Microservices : les risques de l’entropie !
Tout ce qu’il faut savoir pour que vos applications distribuées en microservices ne soient pas minées par l’entropie.
Pour évoquer l’entropie des microservices, il faut commencer par le début. Et le début, ce sont les applications monolithiques. Ces dernières avaient des avantages indéniables pour vos applications stratégiques au moment de leur lancement. Au commencement, elles étaient simples à construire, simples à mettre au point et à déployer. Et cela suffisait.
Malheureusement, aujourd’hui vous faites ce constat amer : cette simplicité a volé en éclat au fil du temps. L’incapacité à faire évoluer les applications monolithiques a battu en brèche tous vos idéaux. Cela devient un handicap pour développer votre business.
L’heure des comptes a sonné et la note est plutôt salée. Niveau bilan, pour le monolithe, c’est zéro pointé. La sagesse vous recommande peut-être un nouveau départ. Heureusement les applications distribuées en microservices vous tendent les bras avec leurs promesses de scalabilité, de résilience et surtout d’évolutivité.
Aussi, pour éviter de renouveler les erreurs commises avec les applications monolithiques, il faudra changer nos pratiques. Et peut-être, qui sait, parviendrez-vous alors libérer vos investissements sur de nouveaux périmètres plus rentables.

Applications monolithiques : une fin programmée ?
La principale difficulté rencontrée par les entreprises de toutes tailles sur les applications concerne majoritairement les évolutions. Ce problème se manifeste généralement par des coûts et des délais anormalement importants. On observe également une grande fragilité de l’application aux changements, même mineurs. Ces derniers laissant apparaitre des régressions nombreuses et imprévisibles. Ces applications qui vous tourmentent ont souvent une architecture monolithique.Qu’est-ce qu’une application monolithique ?
Une application monolithique est un modèle traditionnel de conception d’application. Elle correspond à une application qui regroupe un grand nombre de fonctionnalités dans une même base de code qui est packagée puis déployée sous la forme d’une seule unité. Elle peut être conçue de manière modulaire avec des sous-modules internes qui sont déployés et exécutés dans une même unité. Selon la taille de l’application, des équipes de développement importantes et multiples interviennent parfois sur le même code. Cela qui engendre des besoins forts de synchronisation pour éviter des modifications concurrentes impactant une même fonctionnalité.Une durée de vie moyenne comprise entre 6 et 8 ans
Les applications monolithiques ont une durée de vie de 6 à 8 ans en moyenne. C’est court à l’échelle de la vie d’une entreprise.Un code complexe : le spaghetti
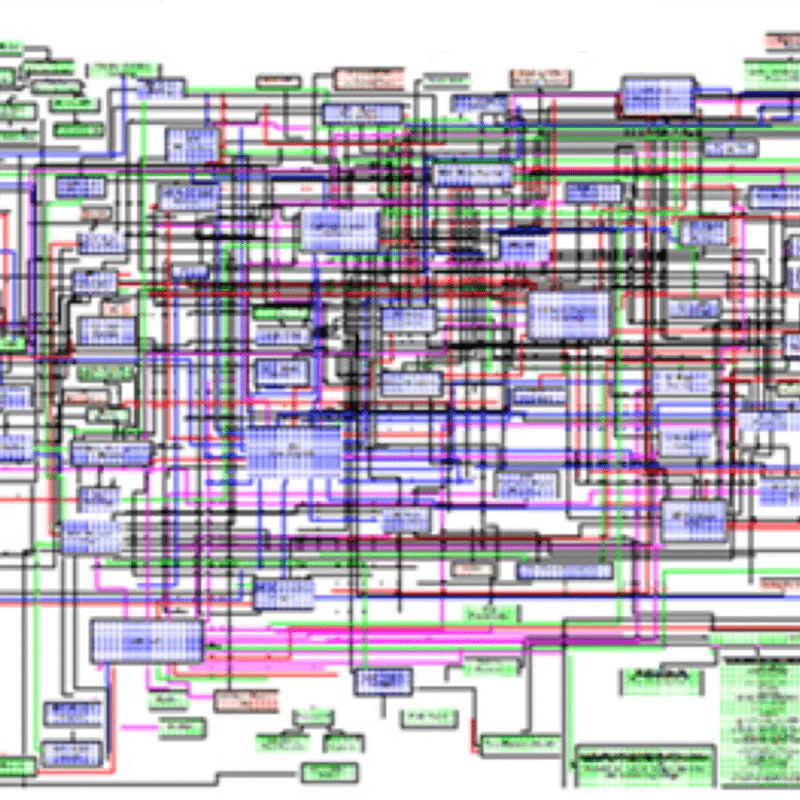
Le code spaghetti pourrait gravement porter préjudice à vos applications. Le code spaghetti, c’est cet important volume de code où rechercher une fonction particulière s’apparente à rechercher une aiguille dans une botte de foin. Ce code entremêlé, ne peut évoluer à cause des relations de dépendances (voir schéma). Recenser avec précision tous les impacts qui donnent suite à une évolution du code tient plus du chemin de croix !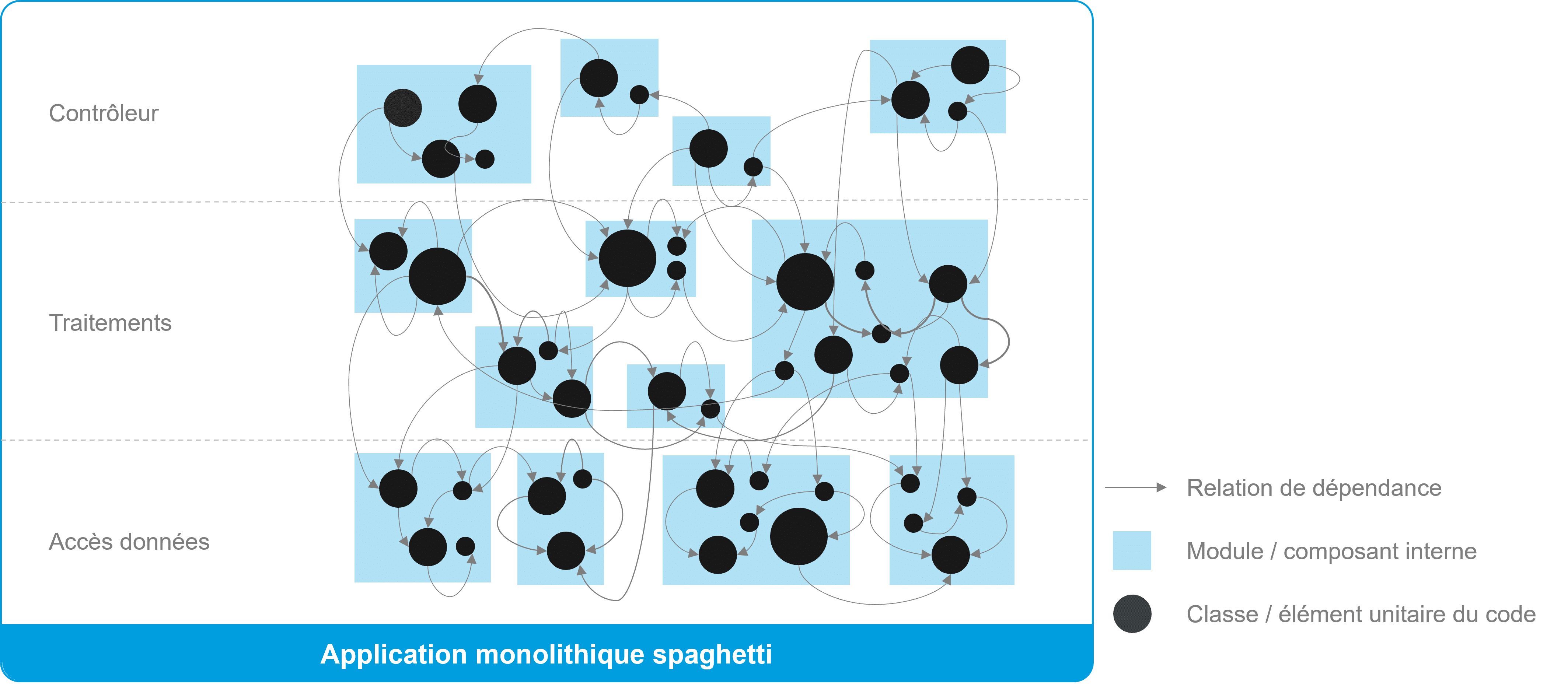
Onepoint – Monolithe spaghetti
L’érosion de la connaissance des applications
Quoi de mieux qu’une documentation à jour pour prendre connaissance de votre application monolithique ! Le problème c’est qu’elle est rarement à jour. Ainsi, la connaissance de l’application se perd au fil du temps. La complexité de l’application est si importante qu’elle accapare à temps plein les équipes aux délicates opérations de maintenance. Cela laisse peu de temps pour mettre à jour la documentation. Tous ses facteurs de pénibilités pourraient se traduire par un turnover croissant.Défauts de performance et difficulté de mise à l’échelle
