenses bases de données sur lesquelles sont entraînés des modèles de machine learning. Ces modèles ont des usages divers tels la personnalisation de l’expérience utilisateur, l’automatisation de tâches ou encore la prédiction de tendances.
L’utilité de ces modèles, intégrés dans des systèmes décisionnels souvent opaques, est de plus en plus évidente. Mais au-delà de ces bénéfices, ces modèles ont hérité de biais subtils présents dans les données qui ont servi à les entraîner. Ainsi ils peuvent produire des décisions perçues comme fausses, injustes, voire discriminatoires. Le préjudice peut être très important, en particulier lors de prises de décisions dans des domaines aussi sensibles que la santé ou la justice.
Dans ce contexte de prolifération de systèmes opaques grandit un besoin de transparence et de confiance. Le champ de l’explicabilité dans le domaine de l’IA (Explainable AI (XAI)) regroupe un ensemble d’approches visant à répondre à ces besoins en permettant une meilleure compréhension des processus décisionnels.
Expliquer les décisions n’est toutefois pas une tâche facile. Les systèmes opaques sont perçus comme des « boîtes noires » dont la structure interne est souvent dissimulée. On peut connaître partiellement les données qui leur sont présentées. On peut aussi observer partiellement les décisions qu’ils prennent. Mais leur logique interne, ce qui motive leurs décisions, est généralement inaccessible.
Les approches de l’explicabilité sont nombreuses et de natures diverses. Il peut s’agir d’expliquer les décisions d’un modèle déjà entraîné ou de concevoir un modèle explicable dès sa conception. Les méthodes existantes opèrent par ailleurs à diverses étapes du processus de décision, des données qui sont présentées à la décision en passant par l’analyse des paramètres internes du système. Le point commun de toutes ces approches et d’apporter un gain de connaissance concernant le processus de décision. L’enjeu général de l’explicabilité est de répondre à la question « Pourquoi ? » lorsqu’une décision est prise.
L’explicabilité : une voie vers l’IA de confiance
Décisions automatisées : quand l’IA prend des décisions préjudiciables
Discriminations, erreurs médicales, accidents, injustices… Voici quelques faits qui témoignent des conséquences préjudiciables de décisions biaisées ou indésirables de systèmes automatisés.
Biais d’analyse d’images : quand l’IA de Flickr ou Google offense
Google et Flickr ont, il y a quelques années, déployés des systèmes de balisage (tagging) automatiques de photographies.
Il s’agissait de systèmes d’analyse d’images entraînés sur de larges corpus. Ces derniers permettaient d’identifier les éléments présents dans une image et de générer un ensemble de tags. Ces balises avaient pour but de décrire le contenu des photographies ainsi que leur ambiance.
Or certains utilisateurs ont rapidement remarqué la génération de tags considérés comme particulièrement offensants.
Des photographies de personnes noires se sont vu attribuer le tag « gorille[1] ». Des photographies de camps de concentration se sont vu attribuer le tag « sport[2] ». Ces erreurs ont provoqué l’indignation d’utilisateurs et nui à l’image des entreprises.
Uber : quand l’IA provoque un accident mortel
En 2018, un véhicule autonome d’Uber a provoqué la mort d’une piétonne[3]. Le système avait bien identifié la présence de la victime mais ne l’a pas reconnue comme étant un humain.
Ce drame a donné lieu à un procès. En conséquence, une analyse complète de la chaîne de décision du véhicule a été menée pour comprendre les défaillances. Face aux conclusions sévères de l’enquête, Uber a pris la décision radicale d’abandonner son programme de développement de véhicules autonomes.
COMPAS : quand l’IA maintient en prison
Dans le domaine judiciaire américain, le système propriétaire COMPAS (Correctional Offender Management Profiling for Alternative Sanctions) est utilisé comme aide à la décision dans le cadre des libérations conditionnelles ou des mises en liberté sous caution.
Cependant, ce modèle prédictif a essuyé de vives critiques[4].
