« Event Driven Architecture » : un modèle d’architecture répondant aux enjeux d’aujourd’hui et de demain
Le besoin d’instantanéité dans le traitement des événements, d’évolutions rapides, de haute disponibilité, de forte scalabilité, d’ouverture vers le monde extérieur nécessite de faire évoluer les modèles d’architecture.
Vers un nouveau modèle d’architecture pour répondre aux problématiques d’aujourd’hui
Les nouveaux besoins pour les SI d’aujourd’hui et de demain
Dans un contexte globalisé de plus en plus concurrentiel, les systèmes d’information doivent pouvoir évoluer rapidement pour être capable de réagir aux changements du marché. La réduction du Time to Market devient un impératif pour répondre rapidement aux offres concurrentes, proposer de nouveaux services et s’adapter à des évolutions de plus en plus rapides de l’écosystème. L’agilité et l’évolutivité du système d’information sont clés pour répondre à ce besoin.[1] Par ailleurs, les applications sont de plus en plus distribuées et connectées. Elles doivent pouvoir supporter des pics de charge importants et être disponibles 24 / 24, 7 jours sur 7. Les modèles d’architecture d’hier ne permettent plus de répondre efficacement à ces nouveaux besoins. Trop lourd, trop fermé, pas assez agiles, ils deviennent un frein au développement de l’activité.Qu’est-ce qu’une application monolithique ?
Nous reprendrons la définition donnée par Gérald Morisseau dans son article Microservices : les risques de l’entropie ! « Une application monolithique appelée aussi monolithe est un modèle traditionnel de conception d’application. Elle correspond à une application qui regroupe un grand nombre de fonctionnalités dans une même base de code qui est packagée puis déployée sous la forme d’une seule unité. Elle peut être conçue de manière modulaire avec des sous-modules internes qui sont déployés et exécutés dans une même unité. Selon la taille de l’application, des équipes de développement importantes et multiples interviennent parfois sur le même code. Cela qui engendre des besoins forts de synchronisation pour éviter des modifications concurrentes impactant une même fonctionnalité[2] ».Applications monolithiques : un modèle en fin de vie
Ce modèle d’architecture permet de déployer l’ensemble des fonctions d’une application sous la forme d’un seul composant. Il présente l’avantage de la simplicité en termes de packaging, de déploiement et de structuration de l’application. C’est un tout-en-un ! On comprend bien pourquoi ce modèle, bien adapté par ailleurs pour développer des applications simples, voir moyennement complexes, a eu autant de succès. Cependant, le besoin d’applications toujours plus complexes, plus ouvertes et plus évolutives a contribué à pousser ce modèle à l’extrême. Les applications ont évolué sans remettre en cause ce paradigme de « tout-en-un », pour aboutir à des entités très complexes et très difficilement maintenables. Une des principales difficultés pour faire évoluer une application est d’identifier les parties à modifier pour changer un comportement spécifique. En effet, les fonctions métier demeurent étroitement imbriquées entre elle ; le code technique et fonctionnel n’est pas séparé. De ce fait, il devient très difficile de maitriser les impacts d’un changement sur les autres fonctions.
Figure 1 – Ou se trouve le code métier à faire évoluer ? (exemple flouté par confidentialité)
Le problème qui se pose est donc un problème de structuration, de modularité et de capacité à évoluer rapidement. Ces défauts structurels rendent difficile les évolutions et le traitement en temps réel des événements. Par ailleurs, le manque de modularité limite la scalabilité et la gestion de la haute disponibilité.Qu’est-ce qu’une architecture évènementielle ?
Une architecture événementielle ou « Event Driven Architecture » est avant tout un système réactif[3] capable de réagir en temps réel à des événements. L’architecture repose sur des composants indépendants et faiblement couplés. Dans une architecture événementielle, les différents composants ne sont pas liés de manière fortement couplée. Ces derniers communiquent en émettant et en consommant des événements. Par conséquent, ils peuvent être développés, testés et déployés de manière indépendante, sans affecter les autres composants. Cela rend ainsi le système plus souple et plus agile. Une architecture événementielle doit être :- Disponible: le système doit continuer à fonctionner en cas d’incident impactant un composant. Chacun doit donc être multi instancié afin de permettre une tolérance aux pannes.