Autre constat, les applications monolithiques sont bien souvent sujettes à des problèmes de performances et de scalabilité. La taille de ces applications est un frein pour la mise à l’échelle. De plus, leur complexité peut porter préjudice à l’optimisation et l’implémentation du code.Non-respect des standards de qualité du code
Lors des audits de code préalables aux études d’architecture, la face cachée de l’iceberg fait froid dans le dos. L’application des normes de développement, composantes indispensables pour l’efficacité des équipes et la qualité de l’application, ne sont hélas pas toujours respectées. Conséquence : la faiblesse du code introduit souvent des vulnérabilités.Entropie des applications : quand le chaos dépasse l’entendement
Malgré les efforts fournis pour gérer la complexité de l’application, le verdict est hélas souvent implacable : il faut réécrire l’application pour repartir sur une base architecturale saine. En effet, la complexité accumulée est telle, qu’elle dépasse de loin les capacités cognitives humaines. Il n’est donc plus envisageable de rattraper les choses. L’application monolithe n’a plus aucune chance de retrouver de réelles capacités d’évolution. Pour comprendre cette décision, il est intéressant de préciser ce que l’on entend par complexité. Dans ses travaux sur la théorie de l’évolution des logiciels, Manny Lehman distingue trois grands types de complexité :- La complexité interne au code
Exprimée par des métriques utilisées par les outils de qualimétrie logicielle pour mesurer la complexité interne au code, à savoir :
- La complexité cyclomatique,
- La complexité NPath
- La complexité cognitive [voir ref1].
- La complexité de la structure du code ou entropie L’entropie correspond aux désordres dus aux dépendances entre les différentes parties d’un logiciel. Nous retenons aussi le terme scientifique « entropie » pour désigner la dégradation dans le temps de la structure de l’application (i.e. son architecture).
- La complexité externe au code Elle désigne la complexité externe au logiciel, c’est-à-dire la quantité et la qualité de la documentation qui aide à comprendre le logiciel et son code.
Onepoint – Complexité de la structure
Complexité interne au code : les outils de qualimétrie ne suffisent pas
Les outils de qualimétrie logicielle disponibles sur le marché (sonarcube, codacy…) visent à s’assurer que les normes de codage sont respectées et utiles. Ils aident les développeurs en pointant directement les artefacts sur lesquels intervenir. Cela ne suffit hélas pas pour redonner l’évolutivité attendue aux applications monolithiques en fin de vie.Complexité externe au code : la documentation ne suffit pas
Produire une rétro-documentation à partir du code est une tâche qui, même si longue et fastidieuse, reste réaliste. Là encore, cette action apportera quelques améliorations mais demeurera insuffisante pour redonner à l’application, le niveau d’évolutivité attendu.C’est la complexité structurelle (entropie) qui en est la cause
C’est le désordre dans la structure de l’application qui est la cause d’une complexité insurmontable. Les modules internes et packages de l’application ont atteint un niveau de dépendance tel qu’il est devenu impossible de discerner leurs contours et de s’y retrouver. De plus, l’entrelacement des problématiques techniques et fonctionnelles au sein du code accentue encore le problème.Quels indicateurs suivre pour contenir l’entropie ?