Il a été la cible de vives critiques car il semble défavoriser certains groupes ethniques en leur attribuant un risque de récidive plus élevé (ce qui n’est pas confirmé par l’analyse des cas réels de récidive). Ainsi ce modèle, utilisé sans discernement, peut avoir des conséquences importantes néfastes sur la vie de membres de minorités ethniques en les maintenant indûment en prison.
Air Canada : quand l’IA hallucine une offre commerciale
Les modèles de langues génératifs sont au cœur de l’actualité ces dernières années. Ils sont eux aussi susceptibles de prendre des décisions incorrectes et préjudiciables.
La compagnie Air Canada en a fait les frais en ce début d’année 2024[5]. Un passager a été mal renseigné par un chatbot sur le site de la compagnie. Ce chatbot lui avait en effet indiqué une procédure de remboursement inexistante.
Le passager a donc intenté un procès à la compagnie aérienne et vient de remporter la bataille judiciaire. Depuis, la compagnie Air Canada a abandonné l’utilisation d’un modèle de langue pour alimenter son chatbot.
Systèmes de décision opaques : un besoin de transparence dans le domaine de l’IA
Les « boites noires » de l’IA : entre besoin de transparence et avantage concurrentiel
Les systèmes de décision opaques sont généralement perçus par les utilisateurs comme étant des boîtes noires. Cette opacité vient principalement de modèles de machine learning. Ces derniers opèrent en leur sein. Ils possèdent des millions de paramètres non-interprétables ajustés durant l’entraînement.
Pour lutter contre cette opacité, certains promeuvent le développement de modèles interprétables dès la conception (transparency by design). Cette revendication intervient en particulier pour des applications dans des domaines sensibles.
Le développement de modèles opaques, souvent propriétaires, répond toutefois à des besoins en matière d’avantage concurrentiel qu’ils confèrent. Cet avantage disparaît dès lors que le système devient transparent. Par ailleurs, le développement de modèles opaques répond aussi à un besoin d’exploitation commerciale via la propriété intellectuelle.
Explicabilité des algorithmes : vers une IA de la confiance
Pour les utilisateurs, l’explicabilité des systèmes favorise l’acceptabilité des décisions qu’ils produisent et augmente le sentiment de fiabilité. Pour les acteurs qui développent ces systèmes, l’explicabilité peut renforcer le sentiment de sécurité lié à leur exploitation. Les explications peuvent aussi s’inscrire dans un cadre légal.
Par exemple, dans son article 22, la réglementation RGPD introduit, sans clairement en définir les contours, un droit à l’explicabilité pour les systèmes de décision automatisés (« La personne concernée a le droit de ne pas faire l’objet d’une décision fondée exclusivement sur un traitement automatisé […] »).
Enfin, dans le cadre d’un processus d’amélioration continue, les explications peuvent permettre l’identification de biais. Elles ouvrent ainsi la voie à leur limitation et au développement de systèmes plus équitables (fair).
Utilité et qualité des explications
Définir ce qu’est une explication est complexe. A ce propos, on trouve dans la littérature scientifique de nombreuses définitions ou tentatives de définition.
Dans le domaine de l’IA, une explication est un intermédiaire entre un processus de décision et un humain.
Il est généralement souhaitable qu’une explication soit en cohérence avec le processus qu’elle décrit et compréhensible par l’utilisateur humain à qui elle est destinée.
Ces deux caractéristiques ne sont pas toujours vérifiées dans les études sur l’explicabilité. Elles peuvent même constituer des motifs de rejets de certains types d’explications qui sont toutefois utiles en pratique.
COMPAS : un système indirectement discriminant
Peut-on expliquer des décisions du système COMPAS, introduit plus haut, en disant qu’il défavorise certains groupes ethniques ? Cette explication semble incohérente avec le fonctionnement interne de COMPAS.
En effet, celui-ci n’utilise a priori pas explicitement l’information d’appartenance à un groupe ethnique pour prendre une décision. COMPAS semble néanmoins utiliser indirectement l’information d’appartenance à un groupe ethnique.