- Scalable: le système est capable de supporter une montée en charge importante sans impact majeur sur l’architecture.
- Résiliente: le système est capable de réagir à un incident afin de rester disponible et de s’auto réparer pour revenir automatiquement à sa capacité nominale.
- Basée sur des composants indépendants et faiblement couplés: Le système est conçu de manière modulaire sous la forme de composants indépendant. Les communications asynchrones basées sur des messages ou des notifications doivent être privilégiées lorsque cela est possible. Les communications asynchrones permettent un couplage lâche entre les composants.
- Orientée message: les composants du système communiquent de manière asynchrone en utilisant des événements. Chaque composant réagi en temps réel aux événements qu’il reçoit ou auxquels il est abonné.
- Les producteurs d’événements
- Les gestionnaires d’événements
- Les consommateurs d’événements
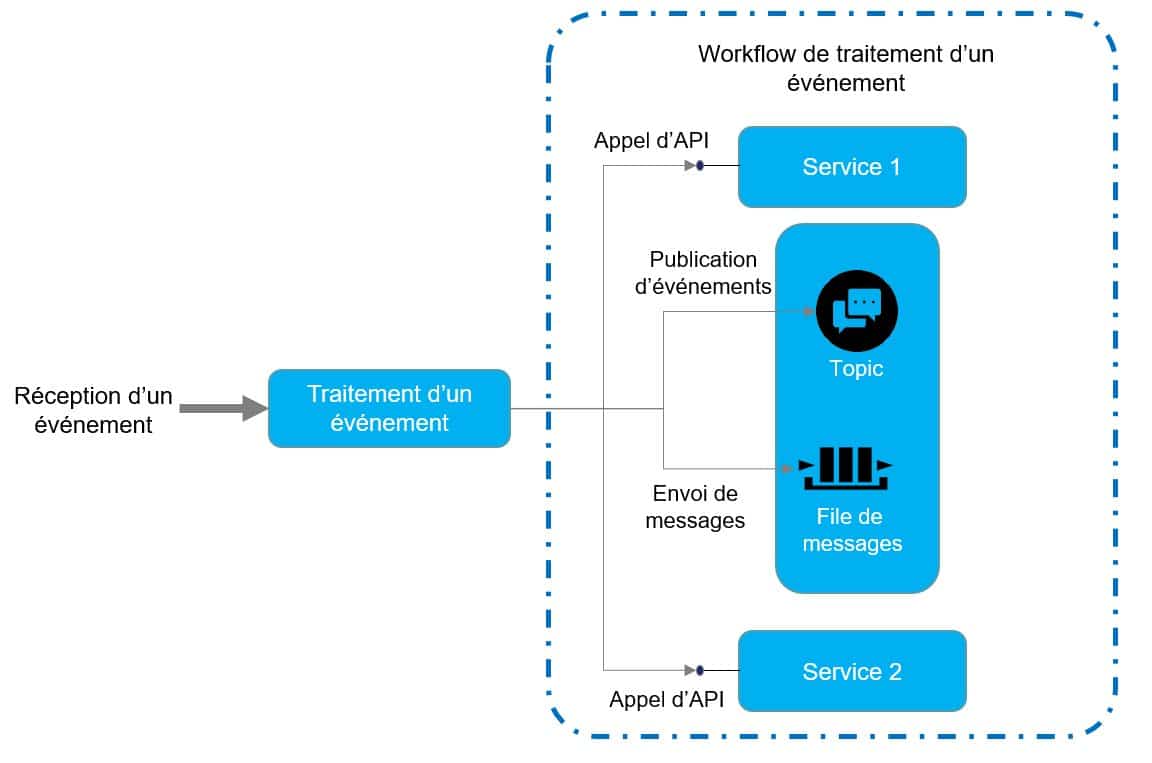
Figure 2 – Composants d’une architecture événementielle
Les différents modèles de publication d’événements
Il existe plusieurs modèles de publication d’événements :- Le modèle Orienté message basé sur l’utilisation de files de messages pour une communication asynchrone entre un producteur d’événement et un consommateur d’événement.
- Le modèle Publish & Subscribe basé sur l’utilisation de Topics, utilisé lorsque qu’un événement peut être traité par plusieurs consommateurs non connus à l’avance.