Il convient maintenant de définir les bonnes métriques. Celles susceptibles de vous aider à mesurer l’évolution de la complexité de vos applications dans le temps. Il faut aussi établir des seuils. C’est la condition nécessaire pour anticiper les dérives de complexité et d’intervenir avant qu’elle nous dépasse. Nous partageons avec vous quelques repères afin de comprendre de quoi il retourne.Lorsque c’est simple, tout va bien
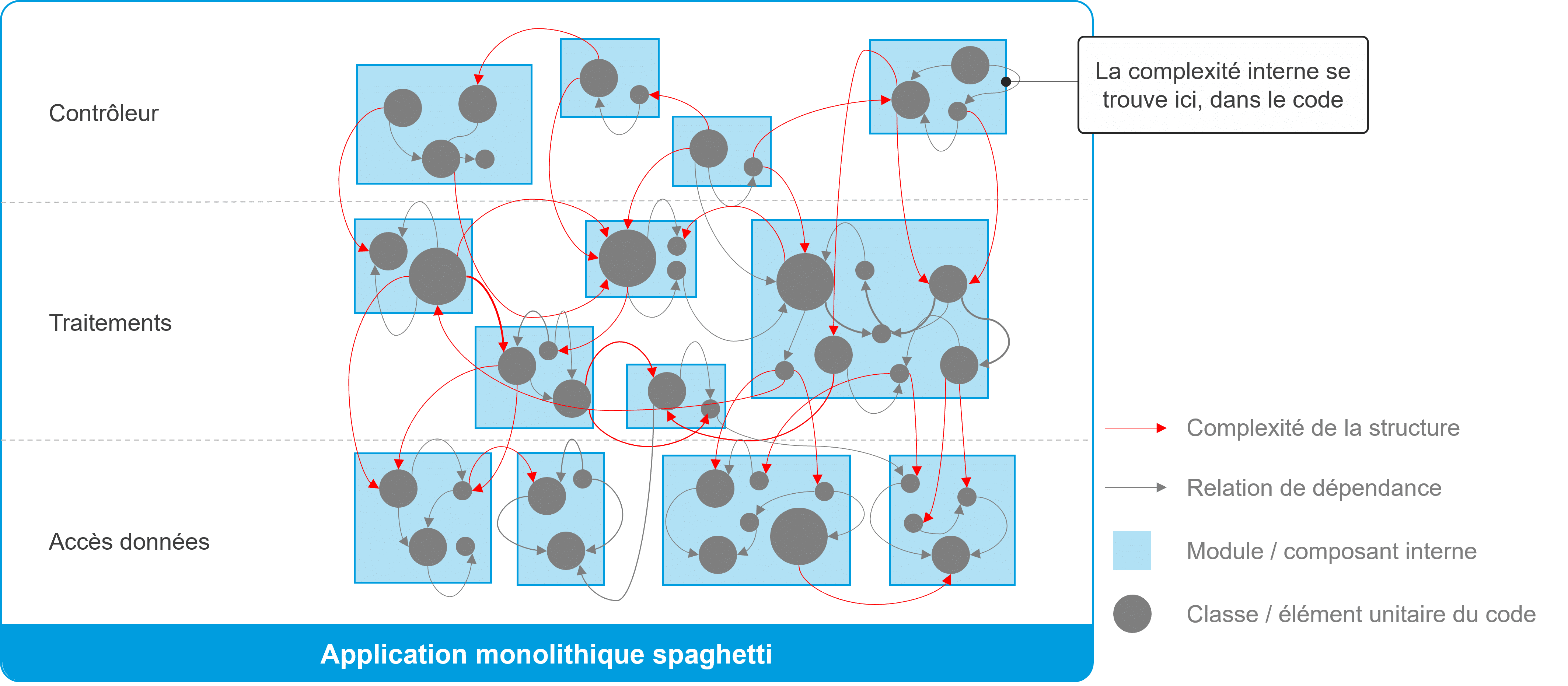
Dans ses premières versions, l’application est simple et ne présente pas de réelle complexité. Aucune action pour traiter l’entropie n’est nécessaire. L’application reste lisible. Les évolutions n’impactent pas le comportement de l’application. Les demandes d’évolution peuvent être traitées rapidement et sans surcoût.Le marqueur clé : le seuil de complexité perceptible
À ce stade, que l’on appelle le seuil de complexité perceptible, il n’y a encore aucune raison de paniquer. Mais on aura toutes les raisons d’être vigilant. Comme l’expression le suggère, les points de douleurs sont progressivement perceptibles. À ce palier sensible, les premiers signaux apparaissent. Les anomalies deviennent plus fréquentes lors des évolutions. Par conséquent, les évolutions s’amorcent avec peine. Les temps et les coûts s’allongent. Les tests de non-régression sont plus complexes et longs à réaliser. Un des indicateurs clés du franchissement du seuil de complexité perceptible, qui passe souvent inaperçu, est le moment où un ou plusieurs membres très expérimentés de l’équipe de développement deviennent indispensables pour faire évoluer l’application sans risque de régressions. L’embarquement de nouveaux développeurs devient également plus délicat.Entropie des microservices : le seuil de complexité irréversible
L’application a du vécu. Elle a subi de nombreuses évolutions. Différentes équipes de développement sont intervenues sur le code. Il devient extrêmement complexe et critique d’intervenir sur l’application. Vos développeurs entrent alors dans un champ où leurs capacités cognitives n’ont plus prise sur la complexité. Il est trop tard pour revenir en arrière. Le niveau de complexité est devenu tel qu’ils ne pourront plus faire évoluer l’application sans risques majeurs. J’imagine que vous anticipez ce qui va se tramer à terme : la mort de l’application. Ce seuil peut néanmoins encore être partiellement repoussé. Il devient alors indispensable de s’appuyer sur une équipe qui dispose d’une profonde connaissance fonctionnelle et technique de l’application. Il s’agit habituellement d’une d’équipe qui est intervenue de nombreuses années sur l’application. Toutefois, ce scénario reste temporaire et ne résistera pas au turnover.
Onepoint – Les seuils de complexité irréversible face aux capacités cognitives
Entropie des microservices : on casse tout et on recommence ?
