MLOps : orchestrer les acteurs, les processus et les outils pour passer du PoC à la production
Le MLOps ou Machine Learning Operations est un concept qui émerge aujourd’hui afin de répondre aux besoins croissants des entreprises de mener des projets de data science. Il s’agit d’appliquer les méthodes et processus modernes de production d’applications aux applications embarquant des algorithmes d’intelligence artificielle.
Afin de mieux comprendre et illustrer le MLOps notre collaborateur bordelais Vincent Lagache, MLOps Engineer, accompagné de Marius Conjeaud, Cloud & Data Architect, vont produire un algorithme de prédiction de popularité d’un titre de Spotify. Ce sujet a été choisi notamment pour l’importante volumétrie des données disponibles.
L’objectif premier d’une équipe de Data Science est de répondre à une question métier (ici, quelle sera la popularité d’un titre qui sort sur Spotify d’ici quelques semaines ?) grâce à la production de modèles mathématiques répondant à un problème (prédiction, classification, …) avec une performance acceptable (dans notre cas, on ne cherche pas à connaître le nombre exact d’écoutes, mais plutôt la tranche dans laquelle il se situera).
À l’issue de la phase exploratoire réalisée au sein de l’équipe Data Science, ce modèle doit être mis en production pour générer de la valeur. Le prototype doit alors évoluer, d’une réalisation de l’équipe de Data Science seule (un algorithme optimisé pour sa performance mathématique), au produit d’une collaboration nécessaire entre différents acteurs : DataOps, Data Science, DevOps, ainsi que les métiers – ceux pour qui le modèle génère de la valeur.
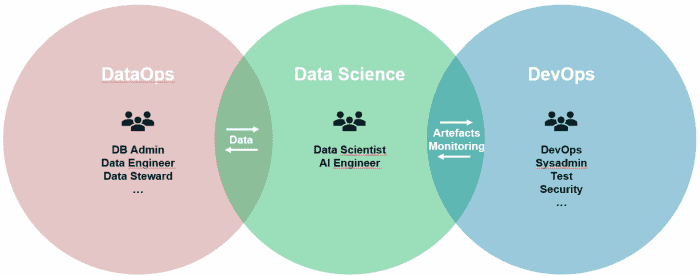
Chacun des acteurs de cet écosystème est à la fois consommateur et fournisseur pour les autres acteurs, par exemple :
- Les DataOps fournissent de la donnée – généralement brute – aux Data Scientists, qui leur en fournissent à leur tour, sous forme raffinée par exemple (feature stores)
- Les Data Scientists fournissent des artefacts (modèle, API, embeddings…) aux DevOps, qui renvoient des informations de monitoring sur le modèle en production.
De leur côté, les clients du modèle fournissent un besoin, ainsi que des règles de gouvernance ou encore des informations sur les données disponibles. En échange, ils attendent un résultat sous la forme d’un « modèle » de Data Science, mais peuvent également exiger un certain niveau d’explicabilité de ce résultat ou encore de la traçabilité.
Pour Marius et Vincent, tout projet de Data Science se doit d’impliquer à terme ces différents profils, ainsi qu’une personne capable de fluidifier les échanges entre ces équipes grâce à sa compréhension des contraintes propres de chacun. Il s’agit du MLOps Engineer : son rôle est réellement transverse au projet, et implique nécessairement de bonnes connaissances techniques sur les différents aspects de la production.
Au-delà de ces aspects humains, le concept MLOps comporte également des aspects process et techniques.
Process & outils : l’automatisation au cœur du MLOps
La problématique du projet consistait à prédire la popularité d’une chanson sur l’application Spotify, quelques semaines après sa sortie. Cependant, le sujet choisi importe peu en réalité, car le MLOps doit pouvoir s’appliquer à n’importe quel projet de Machine Learning (ML).
Le MLOps pourrait se définir par l’application des principes DevOps (automatisation et suivi de toutes les étapes de la création d’un logiciel induisant des cycles de développement plus courts, une augmentation de la fréquence des déploiements et des livraisons continues pour une meilleure atteinte des objectifs économiques de l’entreprise) au ML. Cependant, cette application de principes éprouvés du DevOps doit se faire en intégrant les spécificités inhérentes au ML, comme nous allons le voir.
La Data science est avant tout une affaire d’expérimentation. Il est nécessaire de tester de nombreuses hypothèses (algorithmes, choix des variables, préparation des données…) pour arriver à la création d’un modèle le plus performant possible.
Pour Marius et Vincent, il paraît donc important de pouvoir conserver une trace de ces différentes expérimentations, afin de pouvoir garantir reproductibilité et traçabilité. Les données qui servent à entraîner le modèle vont évoluer dans le temps (par leur nature, leur nombre…) ; il faudra donc s’assurer de pouvoir superviser cette évolution des données et réagir en conséquence, par le réentrainement d’un modèle plus conforme à la réalité du problème à résoudre.
En fait, comme l’illustre cet article : « The moment you put a model in production, it starts degrading » : rien ne garantit qu’un modèle performant sur le plan mathématique aujourd’hui, le restera dans le futur. Il conviendra donc d’ajouter aux tests classiques du DevOps (tests unitaires, de charge…), des tests purement ML : performance prédictive du modèle, data drift… Ainsi, il convient d’avoir une vision à long terme et de ne pas se contenter de la performance d’un modèle à un instant T.