Il peut l’inférer à partir d’autres informations personnelles telles le genre ou l’âge des individus. L’explication peut donc être considérée comme non-cohérente avec le processus de décision mais reste néanmoins utile. Elle est révélatrice de biais souvent difficiles à détecter.
Saliency maps : visualiser l’information n’est pas expliquer
Illustration extraite de Stop explaining black box machine learning models for high stakes decisions and use interpretable models instead
Prenons un autre exemple, celui des saliency maps dans le domaine de la vision par ordinateur et l’analyse d’images. Elles sont utilisées pour visualiser les parties d’une image qui ont majoritairement contribué à la prise de décision d’un modèle.
L’exemple ci-dessus montre deux saliency maps très proches. C’est-à-dire qu’elle, fournisse une « explication » similaire, mais associées à des décisions très différentes. Ainsi, au centre un système prédit la présence d’un chien quant à droite un système prédit la présence d’une flûte traversière.
Le problème principal d’une telle visualisation est qu’elle montre l’information utilisée mais ne dit pas comment cette information a été utilisée. Elle ne satisfait donc pas le critère de compréhensibilité par un humain.
Cette approche de l’explicabilité reste cependant informative et permet de détecter par exemple des biais liés à des corrélations fallacieuses.
Ces biais correspondent à la prise en compte d’informations non-pertinentes pour une décision en lien avec un objet. Cela vient d’une forte corrélation entre ces informations et l’objet en question.
Un exemple classique est la trop forte prise en compte de l’environnement d’arrière-plan d’une photographie pour prédire l’objet au premier plan.
Ouvrir les « boîtes noires »
En pratique, on peut se poser la question de la manière d’ouvrir les boîtes noires. Selon le contexte et l’objectif poursuivi, certaines approches sont plus appropriées que d’autres.
Dans la littérature scientifique, la question de l’explicabilité est abordée en suivant 2 grands axes. D’une part, on peut vouloir construire des modèles explicables de manière inhérente. D’autre part, il est possible d’essayer d’expliquer des modèles opaques déjà entraînés. Ce qui revient, pour ce deuxième axe, précisément à ouvrir la « boîte noire » ».
Nous allons passer en revue les différentes approches de l’explicabilité en nous basant sur une classification en 4 sous-groupes d’approches : l’explicabilité d’un modèle (totale ou partielle) via l’entraînement d’un modèle de substitution interprétable, l’explicabilité locale à l’échelle d’une décision, l’explicabilité par inspection des paramètres du modèle et enfin l’explicabilité inhérente dès la construction (transparent box design).
Taxonomie des travaux sur l’explicabilité issue de l’article A Survey of Methods for Explaining Black Box Models
Explicabilité à l’échelle du modèle : découvrir le processus de décision
Cette première approche à l’échelle du modèle (model explanation) vise à lever le voile sur le processus de décision, c’est une forme de rétro-ingénierie du modèle opaque. Par l’analyse des prédictions d’un modèle, l’objectif est de déterminer un processus de décision transparent qui rend compte de ces décisions au mieux.
D’un point de vue pratique, cela consiste à entraîner un modèle interprétable simple qui peut se substituer suffisamment précisément au système à expliquer. Idéalement, un tel modèle de substitution doit réaliser des prédictions similaires à celles du modèle opaque dans un contexte identique.
Des modèles interprétables sont des modèles pour lesquels il est possible d’inspecter leurs composants de manière à en tirer des informations pertinentes. Un arbre de décision peu profond, un ensemble de règles ou encore un simple modèle linéaire sont considérés comme interprétables.