- Le modèle de streaming d’événements (Event streaming) : généralement utilisé pour publier en continu les changements se produisant sur un système source.
- Les messages sont envoyés dans une file de messages.
- Une file de messages peut être écoutée par plusieurs consommateurs.
- Un message est consommé par un seul consommateur.
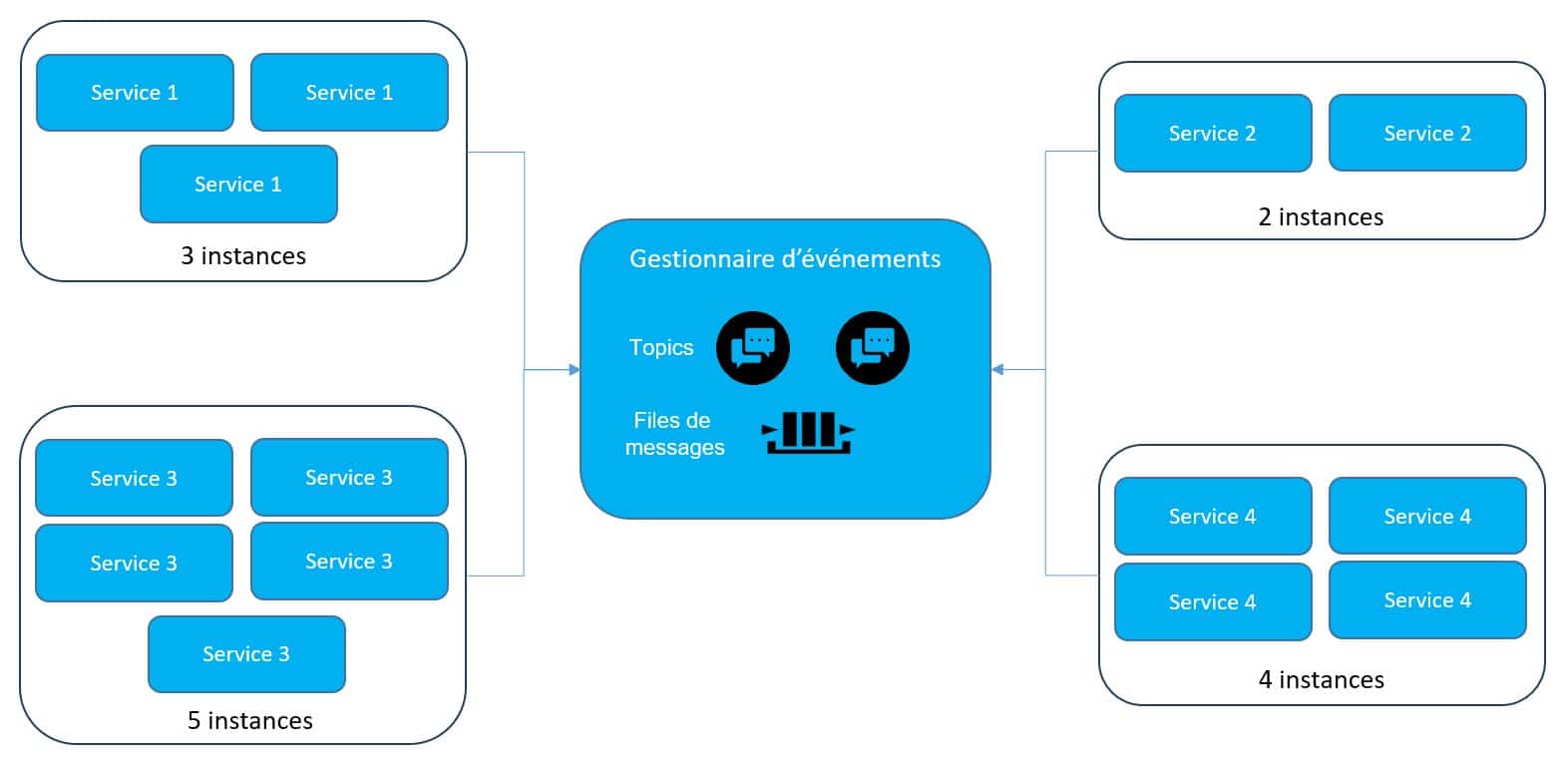
Figure 3 – Modèle orienté message
Modèle Publish & Subscribe :- Les messages sont publiés dans un « Topic» défini dans le gestionnaire d’événements.