Les microservices, un choix évident
Pour répondre aux enjeux d’évolutivité et de time to market, les applications distribuées en microservices dominent le marché. Nombreuses sont les DSI qui ont déjà franchi le pas. D’importants budgets ont été alloués pour réécrire les applications. Comment donc éviter les écueils du monolithe, voire pire !Les architectures distribuées en microservices : un pattern d’architecture conçu pour l’évolutivité
Pour remplacer l’application monolithe, la nouvelle architecture cible que l’on propose est une architecture distribuée en microservices. C’est une cible à atteindre et il est intéressant de passer par une phase de transition que l’on appelle l’application monolithe modulaire. Cette dernière consiste à créer une nouvelle version de l’application monolithe, réellement modulaire cette fois-ci. Ces modules internes sont ordonnés, avec des frontières claires et respectées. Les étapes suivantes consistent ensuite à transformer chaque module interne en microservices. Une fois validée et éprouvée en production, cette conception modulaire procure un nouveau niveau d’évolutivité.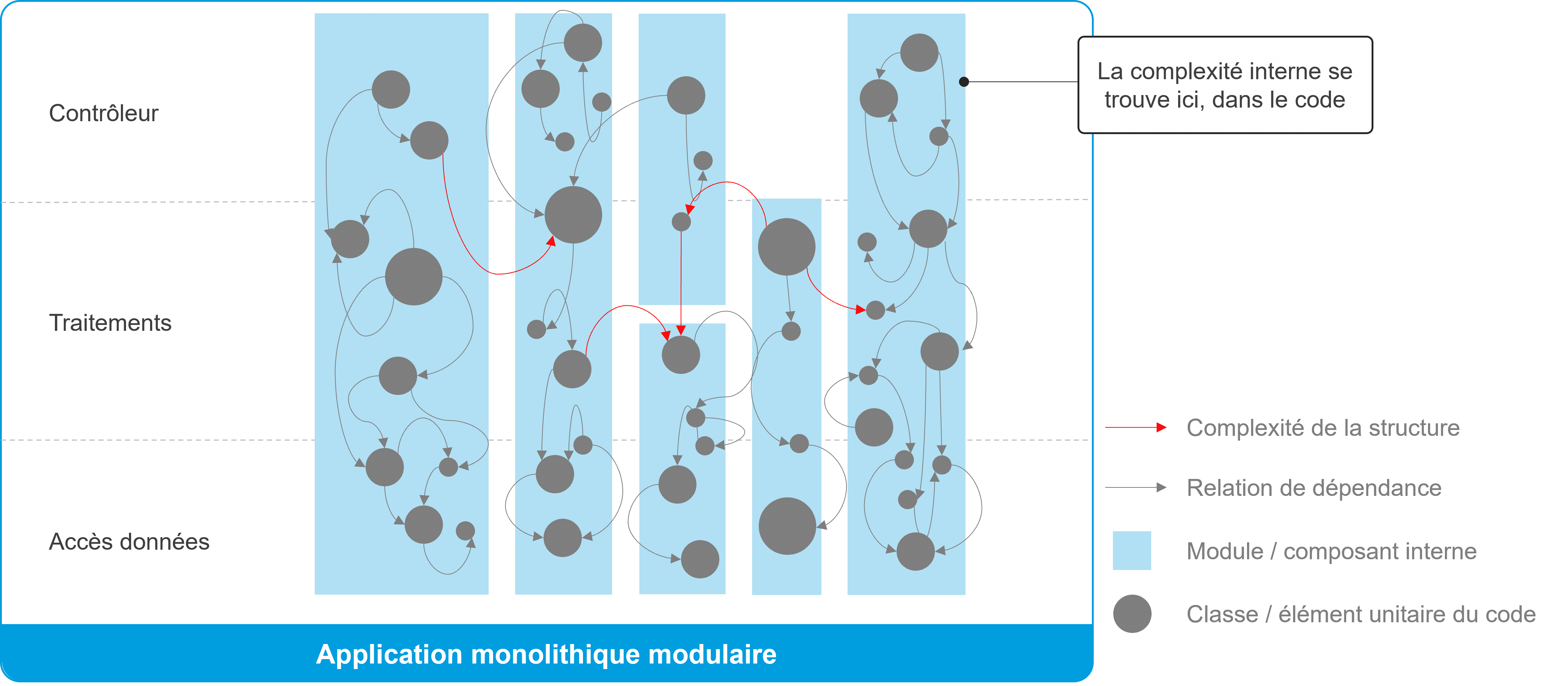
Onepoint – Application monolithique modulaire
Caractéristiques d’une architecture distribuée en microservices :
Dans son modèle théorique, une architecture distribuée en microservices doit respecter un ensemble de caractéristiques :- C’est une architecture modulaire : chaque microservice reprendra une partie réduite des fonctionnalités de l’application monolithique. L’application monolithique a donc vocation à être remplacée par un ensemble de microservices.
- C’est une architecture distribuée : chaque microservice communique avec les autres microservices par des appels distants à travers le réseau (en synchrone ou en asynchrone).
- Chaque microservice a des frontières clairement définies : son périmètre fonctionnel est limité à un ensemble de fonctionnalités cohérentes et explicitement déclarées.
- Un microservice recherche le maximum d’indépendance et a une orientation « ne rien partager » : Un microservice est développé par une équipe indépendante. Il est versionné, construit, déployé et exécuté de façon indépendante également.
- Chaque microservice est autonome sur son périmètre fonctionnel : En dehors d’un cadre théorique, il sera rare d’avoir la possibilité de concevoir des microservices réellement complètement autonomes sur leur périmètre. On cherchera alors à concevoir chaque microservice pour qu’il soit le moins dépendant des autres.
- C’est une architecture orientée services : chaque microservice expose ses fonctionnalités à travers des interfaces d’échanges clairement définies par des contrats de services (1). Par exemple, la base de données d’un microservice est privée. On ne peut pas y accéder en direct sans passer par les interfaces d’échanges exposées par le microservice. Dans le meilleur des mondes, on cherchera toujours à réduire la communication entre les microservices internes. On aura donc intérêt à privilégier les communications asynchrones. Elles favorisent le découplage temporel entre les microservices. Résultat, vos microservices gagnent en autonomie.