Pour ce projet, nos collaborateurs bordelais ont commencé par réaliser un travail exploratoire « classique » (identification des données disponibles, extraction de ces données, préparation, entraînement de différents modèles, évaluation comparative des modèles) avec les données dont ils disposaient au sein d’un environnement d’exploration (Jupyter notebook), pour réaliser une prédiction la plus performante possible.
Ils nous expliquent : « Dans l’optique où nous souhaiterions mettre le résultat de notre travail en production sans les outils du MLOps, nous devrions fournir aux équipes d’intégration ce que l’on appelle un modèle sérialisé (un fichier .pickle par exemple, qui contient toutes les informations permettant d’intégrer un modèle entraîné à du code existant).
Ces équipes devraient alors l’intégrer manuellement, au sein d’une API par exemple. Cette approche rend difficile l’application des principes que nous évoquons ci-dessus : aucune traçabilité des expériences réalisées, exécution manuelle de chaque étape allongeant les délais et favorisant les erreurs, aucune surveillance du modèle en production, communication entre DataOps, DataScience et DevOps peu fluide par la fourniture manuelle d’un modèle « boîte noire », intégration de nouvelles hypothèses de travail très laborieuses (à moins de versionner ses notebooks, et encore…), aucune livraison en continu. Il ne sera pas possible de s’adapter rapidement aux changements de l’environnement que l’on cherche à prédire.
Pour répondre à toutes ces questions, l’automatisation apparaît alors comme la seule réponse possible. Nous avons donc segmenté l’ensemble des actions de notre code exploratoire en étapes logiques (extraction des données, préparation des données, entrainement du modèle, évaluation du modèle, rapport d’interprétation, enregistrement du modèle), déployées et orchestrées par un pipeline – en l’occurrence, Microsoft Azure ML (d’autres outils existent). Le schéma ci-dessous représente toutes ses étapes, mises en place dans le cadre du projet de prédiction de popularité. »

Ce pipeline étant entièrement généré par du code, cela ouvre la porte à l’intégration et déploiement continus (CI/CD), au cœur des principes DevOps. Un tel dispositif offre les possibilités suivantes :
- Gestion des métadonnées de chaque exécution du pipeline :
- Chaque exécution du pipeline conduit à l’enregistrement de méta données comme le temps d’exécution, la date, la version du dataset (jeu de données) utilisé, la performance mathématique du modèle généré. Cela permet entre autres de garantir la reproductibilité des expériences, de comparer les performances des modèles produits à chaque exécution du pipeline, ou encore de connaitre la nature des données qui ont servi à l’entraînement. Il existe donc une traçabilité complète sur les modèles entraînés.
- Entraînement continu et réactif du modèle :
- Le modèle déployé en production et les données de prédiction qu’il reçoit (exemple : « prédis-moi la popularité de telle chanson de ce nouveau groupe sortie aujourd’hui ») sont surveillés de manière à pouvoir réagir en cas de baisse de performances (dans notre exemple, les goûts musicaux évoluent), d’évolution forte des données de prédiction (dans l’exemple précédent, on nous demande un nouveau groupe, qui possède potentiellement un style « hors norme »), de temps de réponse trop élevés… Il s’agit alors de définir des alertes, qui viendront déclencher l’exécution du pipeline et donc le ré-entraînement d’un modèle, avec ou sans intervention humaine.
- Découplage des composants :
- Un pipeline peut inclure des composants relevant du DataOps (exemple : connexion aux données), de la Data Science (entraînement) et du DevOps (création d’une image Docker). Cela fluidifie donc la collaboration entre ces équipes.
- Cela ouvre également la porte à l’optimisation des temps de calcul et donc des coûts, chaque composant pouvant être exécuté dans un environnement différent, parfaitement adapté à ses besoins.
- Gouvernance :
- Parmi les actions de gouvernance envisageables, on peut citer la vérification automatisée de l’utilisation de données personnelles, la mise en place d’une sécurité différenciée par composants, ou encore la production de rapports complets permettant l’interprétation des modèles produits (par exemple : pour cette version du modèle, l’importance de la variable « danceability » est bien supérieure à celle de la variable « langue des paroles »).
- Mise en place des scénarios de déploiement propres au DevOps : dev/staging/production, canary, test A/B, etc…
Enfin, le pipeline lui-même est intégrable en continu. Comme évoqué ci-dessus, la Data Science est une affaire d’expérimentation. Pour améliorer un modèle en production, on peut donc vouloir intégrer de nouveaux algorithmes, de nouvelles variables, traiter des variables différemment, etc… Cela implique alors des modifications au niveau des différents composants du pipeline, que l’on vient donc intégrer en continu. Le modèle est alors ré-entraîné, testé, déployé, tracé…
En conclusion
Produire des modèles mathématiques répondant à un problème avec une performance acceptable est une discipline difficile, nécessitant des profils spécialisés. Grâce à l’apparition notamment des Data Scientists, nous savons aujourd’hui produire ces modèles. En revanche, la Data Science reste encore trop isolée des autres acteurs de son écosystème, l’IT au sens large, ce qui impacte la valeur à long terme des modèles pour les entreprises, pour les raisons que nous venons de citer. C’est donc ce que proposent les pratiques du MLOps, avec son chef d’orchestre le MLOps Engineer : intégrer et orchestrer les pratiques des équipes DataOps, Data Science et DevOps.

Auteur : Vincent Lagache
Développeur Data / IA, Bordeaux