- Un Topic correspond à une catégorie d’événements dans lequel les messages sont publiés et stockés. Par exemple « Validation d’une commande» « Création d’un compte », « Réception d’un colis ».
- Tous les consommateurs qui se sont abonnés à ce Topic reçoivent les messages.
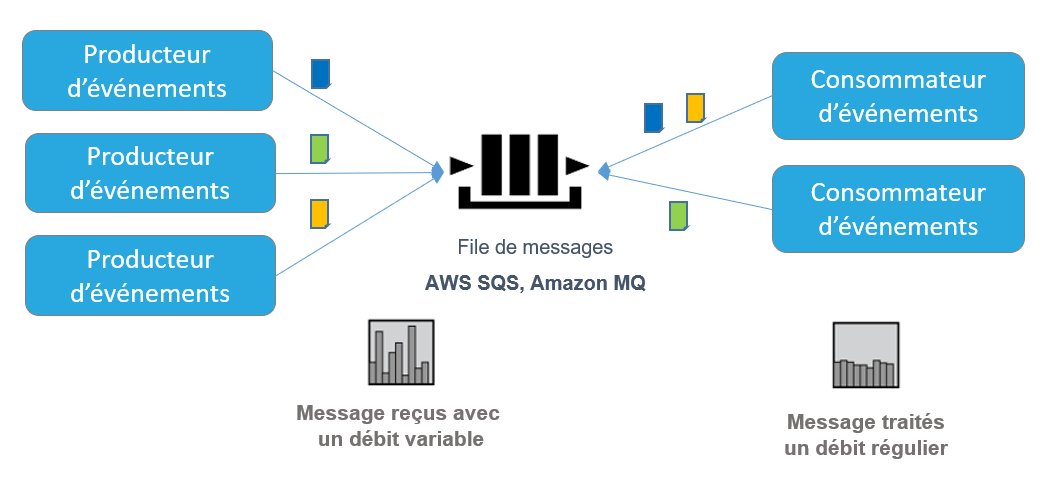
Figure 4 – Modèle Publish & Subscribe
Event streaming:- Le streaming d’événements est généralement utilisé pour propager les modifications survenues sur un système. Par exemple, pour répliquer toutes les modifications survenues dans une base de données ou pour stocker tous les événements générés par un appareil IoT.
- Les systèmes Event Streaming sont conçus pour traiter un très grand nombre d’événements.
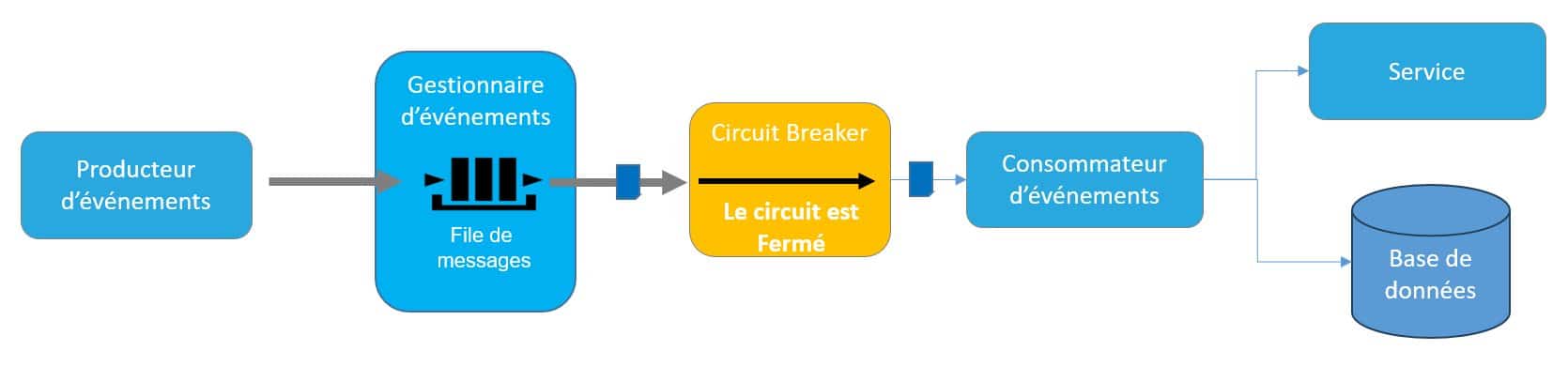
Figure 5 – Modèle Event Streaming
Pourquoi aller vers les architectures évènementielles ?