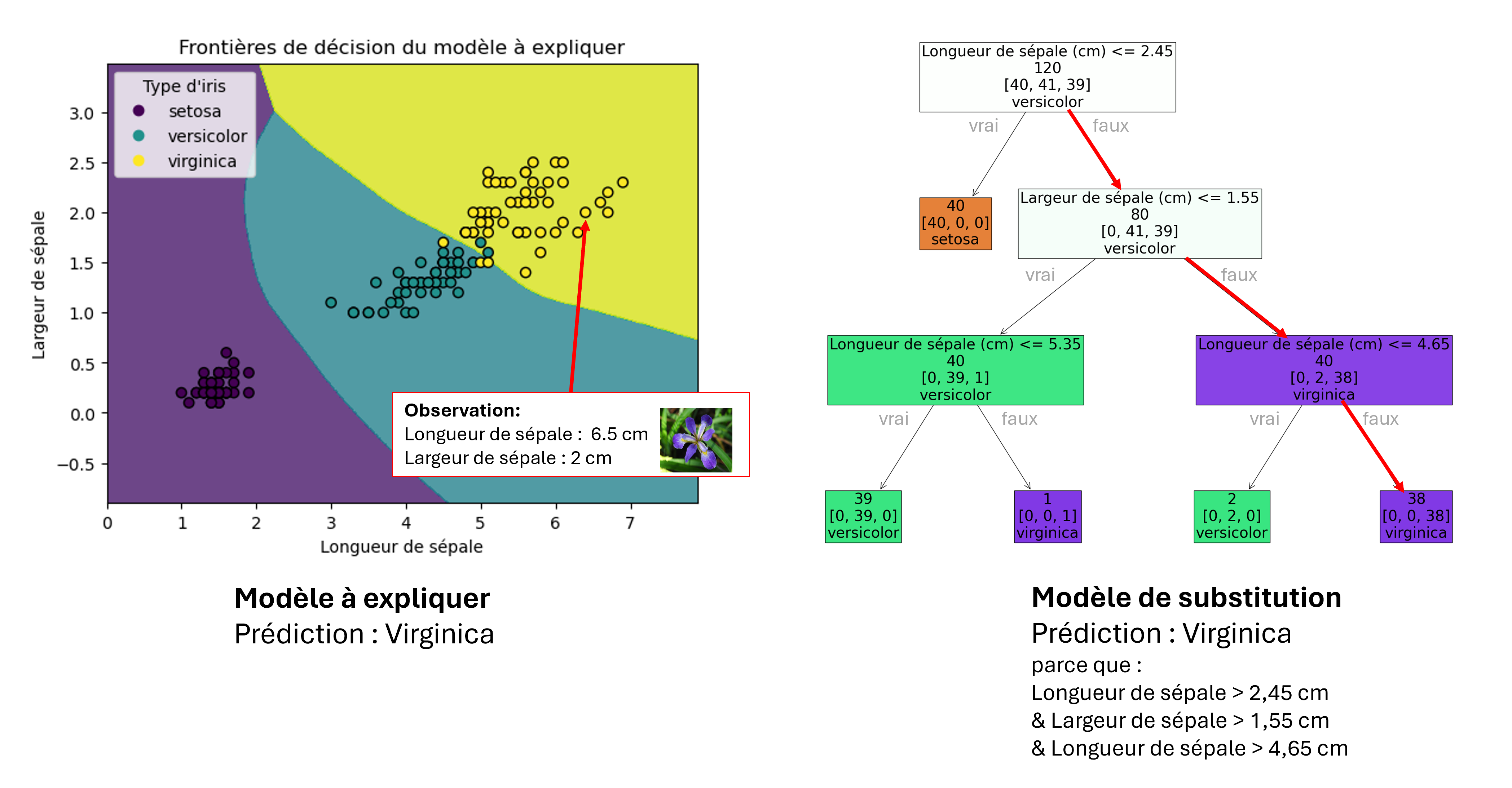
Sur l’exemple de la figure ci-dessous, nous avons réalisé l’exercice d’expliquer un modèle opaque (un petit réseau de neurones) par un modèle interprétable (un arbre de décision peu profond).
À gauche, un modèle entraîné à prédire le type d’iris à partir de 2 caractéristiques. Les points sont les données d’entraînement, les frontières des zones colorées sont les frontières du modèle entraîné. À droite, un arbre de décision de profondeur 3 entraîné à partir des prédictions du modèle de gauche. Ce modèle de substitution fournit naturellement une liste de décisions (l’explication) pour chacune de ses prédictions.