- On l’a évoqué, chaque microservice est autonome ou à minima très faiblement couplé avec les autres microservices. Cela permet à chaque microservice d’évoluer à son propre rythme, de façon indépendante du reste du système.
- Une des spécificités d’une architecture orientée-service est de découpler une fonctionnalité des choix pris pour l’implémenter. Cela est possible grâce à une bonne encapsulation logicielle. Dans le cas d’une architecture orientée service, on gère les dépendances entre les services à travers des contrats de service qui représentent une abstraction des choix d’implémentation. Plus précisément, on masque aux développeurs d’applications la complexité des implémentations internes. La modification des choix d’implémentation d’un microservice se gère donc plus facilement.
- Chaque microservice est sous la responsabilité d’une équipe autonome. Un système distribué en microservices permet de paralléliser le travail des équipes en minimisant les besoins de synchronisation.
Entropie des microservices : en cause, leur prédisposition à la complexité
Donc le choix des microservices semble tout indiqué pour la refonte et le développement des nouvelles applications. Seulement voilà, les applications distribuées en microservices sont par nature beaucoup plus complexes que les applications monolithiques. Alors comment ne pas retomber, plus vite encore, dans le piège de l’entropie ?Premier facteur : La complexité intrinsèque des applications distribuées en microservices
Cette complexité intrinsèque est déterminée par trois facteurs que sont l’interdépendance, le réseau et la cohérence à terme des données. Voyons en détail de quoi il s’agit :- Interdépendance : Le code global d’une application en microservices est constitué de multiples bases de codes indépendantes. Il est donc plus compliqué de disposer d’une vue d’ensemble de toutes les interdépendances entre les microservices. Il est également plus difficile de réaliser des modifications transverses à plusieurs microservices ou d’étudier leurs impacts. L’application est gérée par plusieurs équipes de développement indépendantes. Nous l’avons vu, chaque équipe devrait pouvoir travailler de façon autonome sur son périmètre. Dans une approche par microservices, les éléments d’un programme sont interdépendants. Il est donc nécessaire que l’application soit globalement cohérente. Dans le meilleur des cas, il faut mettre en place une gouvernance avec une synchronisation à minima entre les équipes.
- Réseau : Les communications entre les microservices sont réalisées à travers des appels distants. Le réseau n’est pas toujours fiable. Il peut échouer puis fonctionner quelques instants plus tard. Chaque microservice devra être capable de gérer tous problèmes de réseau. Par conséquent, les stratégies de résilience déployées vont complexifier le code (exemples de stratégies : retry (2), circuit-breaker (3), mise en cache…).
- Cohérence à terme des données : Le système global est constitué de microservices autonomes sur leurs données. La distribution des données pose alors des problèmes de cohérence qui peuvent être très complexes à résoudre. (4).
Deuxième facteur : le risque de “spaghetti distribué”
Le spaghetti distribué est l’anti-pattern d’une architecture distribuée en microservices. C’est la conséquence de la dégradation dans le temps de la structure d’une application distribuée en microservices. Le spaghetti distribué est un anti-pattern. Il cumule la complexité intrinsèque des architectures distribuées en microservices avec les problèmes d’évolutivité d’une application monolithique spaghetti. L’effort à fournir pour corriger un spaghetti distribué est très élevé :- Construire une vision globale de la structure d’une application distribuée en microservices est plus complexe que pour une application monolithique. En effet, cela nécessite d’agréger les informations contenues dans plusieurs bases de code autonomes. Cela implique donc nécessairement de solliciter plusieurs équipes indépendantes.