Une architecture modulaire et évolutive
Par essence, une architecture événementielle est modulaire. Elle est en effet conçue comme un ensemble de composants indépendants qui collaborent par des événements. Grâce à cette modularité il est possible de faire évoluer le système de 2 manières : par ajout de nouveaux composants ou par modification de certains composants existants sans impacts sur le reste du système. Chaque composant peut donc être mis à jour, testé et déployé séparément. Cela simplifie grandement les évolutions et les déploiements. Ceci permet une plus grande agilité dans les développements et une meilleure évolutivité de l’architecture.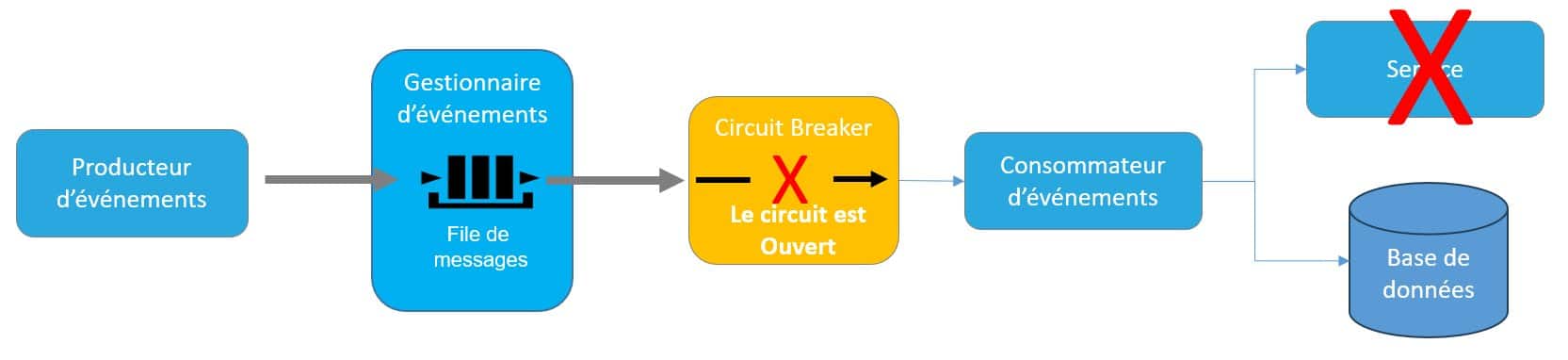
Figure 6 – Une architecture modulaire permettant un déploiement unitaire de chaque composant
Par ailleurs, le modèle Publish & Subscribe, très utilisé dans ce type d’architecture, permet d’ajouter dynamiquement des consommateurs sur un événement donné. Cela rend ainsi possible la mise en œuvre de nouveaux traitements sans impacts sur les composants existants.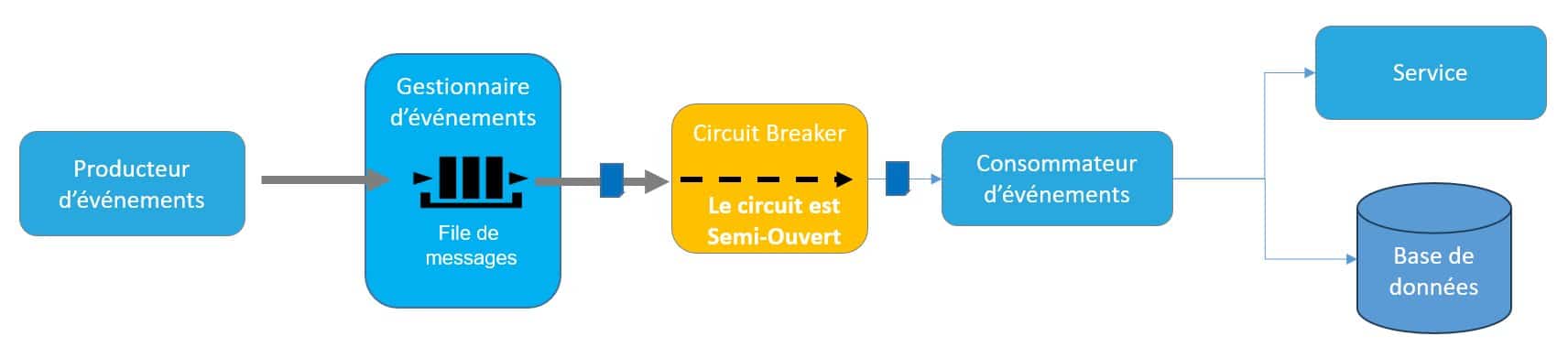
Figure 7 – Modèle Publish & Subscribe
Une interface claire matérialisée par les API exposées
Deux modes de communication peuvent être utilisés dans une architecture événementielle :- Un mode synchrone par appel d’une API exposée par un composant
- Un mode asynchrone par envoi d’un évènement sur un Topic ou d’un message dans une file de messages à destination d’un consommateur d’événement identifié.