L’approche par entraînement d’un modèle de substitution est dite model agnostic. C’est-à-dire qu’elle peut être appliquée à n’importe quel type de systèmes et en particulier les boîtes noires.
Cependant, pour mettre en œuvre cette approche, il est nécessaire d’avoir accès à un ensemble de couples entrées-sorties du modèle à expliquer. Cet ensemble doit être suffisamment représentatif du domaine sur lequel on cherche à fournir des explications.
Ce n’est pas toujours possible en pratique à cause des contraintes financières liées à l’accès au modèle. De plus, la complexité des calculs nécessaires pour générer des couples entrée-sortie peut également constituer un obstacle.
Il faut aussi noter qu’une telle approche n’explique généralement pas les décisions d’un modèle en totalité. Si tel était le cas, le modèle boîte noire n’aurait plus de raison d’être. En effet, le modèle interprétable simple pourrait se substituer à lui sans perte de performance.
Explicabilité à l’échelle d’une observation : comprendre une décision particulière
Cette approche consiste à expliquer une décision particulière d’un modèle (outcome explanation). Par exemple, si un système bancaire refuse un prêt à un individu en fonction de sa situation, celui-ci voudra naturellement savoir pourquoi le prêt est refusé.
Autre exemple, imaginons qu’une voiture autonome décide brusquement de tourner et provoque un accident. Les passagers, l’assurance ou même le constructeur du véhicule souhaiteront savoir pourquoi la voiture a pris une telle décision.
Dans ce cadre, une approche de l’explicabilité à l’échelle des décisions consiste à tenter de répondre à la question « Que se serait-il passé si… ? ». Agir hypothétiquement sur le monde et estimer la réponse fictive d’un système est le cœur de l’approche contrefactuelle de l’explicabilité.
En philosophie, le terme « contrefactuel » fait référence à la réflexion sur les événements qui ne se sont pas produits mais qui auraient pu se produire sous certaines conditions[6].
Un contrefactuel, dans la théorie du Judea Pearl, pionnier de l’intelligence artificielle moderne, correspond à une intervention sur un modèle causal du monde. Ce modèle causal définit l’influence causale de variables sur d’autres.
En pratique, ce dernier n’est généralement pas connu. Il est toutefois possible de proposer des modèles causaux plausibles dans de nombreux domaines d’application.
Ainsi on peut, sous certaines conditions, simuler l’occurrence d’un scénario fictif en agissant sur la valeur d’une des variables de ce modèle causal.
Cette dépendance causale des variables rend généralement la manipulation de l’une d’entre elle indépendamment des autres impossible. Répondre à la question « Que se serait-il passé si… ? » est donc un problème difficile qui ne peut pas être traité naïvement.
L’approche contrefactuelle est l’une des approches de l’explicabilité. Elle a ainsi vocation à analyser les éventuelles variations de décision d’un modèle résultant de perturbation de la donnée d’entrée. Ce sont des approches qui, outre l’analyse d’une décision donnée, permettent d’évaluer la robustesse d’un modèle. Elles permettent également d’identifier certains facteurs qui jouent un rôle important dans la prise de décision.
Explicabilité par inspection du modèle : dévoiler les rouages du système
L’explicabilité par inspection du modèle (« model inspection ») regroupe un ensemble de techniques. Ces derniers permettent de comprendre comment certains facteurs dans les données d’entrée influencent les paramètres internes d’un modèle à expliquer.
Les saliency maps introduites plus haut en sont un exemple. Elles permettent par exemple de détecter l’utilisation par un modèle d’éléments non pertinents au cours du processus de décision, c’est-à-dire un biais de corrélation fallacieuse.
On ne fera pas ici un catalogue de l’ensemble des techniques d’inspection de modèle mais citons-en quelques-unes.
Une première technique consiste à analyser, via des graphes, la dépendance entre variables de sortie et d’entrée du modèle à expliquer.