- Nous avons mentionné le problème des interdépendances entre les microservices. Les appels entre ces derniers s’exécutent à travers le réseau. Vous seriez bien en peine d’interpréter les chaines d’appels entre les microservices en analysant seulement le code. Il est nécessaire d’analyser les traces d’appels entre microservices, lorsqu’elles sont disponibles.
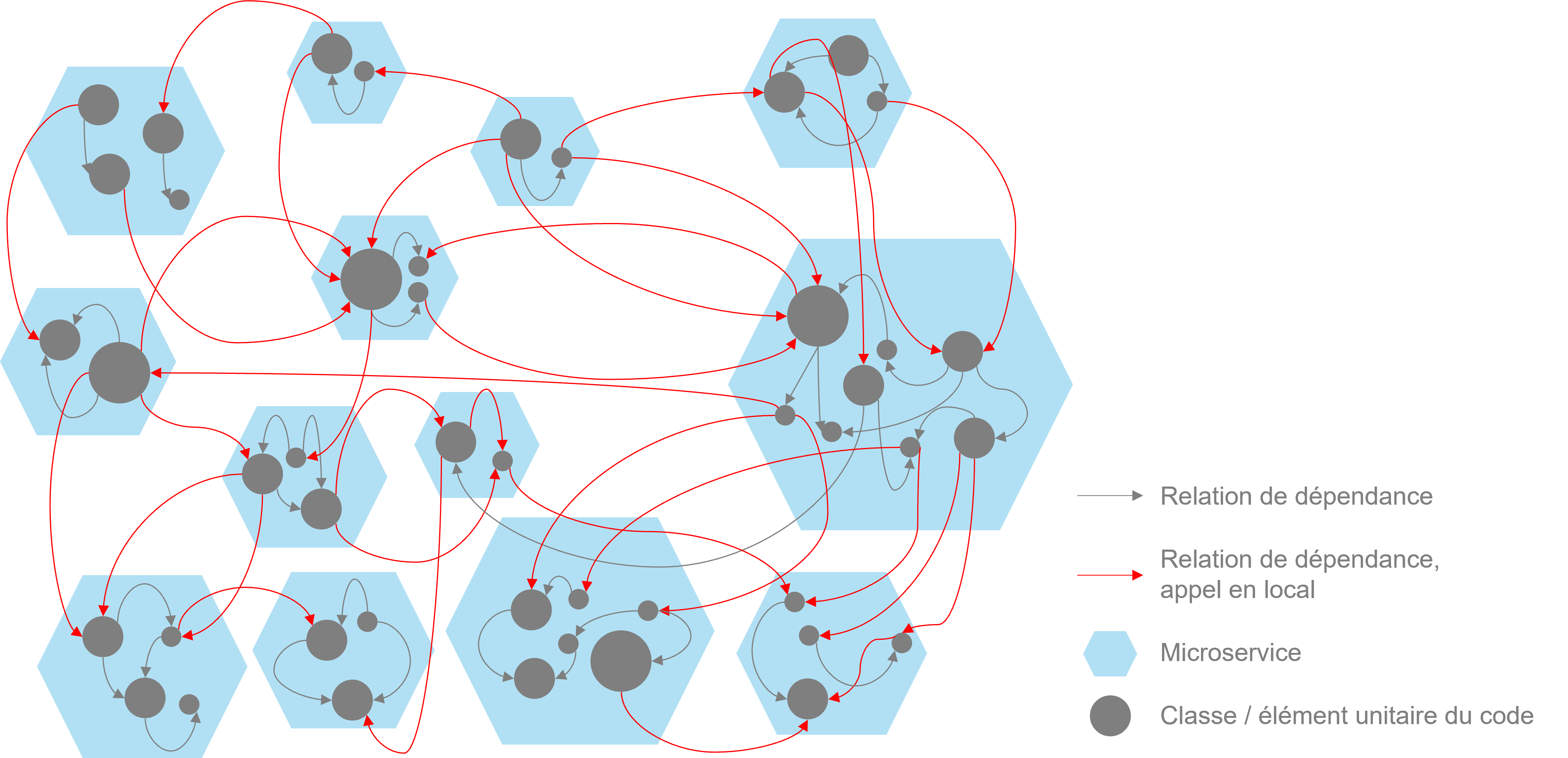
Onepoint – Le spaghetti distribué
Troisième facteur : leur exposition accrue au changement
Manny Lehman, professeur à la School of Computing Science de l’université de Middlesex a contribué à la recherche sur l’évolution des logiciels. De ces travaux, il ressort que chaque modification réalisée sur un logiciel augmente sa complexité et limite ainsi sa capacité future à évoluer. Pour mieux comprendre l’exposition accrue au changement des microservices, une explication sur les lois de l’évolution des logiciels s’impose.Les lois de l’évolution des logiciels de Manny Lehman
En 1974, Manny Lehman (5) a énoncé de façon empirique les trois premières lois de l’évolution des logiciels. De 1974 à 1996, il a affiné ces trois premières lois et les a complétées avec cinq nouvelles lois [voir référence n°2]. Aujourd’hui encore, la théorie de l’évolution des logiciels est un domaine de recherche qui reste à approfondir et à explorer. Lorsque l’on se lance dans la construction de systèmes distribués en microservices, il est important de prendre en compte les lois II, IV et VII :- LOI II : LOI DE LA COMPLEXITE CROISSANTE » – Au fur et à mesure qu’un système de type E[*] est modifié, sa complexité augmente et il devient plus difficile de le faire évoluer, à moins que des travaux ne soient effectués pour maintenir ou réduire la complexité. «
- LOI IV : LOI DE LA CROISSANCE CONTINUE – » La capacité fonctionnelle des systèmes de type E doit être continuellement améliorée pour maintenir la satisfaction des utilisateurs pendant la durée de vie du système.«
- LOI VII : LOI DU DECLIN DE LA QUALITE » À moins d’être rigoureusement adapté et évolué pour tenir compte des changements dans l’environnement opérationnel, la qualité d’un système de type E apparaîtra comme étant en déclin.«
- Nouvelles attentes pour améliorer l’application,
- Nouvelles attentes pour ajouter des nouvelles fonctionnalités,
- Contexte métier qui change pour s’adapter à des nouveaux usages ou à la concurrence,
- Expérimentations et innovation, etc.
Les applications distribuées en microservices : une architecture légitime
L’architecture à base de microservices distribués a été conçue pour favoriser la scalabilité, la résilience et l’évolutivité d’un système. Les applications distribuées en microservices sont souvent créées avec comme objectif principal une réduction importante du time to market. C’est en cela qu’elles représentent une architecture légitime pour remplacer les applications monolithiques en fin de vie. Par nature, les applications distribuées en microservices sont donc particulièrement exposées aux changements. C’est pourquoi leur complexité aura tendance à augmenter beaucoup plus rapidement que pour une application monolithe.Un changement de pratiques s’impose pour les applications distribuées en microservices !
