Deux Systèmes pour une liberté de penser
En Machine Learning, le Système créé possède une aptitude d’apprentissage ainsi qu’une capacité de réponse rapide et avérée aux problèmes qui lui sont présentés. Cela est très proche du concept de nos deux modes de pensée.
En effet, notre cerveau possède deux systèmes de pensée : le Système 1 et le Système 2. Démontrée par les psychologues comportementalistes, l’existence de ces deux Systèmes gère notre manière de traiter l’information. Le Système 1 est rapide et intuitif. Basé sur notre expérience, il permet des réponses intuitives aux problèmes qui nous sont posés. Le Système 2, quant à lui, est plus lent et nécessite plus d’efforts mais s’avère aussi plus logique et réfléchi. C’est à l’aide du Système 2 que nous apprenons. Une fois l’apprentissage terminé de manière plus ou moins longue, il est possible alors de traiter le problème instinctivement en utilisant notre Système 1. C’est ce même mécanisme qui est reproduit en Machine Learning. Le Système 2, pour une machine, est la phase d’apprentissage réalisée à l’aide d’algorithmes. Ces algorithmes permettent de tirer profit des données qui lui sont présentées. Le résultat de l’algorithme fournit une fonction, aussi appelée règle ou encore modèle. C’est ce modèle obtenu qui représente le Système 1 de pensée. Désormais, le programme est capable de fournir un résultat rapide sur la question posée. Cependant, en comparaison avec le Système Humain, celui-ci présente l’avantage de ne pas être soumis aux émotions pouvant nous induire en erreur.
Le Machine Learning dans tous ses états
Un concept simple à mettre dans toutes les poches
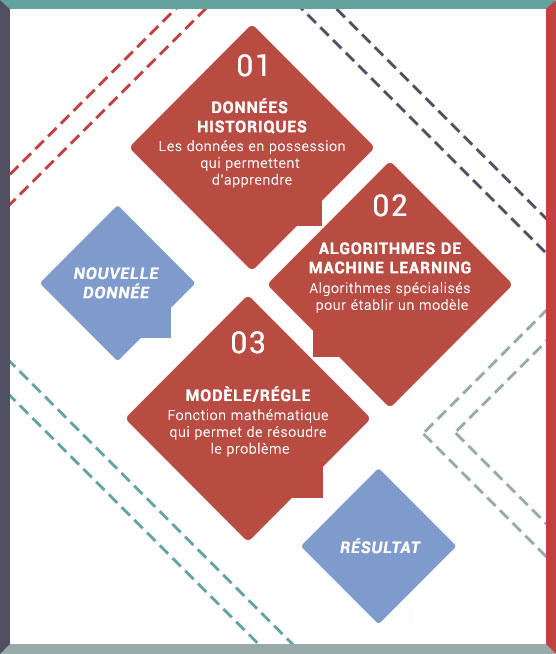
Le Machine Learning est l’ensemble des outils fournissant à un programme informatique la fonctionnalité d’apprentissage. Comme défini par Tom Mitchell, auteur de « The Discipline of Machine Learning », un système de Machine Learning est un programme informatique qui apprend à partir de l’expérience dans le but de résoudre une certaine tâche. La performance de résolution s’améliorant avec l’expérience. Trois notions régissent le concept d’apprentissage pour une machine dans cette définition :
- L’expérience : qui correspond aux données en notre possession.
- La tâche : qui correspond à ce que l’on cherche à résoudre. On peut la voir comme le but du programme. Reconnaitre une télévision et un téléphone est une tâche. Prédire les ventes d’un magasin, prédire le stock nécessaire ou encore savoir qui sont ses clients sont d’autres exemples.
- La performance : qui correspond à la véracité des résultats. L’optimisation de la performance se fait en améliorant le modèle. Pour cela on modifie l’algorithme utilisé, on change les paramètres et on acquiert plus d’expérience.
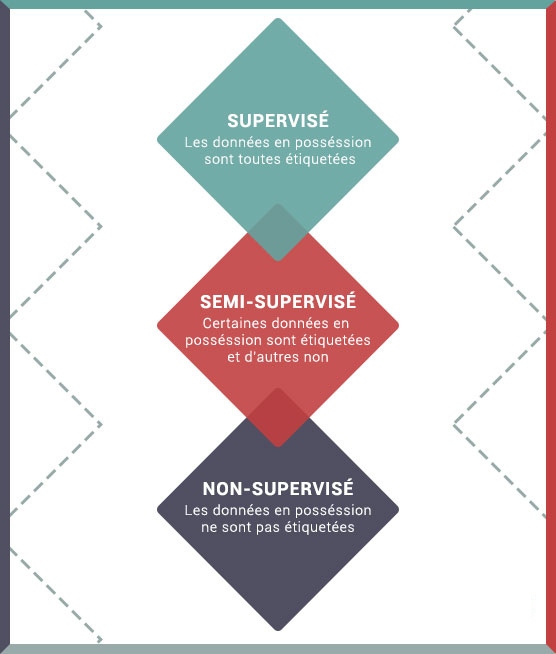
3 modes d’apprentissage
Les données à disposition peuvent avoir différentes formes. Pour récupérer au mieux les informations, il existe trois principaux types d’apprentissage :
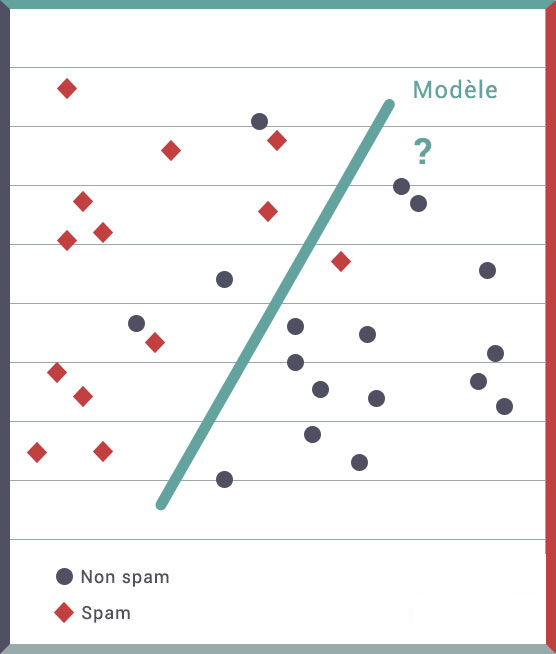
Apprentissage supervisé : L’apprentissage supervisé est un apprentissage se faisant avec des données étiquetées. En clair, les données possèdent un attribut spécifiant le résultat que l’on cherche à résoudre. Pour chaque donnée, le résultat est connu. Par exemple, avec un jeu d’images de télévision et de téléphone, l’algorithme sait pour chacune de ces images si c’est une télévision ou un téléphone. L’apprentissage supervisé est utilisé notamment pour des problèmes de classification ainsi que de régression.
Apprentissage non-supervisé : Cette fois-ci, les données en notre possession sont non étiquetées. On ne sait pas si les mails sont des spams ou non. Les algorithmes sont chargés par eux-mêmes de trouver des correspondances entre les données et les attributs. Ce type d’apprentissage est généralement utilisé pour réaliser des groupes.
Apprentissage semi-supervisé : L’apprentissage semi-supervisé est facile à comprendre puisque c’est un mélange des deux apprentissages précédents. Les données d’apprentissage utilisées sont donc, pour certaines, étiquetées, d’autres non étiquetées. Par analogie avec l’être humain, lorsque celui-ci apprend, il ne connait pas toujours le résultat. C’est alors à lui de mettre en relation ce qu’il sait et ce qu’il ignore.