Une autre technique consiste à visualiser l’activation des poids dans un réseau de neurones via des cartes de chaleur (heatmaps).
Une dernière technique consiste à visualiser la sensibilité d’un modèle, c’est-à-dire des changements de prédictions éventuels, en réponse à des variations dans les données d’entrées.
Explicabilité dès la conception : construire des modèles transparents pour une IA éthique et de confiance
L’explicabilité dès la conception (transparency by design) consiste à produire des modèles interprétables de manière inhérente. Produire de tels modèles requiert généralement une coopération entre ceux qui entraînent le modèle et les utilisateurs du modèle à qui les explications sont destinées. Cette approche est principalement défendue pour des applications dans des domaines sensibles.
Un premier argument en faveur de cette approche est que les modèles interprétables par construction n’ont pas nécessairement de performances moins bonnes que les modèles opaques contrairement à une idée reçue.
Un second argument est que les explications a posteriori de modèles opaques peuvent être précises de manière globale mais très imprécises localement. Cela peut conduire des entreprises à instrumentaliser l’explicabilité à des fins de « fairwashing ». Cette pratique consiste à donner l’impression fausse qu’un modèle opaque est équitable alors qu’il est, en réalité, localement inéquitable (unfair). Un modèle transparent permettrait plus difficilement de masquer ces biais.
Explicabilité et traitement du langage : des défis spécifiques
Les modèles les plus récents dans le domaine du traitement du langage sont pour la plupart des exemples parfaits de « boîtes noires ». GPT-4 est un système alimenté par un modèle composé d’un nombre de paramètres de l’ordre du millier de milliards de paramètres (1,7×1012 environ).
L’utilisation croissante de ces modèles propriétaires opaques pour le développement de nouveaux systèmes va de pair avec un désir toujours plus grand d’explicabilité. Mais la taille des modèles et la nature des données manipulées pose des problèmes spécifiques.
Des modèles de langues qui ne sont pas neutres
Avant de détailler quelques problèmes spécifiques aux systèmes de traitement du langage, notons que ces systèmes ne sont pas eux non plus dépourvus de biais. Les modèles de langues génératifs tels que GPT-4 (openAI) ou Gemini (Google) possèdent un biais de culture américaine. Pour le dire de manière simple et un peu caricaturale, ces modèles écrivent comme un humain américain et contribuent à propager la culture américaine là où ils sont utilisés.
Les modèles de langue ont également tendance à perpétuer des stéréotypes de genre au sein des contenus qu’ils produisent (par exemple « un homme est un docteur / une femme est une infirmière », « l’homme travaille / la femme cuisine »).
L’adoption de ces nouveaux modèles et leur industrialisation sera donc en partie conditionnée par la capacité renforcer la confiance des utilisateurs. Cela passera entre autres par la capacité à expliquer les textes qu’ils génèrent ou les processus de décisions dans lesquels ils sont intégrés.
Un texte est bien plus qu’une suite de mots
Les données textuelles sont particulièrement complexes à traiter dans un contexte d’explicabilité. De nombreuses techniques d’explicabilité ne peuvent pas être utilisées simplement sur des données langagières.
Un texte n’est pas qu’une suite de mots, c’est une collection de sens intriqués qui varient en fonction du contexte dans lequel le texte se trouve. Il est par exemple très difficile de ‘perturber’ un texte (c’est-à-dire en modifier un aspect) même de manière minimale. Une manipulation, quelle qu’elle soit, a souvent des répercutions sur tout ou partie du texte original.
Illustrons ceci sur un exemple. Je vous invite à essayer de transformer la critique du film de science-fiction Avatar ci-dessous en une critique de ‘western’ en faisant un minimum de modifications dans le texte. L’exercice est pour le moins difficile et il s’agit d’une tâche difficile à automatiser.
Source : IMDB
La manipulation explicite de données textuelles étant complexe, diverses équipes de recherche tentent de réaliser des transformations dites non-explicites. Cela consiste à intervenir non plus sur les textes mais sur les vecteurs qui les représentent et sont utilisés par les modèles de machine learning.