Rappelez-vous, nous avons évoqué l’obsolescence des applications monolithiques. Pour ce qui est des applications distribuées en microservices, attendez-vous à de mauvaises surprises. Leur durée de vie est plus courte. Sauf si vous sautez le pas pour modifier vos pratiques.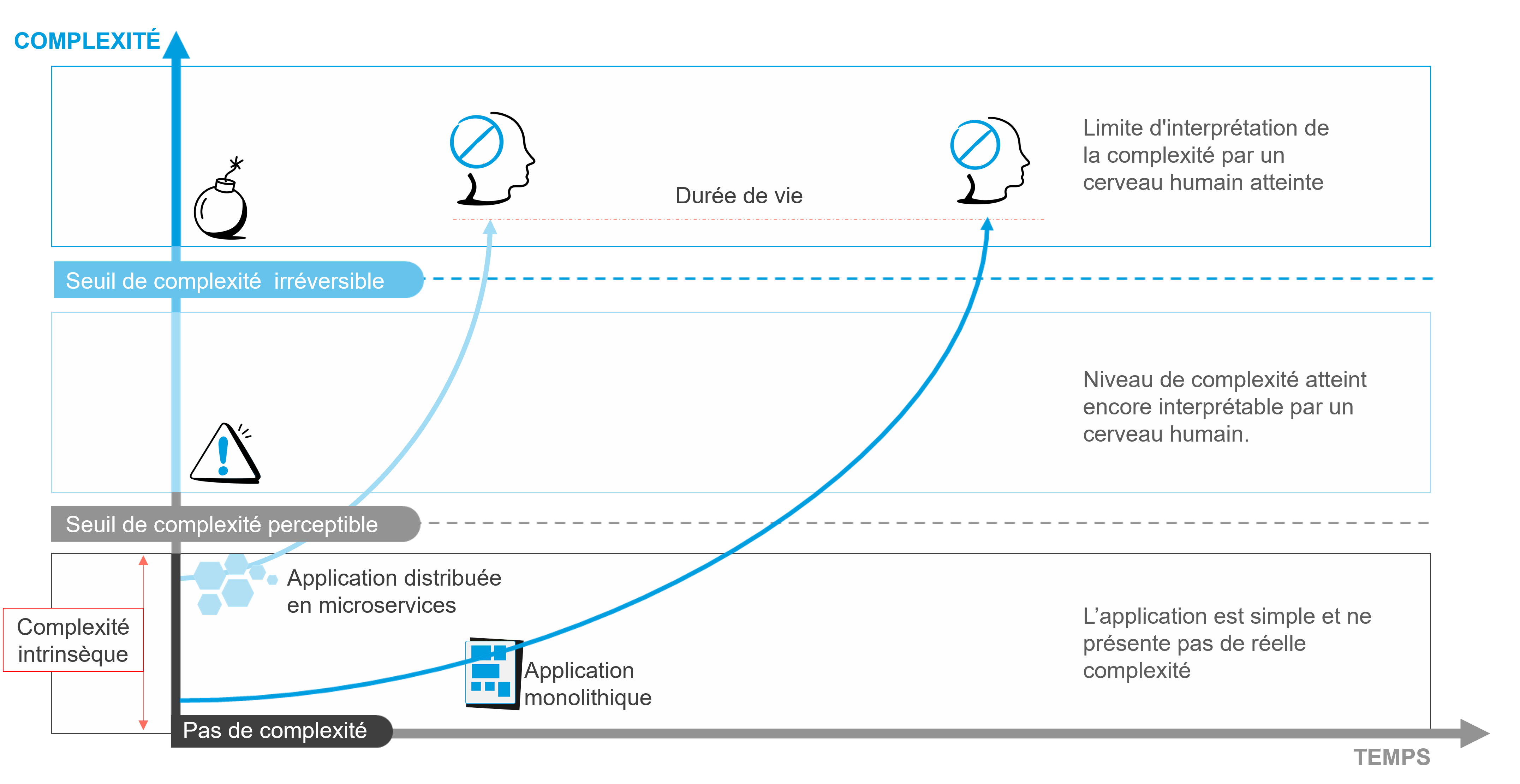
Onepoint – Les applications distribuées en microservices auront une durée de vie plus réduite que les applications monolithiques
Les bonnes pratiques et les patterns ne suffisent plus
L’évolutivité des applications est un enjeu crucial pour les entreprises qui souhaitent favoriser l’innovation et le time to market. Il est donc nécessaire de se mettre en capacité de la favoriser et de la préserver dans le temps. Ce que les pratiques suivies jusqu’à maintenant avec les applications monolithiques ont été incapables d’assurer.Contenir la complexité interne du code est important mais insuffisant
D’après notre analyse, nous nous sommes polarisés sur la complexité interne au code. Nous constatons alors que les bonnes pratiques et les outils de qualimétrie sont clairement insuffisants. Toutefois ces approches doivent impérativement perdurer et être renforcées.Ce qui est indispensable : contenir le niveau d’entropie
L’entropie est la cause de la mort des applications monolithiques. Dès leur création, leur niveau d’entropie a augmenté jusqu’à dépasser le seuil de complexité perceptible, dégradant ainsi leur évolutivité. L’entropie a poursuivi crescendo jusqu’à atteindre le seuil de complexité irréversible, condamnant ainsi l’application. C’est entre ces 2 seuils qu’il aurait fallu agir en lançant des travaux d’amélioration de l’architecture.L’entropie source de dégradation silencieuse des applications
La première raison est que la croissance de l’entropie s’est accrue silencieusement. Les effets qui sont uniquement liés à la hausse de l’entropie très difficilement détectables. Effectivement, ils s’expliquent par plusieurs facteurs : faible qualité du code, manque de moyens et d’encadrement technique, turnover des équipes. La seconde raison est que l’entropie évolue de façon continue et incrémentale, sans sauts brusques. A chaque évolution portée au système, on augmente involontairement le niveau d’entropie. En réalité, le seuil de complexité irréversible ne peut pas vraiment être représenté comme une frontière clairement définie. Le seuil de complexité irréversible se matérialise plutôt comme une zone floue avec des frontières imprécises, sans un avant et un après clairement identifiable.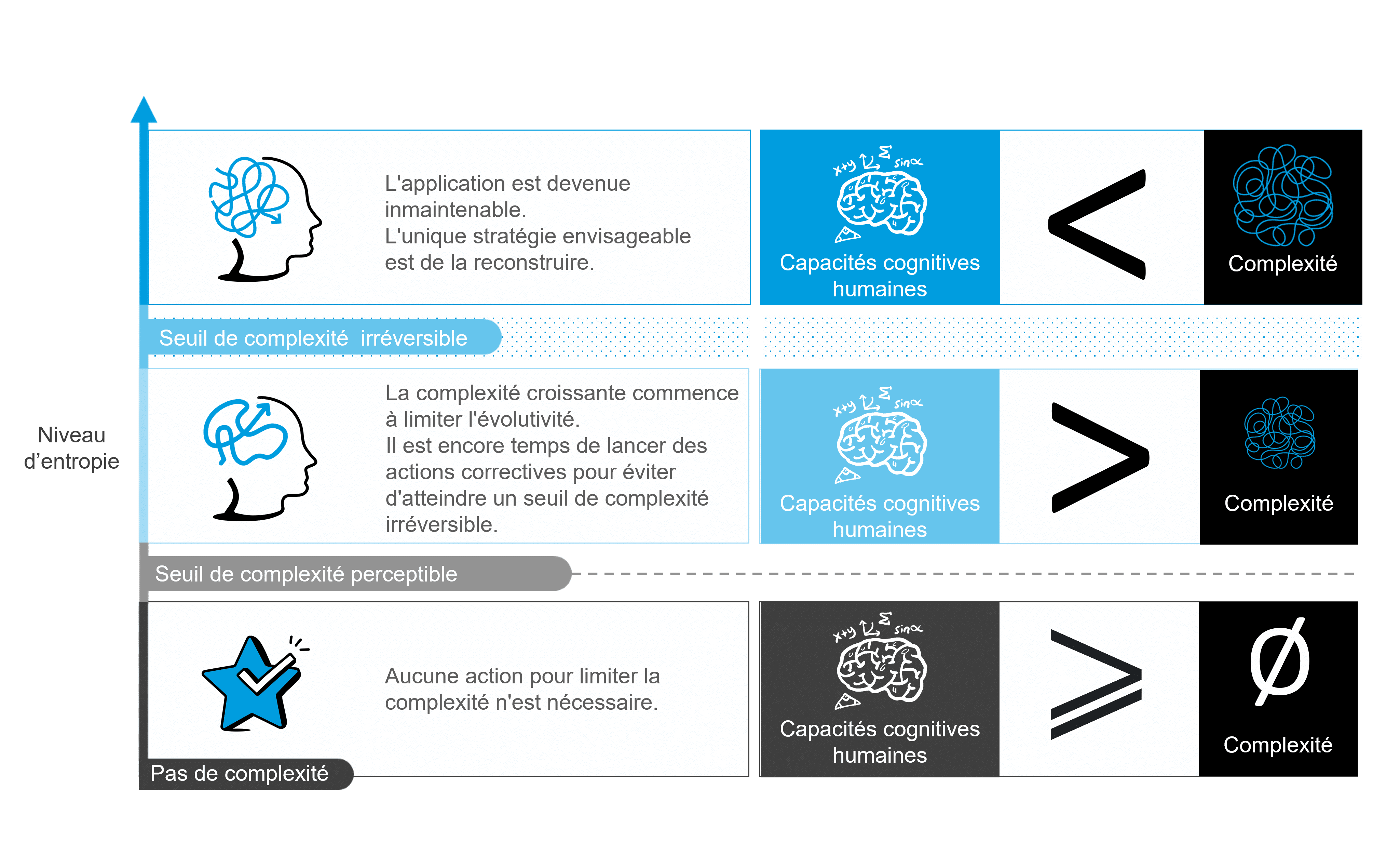
Onepoint – Quand agir ?
Il est nécessaire de suivre dans le temps l’évolution du niveau d’entropie des applications
D’après Peter Drucker « On ne peut pas améliorer ce que l’on ne sait pas mesurer » (6). C’est aussi notre conviction. Notre échec collectif à conserver des applications monolithiques évolutives s’explique donc par notre incapacité à mesurer le niveau d’entropie des applications. Il faut éviter de reproduire cette erreur avec les applications distribuées en microservices. L’enjeu : suivre leur complexité dans le temps. Mesurer l’entropie ne sera pas suffisant. Mais, c’est le prérequis indispensable pour pérenniser l’évolutivité des applications microservices.Surveiller l’entropie aidera à détecter les seuils critiques de complexité