Figure 8 – Workflow de traitement d’un événement
Ainsi le traitement d’un événement s’apparente à un workflow plus ou moins complexe d’appel d’API, d’envoi de messages et de publication d’événements. Les API sont un moyen d’exposer un point d’entrée permettant l’exécution d’une fonction métier. Ce mode d’exposition permettant d’exposer les fonctions métier en interne mais également à l’extérieur de l’entreprise s’inscrit tout naturellement dans les architectures événementielles. Ainsi chaque composant doit exposer les API permettant d’interagir avec lui. Cette interface doit être claire, stable et bien documentée. Chaque modification de l’interface doit donner lieu à une nouvelle version. Une architecture événementielle peut exposer deux type d’API :- Les API internes destinées aux communications entre les composants du système. Ces API peuvent être métier ou bien techniques.
- Les API externes exposées au monde extérieur et permettant à des acteurs externes d’interagir avec une application. Ces API sont généralement de plus haut niveau que les API internes et sont principalement des API métiers.
Une meilleure collaboration avec le monde
De par sa nature, une architecture événementielle est conçue pour réagir à des événements. Ces derniers pouvant être d’origine interne ou externe. Ce type d’architecture s’intègre donc très facilement dans un écosystème ouvert. Il permet d’interagir naturellement avec des systèmes ou des acteurs externes. Les interactions peuvent s’effectuer selon deux modes :- Par appels d’API exposées au monde extérieur. On parle d’API externes par opposition aux API internes réservées aux appels entre composants du système.
- Par réception et ou envoi d’événements par le biais de files de messages ou par streaming d’événements.
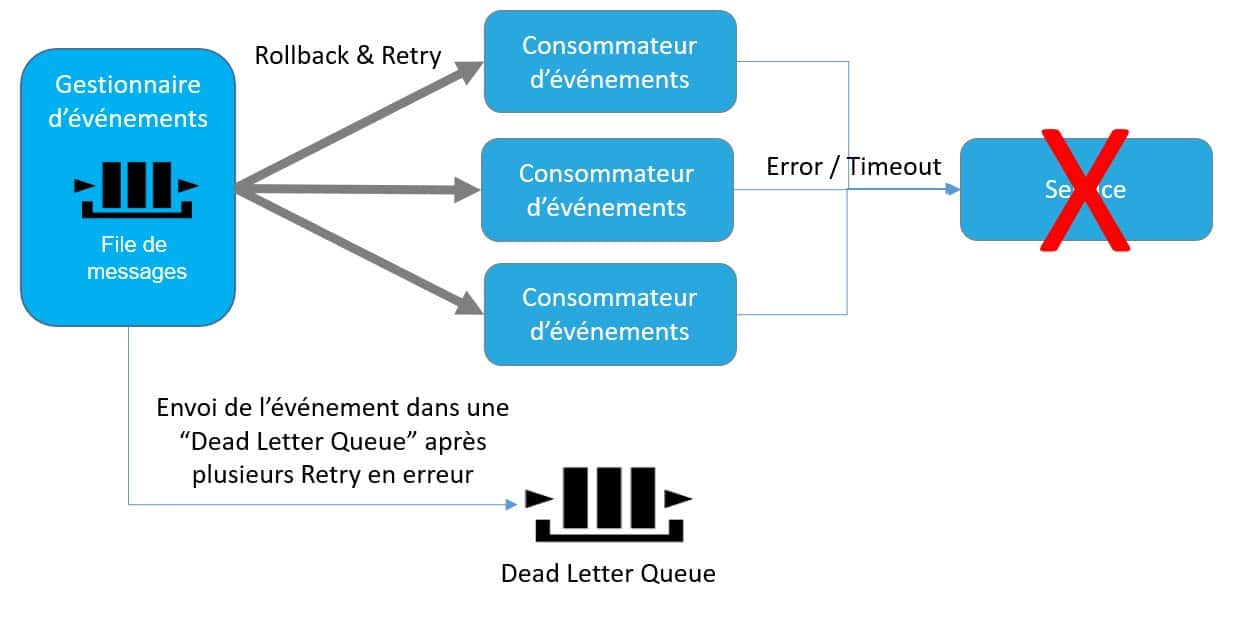
Figure 9 – Collaboration avec les systèmes externes
Un traitement temps réel des évènements