Des représentations textuelles toujours plus opaques
Historiquement, les représentations de textes étaient de type bag-of-words (« sac de mots). C’est un modèle de texte qui utilise une représentation du texte basée sur une collection désordonnée de mots.
Dans une telle représentation, chaque composante a un sens précis qui correspond à la présence ou l’absence d’un mot de vocabulaire. Ce type de représentation est naturellement interprétable ce qui est bénéfique pour l’explicabilité globale d’un système. Par ailleurs, dans certaines situations, ces représentations peuvent être facilement manipulées.
Aujourd’hui, la plupart des représentations des textes sont le résultat d’opérations complexes et opaques. Les vecteurs qui représentent les textes sont une superposition de nombreuses informations intriquées. En outre, les composantes individuelles de ces représentations ne sont pas interprétables. Il ne faut cependant pas faire une croix sur l’explicabilité.
L’explicabilité à l’ère des modèles de langues
Il est possible d’entraîner des modèles de machine learning qui vont modifier ces représentations opaques de textes à la marge. Cela peut être utile générer des contrefactuels. Cela peut l’être également, pour étudier les frontières de décision d’un classifieur, une famille d’algorithmes de classement statistique.
Par ailleurs, un ensemble de travaux explorent la possibilité d’utiliser des techniques d’algèbre linéaire pour manipuler les données textuelles non-explicitement.
Techniquement, il s’agit de déterminer dans des espaces vectoriels de grandes dimensions dans lesquels se trouvent les représentations de textes des sous-espaces de faible dimension associés à la prédiction de certains concepts d’intérêt.
Techniquement, cela implique de jouer avec des espaces vectoriels de grandes dimensions. Ces sous-espaces sont associés à la prédiction de certains concepts d’intérêt.
Ensuite, par un jeu de projection il est possible de réaliser des opérations d’effacement de concept ou de manipulation de la valeur du concept. Il suffit alors d’intervenir directement sur les vecteurs représentant les textes.
Divers travaux en cours chez Onepoint au sein du laboratoire TALia s’inscrivent dans ce cadre.
Explicabilité : plus de transparence pour plus de confiance
À l’ère de l’IA générative, le besoin d’explicabilité se fait de plus en plus pressant.
Le développement rapide des nouveaux modèles de machine learning soulève des questions éthiques et de propriété intellectuelle. Cela nécessite donc de pouvoir comprendre et expliquer le processus de génération des contenus qu’ils produisent.
Ce besoin de transparence est d’autant plus nécessaire que ces modèles sont d’ores et déjà largement exploités. Cela comprend entre autres, pour les applications « néfastes », la génération automatique de fake news.
L’explicabilité est un champ de recherche transverse important lié à d’autres grands domaines tels l’interprétabilité, la production de modèles robustes ou encore le développement d’IA responsables, éthiques et équitables.
L’explicabilité est à la croisée des grands enjeux actuels et futurs de l’IA. Et les acteurs scientifiques comme industriels ne doivent plus aujourd’hui faire l’impasse sur ce sujet.
Pour aller plus loin
Articles dans la littérature scientifique :
[1] Conor Dougherty, « Google Photos Mistakenly Labels Black People ‘Gorillas’ », JULY 1, 2015.
[2] Alex Hern, « Flickr faces complaints over ‘offensive’ auto-tagging for photos », theguardian.com, Wed 20 May 2015.
[3] AFP, « Accident mortel d’Uber : le logiciel n’a pas reconnu un piéton hors des clous », lepoint.fr, 06/11/2019.
[4] Ellora Thadaney Israni, « When an Algorithm Helps Send You to Prison », nytimes.com, Oct. 26, 2017.
[5] Kyle Melnick, « Air Canada chatbot promised a discount. Now the airline has to pay it », nytimes.com, February 18, 2024.
[6] Jacqueline Guillemin-Flescher , « Linguistique contrastive et traduction », Volume 4, Page 140, 190 pages, Ophrys, 1992.