Mesurer et suivre le niveau d’entropie vous aidera à détecter le seuil de complexité perceptible. Dès l’apparition des premières difficultés d’évolution, il faudra vérifier si elles sont corrélées à la hausse de l’entropie. Ce signal nous indique que l’on s’approche du seuil de complexité irréversible. Mesurer l’entropie permettra également de détecter un emballement dans la hausse continue de l’entropie. De façon empirique, nous avons l’intuition que plus le niveau d’entropie augmente et plus sa croissance s’accélère. L’accélération de l’augmentation de l’entropie est donc pour nous une indication que l’on se rapproche du seuil de complexité irréversible. Mesurer l’entropie permettra également de détecter le moindre emballement. L’accélération de l’entropie est une indication capitale. Elle nous informe que nous approchons du seuil de complexité irréversible.N’aggravez pas l’entropie du SI avec les microservices
Les lois de la théorie de l’évolution des logiciels nous apprennent que l’entropie augmentera de façon inéluctable en l’absence de stratégies pour la maitriser. Il faut donc la contenir avant d’atteindre le point de non-retour, à savoir la mort de l’application. Aujourd’hui, les entreprises allouent d’importants budgets pour réécrire leurs applications monolithiques sous la forme d’applications distribuées en microservices. Nous l’avons évoqué, ces dernières sont particulièrement exposées à l’entropie. Ces projets de refonte sont réalisés sur des périmètres iso-fonctionnels, sans ajouts de nouvelles fonctionnalités. Il s’agit de retrouver un réel niveau d’évolutivité et de bénéficier d’un nouveau socle d’architecture. Mesurer et suivre dans le temps l’entropie des applications distribuées en microservices devient donc un enjeu critique. C’est le prérequis pour que leur durée de vie soit au moins aussi longue que les applications monolithiques qu’elles vont remplacer.Gérald Morisseau – Architecte Expert
Notes de bas de page :
- Un contrat de service définit les paramètres et le résultat que va renvoyer un service. C’est un engagement que prend le service vis-à-vis de ses utilisateurs.
- Le Retry est une stratégie que l’on adopte lorsque qu’une requête à échouée à cause d’un problème réseau. Cette stratégie consiste a réémettre la requête (à réessayer)
- Circuit breaker est une stratégie de résilience lorsqu’un service A dépend d’un autre service B. Cette stratégie consiste pour le servcice A à tenter de prédire la panne du service B de façon automatique en fonction de ses temps de réponses. Lorsque le service A détecte que le service B va probablement tomber en panne, il coupe l’envoi des requêtes vers le service B de façon automatique et adopte une stratégie de repli. Voir : Circuit Breaker
- La cohérence à terme désigne la capacité d’un Système distribué à accepter de passer temporairement par un état global incohérent car, après un certain temps plus ou moins long, il est garanti que le système retrouvera un état global cohérent.
- Manny Lehman (1925-2010) est un chercheur et un professeur célèbre pour avoir travaillé sur la théorie de l’évolution des logiciels et formulé les 8 lois de l’évolution des logiciels.
- La citation originale est : « If you can’t measure it, you can’t improve it. »
REFERENCES BIBLIOGRAPHIQUES :
Auteur
-

onepoint
beyond the obvious