Dans une architecture événementielle, les événements sont traités unitairement et en temps réel contrairement à une architecture orientée batch ou les événements sont traités par lots en différé. Prenons l’exemple d’une demande de création d’un compte d’accès à une application de banque en ligne. Dans une architecture événementielle, le compte d’accès sera immédiatement créé. Il sera dès lors possible de se connecter immédiatement après avoir effectué la demande de création du compte. Dans une architecture traditionnelle orienté batch, la création du compte ne sera effectuée qu’en fin de journée lors de l’exécution du batch de traitement des demandes de création de compte. En tant que client, vous devrez attendre le lendemain pour pourvoir vous connecter. Le traitement temps réel des événements permet par ailleurs d’avoir exactement la même vision quelque que soit le canal d’accès. Ainsi une demande ou une modification effectuée par le biais d’un centre d’appel, d’un mobile ou d’une interface web sera immédiatement visible quel que soit le canal d’accès à l’information.Une forte disponibilité et montée en charge
Chaque composant est redondé, ce qui assure la haute disponibilité, et peut monter en charge sans impact sur le reste du système. En effet, chaque service étant déployé séparément, son nombre d’instance peut varier dynamiquement en fonction de la charge, de manière indépendante des autres services. Pour cela, on peut, par exemple, utiliser des mécanismes d’auto scaling. La haute disponibilité est également accrue par l’usage de modes d’échange asynchrones rendant indépendant le producteur et le consommateur d’un événement.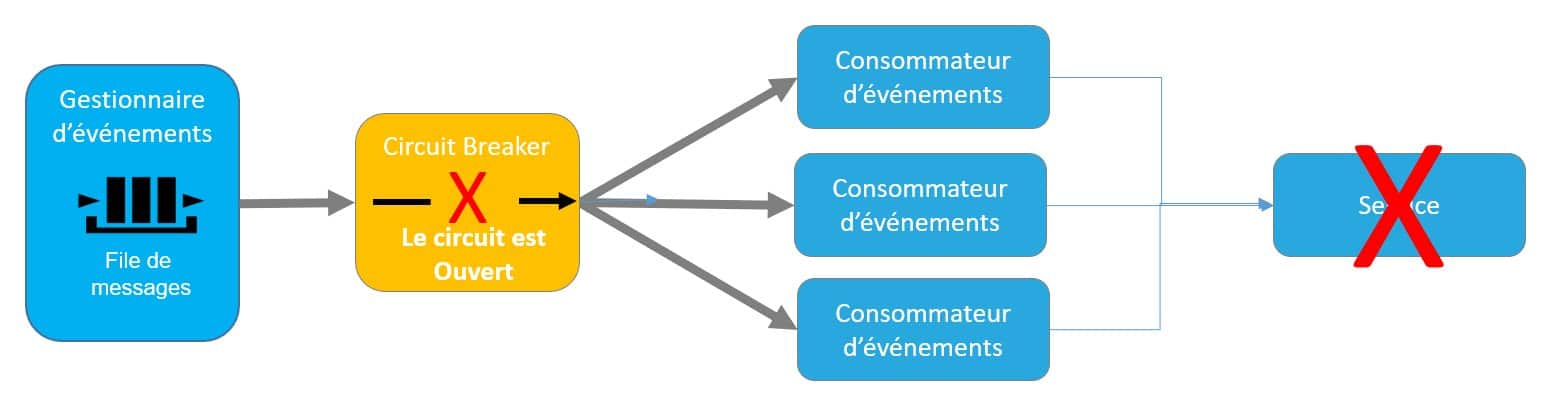
Figure 10 – Exemple d’instanciation dynamique des services
L’utilisation de files de messages permet également de réguler le trafic en maitrisant la vitesse de consommation des messages stockés dans les files. Ainsi lors d’un fort pic de trafic, la file de message joue le rôle de tampon et les messages sont provisoirement stockés dans la file avant d’être consommé évitant ainsi une saturation des backends.Quelles sont les contraintes liées à ces nouvelles architectures ?
Une plus grande complexité liée à la distribution et à l’asynchronisme
Une application basée sur une architecture événementielle est donc composée d’un ensemble de composants et de services indépendants et faiblement couplés qui collaborent par le biais d’événements. Un composant peut donc générer des événements qui seront traités par un ou plusieurs services selon le modèle de publication. Ces services peuvent eux-mêmes produire d’autres événements. Prenons l’exemple d’une validation de commande sur un site de commerce électronique. Le traitement de cet événement peut être effectué par un ensemble de services. Et ces derniers peuvent être distribués sur plusieurs nœuds ou même sur des plateformes différentes.Des traitements distribués plus complexes à analyser
Cette distribution des traitements ainsi que les communications asynchrones entre les composants engendrent :- Une plus grande difficulté à suivre le traitement d’un événement de bout en bout, notamment en cas d’anomalie,
- Une plus grande complexité d’analyse des comportements basés sur un ensemble de composants distribués.
La nécessité de mettre en place des outils d’observabilité
Qu’est-ce que l’observabilité d’une application ? « L’observabilité est la capacité à mesurer les états internes d’un système en examinant ce qu’il produit. »[4] L’observabilité est essentiellement basée sur trois types d’informations :- Les logs: les logs sont utilisés pour identifier les actions effectuées par les composants et services d’une application, en particulier les actions sensibles telles que la mise à jour ou la suppression d’informations.
- Les métriques: les métriques sont utilisées pour mesurer l’état des composants et des ressources systèmes (trafic, temps de réponse, ressources utilisées, …)
- Les traces: les traces sont des informations complémentaires générés par les différents composants sollicités lors du traitement distribué d’une requête et fournissant des informations sur les opérations effectuées ; par exemples les traces générées lors de l’appel d’une API Gateway, ou les requêtes effectuées sur un système de stockage, …
En synthèse
Les architectures événementielles sont aujourd’hui au cœur des applications modernes et notamment des applications Cloud Natives. Ce modèle d’architecture offre de nombreux avantages mais peut également s’avérer difficile à opérer et à monitorer s’il est poussé dans ses extrêmes. Il importe de bien comprendre les limites des architectures événementielles et les pièges à éviter. En effet, il convient de ne pas retomber dans la problématique du plat de spaghetti mais à la sauce événementielle. Quelques principes simples à garder en tête pour concevoir une architecture robuste et évolutive :- Décomposer un système complexe en plusieurs sous-systèmes plus simples.
- Limiter les couplages forts entre les composants : Eviter les appels synchrones entre composants si cela est possible. Préférer les appels asynchrones basés sur la publication d’événements.
- Eviter les workflows complexes difficiles à maîtriser.
- Définir les interfaces d’échange entre les composants. Documenter ces interfaces.
- Versionner les interfaces d’échange en cas d’évolution de l’interface
- [1] Why Is Agility So Important To The Success Of Companies ? , publié le 4 février 2021
- [2] Gérald Morisseau, « Microservices : les risques de l’entropie ! », groupeonepoint.com, 12 avril 2022
- [3] Jonas Bonér, Dave Farley, Roland Kuhn, and Martin Thompson, « Le Manifeste Réactif », reactivemanifesto.org, 16 septembre 2014.
- [4] « Qu’est-ce que l’observabilité ? », splunk.com, 1er mars 2020.
- Figure 1 – Où se trouve le code métier à faire évoluer ?
Auteur
-

Eric Datei
Leader Senior IT Architect - Cloud














