Text2Stories : une solution multi-agent génératrices d’user stories
Comment l’IA assiste le product owner dans ses activités ? Text2Stories propose à cet égard une solution multi-agents qui génère et évalue les récits utilisateurs, les « user stories ». Elles fournissent des résultats comparables et reproductibles pour chercheurs et praticiens.
Acteur, action, valeur : le cadre agile du récit utilisateur
Tout bon projet a besoin d’une boussole pour naviguer dans la complexité. Dans le cas du développement logiciel, les récits utilisateurs, ou « user stories », constituent un artefact indispensable à la conduite d’un projet.
Et les questions devraient nourrir toute note d’intention. Qui sont vos utilisateurs ? Que recherchent-ils ? Pourquoi en ont-ils besoin ? Ces questions contribuent à rédiger un court énoncé qui expriment des exigences non-fonctionnelles du point de vue de l’utilisateur final.
Un exemple concret : « En tant qu’utilisateur de smartphone, je souhaite télécharger des photos sur les réseaux sociaux pour pouvoir les partager. » Cette formulation suit un schéma simple : « En tant que <Acteur>, je veux <Action>, afin de <Valeur> ».

Anatomie d’un récit utilisateur (« user story ») Le récit utilisateur (« user story ») : le standard du monde agile pour transcrire les exigences du point de vue de l’utilisateur final.
Ces récits utilisateurs (« user stories ») rythment ainsi le quotidien des équipes de développement logiciel depuis l’avènement des méthodes agiles. Elles les poussent en somme à réfléchir sur la valeur que le projet apportera.
Monde agile et de l’open source : un fossé bridant les user stories
Sur le papier, cette approche semble d’emblée pourvoyeuse de lendemain qui chante pour tout le monde. Seulement voilà, l’incompatibilité culturelle entre le monde agile et le monde de l’open source donnent du fil à retordre.
Les méthodes agiles qui ont conçues les user stories exigent de la proximité. Grosso modo, les équipes officient et collaborent dans la même pièce, devant un tableau blanc, un mur de post-it ou un ordinateur. Les acteurs de l’open source, au contraire peuvent travailler aux quatre coins du monde. Ils communiquent par écrit de manière asynchrone via des forums ou des plateformes de développeur à l’instar de GitHub.
Ce hiatus entre les deux mondes entrave l’exploitation de données librement accessibles. La grande majorité des projets agiles restent dans les murs des entreprises.
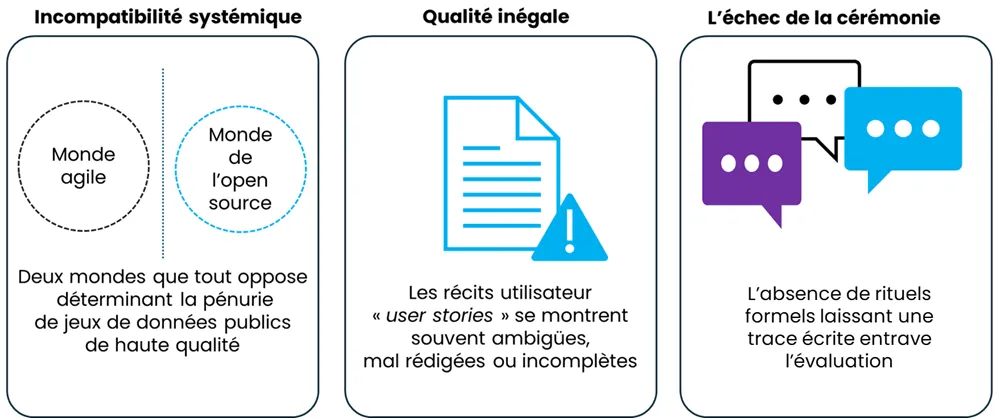
Le monde de l’open source et de l’agile Un hiatus d’écosystème qui entravent l’exploitation de données librement accessibles.
Cela réduit donc la quantité de données publiques disponibles sur les besoins et le développement logiciel.
Quant à dénicher un corpus combinant user stories de qualité, métriques solides et contexte de projet complet, c’est mission impossible.
Le problème commence dès la rédaction. Les user stories sont fréquemment mal formulées. Leur évaluation repose sur des échanges informels et oraux entre développeurs, testeurs et experts métier. Cette cérémonie, dite dans le jargon agile, des « Trois Amigos », est certes utile. Elle est loin toutefois d’offrir la rigueur attendue pour accélérer les méthodes de génération et d’évaluation automatique des user stories.
Text2Stories : orchestrer des agents IA pour générer et évaluer des user stories
La solution IA multi-agents Text2Stories (T2S), conçue pour les praticiens, chercheurs ou Product Owners dénoue cette impasse. Et ce, à partir de simples descriptions en langage naturel.
Là où une IA classique génèrerait une réponse d’un bloc monolithique, T2S orchestre plusieurs agents spécialisés. Et ils travaillent de concert à la manière d’une équipe agile, expert métier, product owner, développeur… Chacun y joue un rôle distinct. Cette division du travail reproduit fidèlement la dynamique collaborative des projets réels.
Pour y parvenir, le système s’appuie sur les LLM, le prompting par chaîne de pensées, les méthodes de Retrieval-Augmented Generation (RAG) et l’architecture d’agent ReAct.
LLM : le socle du système
Les LLM (Large Language Models) constituent le socle du système. Ils comprennent et produisent du texte en langage naturel. Seuls, toutefois, ils manquent parfois de rigueur face aux problèmes complexes.
Chain-of-Thoughts – CoT : le prompting par chaîne de pensées
C’est pourquoi le prompting par chaîne de pensée (« Chain-of-Thoughts – CoT ») ? viennent renforcer cette capacité. Il amène l’IA à raisonner étape par étape. Ce raisonnement progressif améliore la cohérence des résultats et rend les décisions plus transparentes.
Ce raisonnement est ensuite structuré grâce à une communication normée entre les sous-agents. Chaque agent échange selon des règles précises.
Cela favorise l’explicabilité 1 des décisions et la création de sous-objectifs clairs, à la manière d’une équipe qui se répartit les tâches.
Méthodes de Retrieval-Augmented Generation (RAG) : l’ancrage métier
Les méthodes de génération à enrichissement contextuel (« Retrieval-Augmented Generation ») ancrent le système dans la réalité métier. Avant de produire une réponse, l’IA puise dans une base de connaissances pour s’appuyer sur des éléments concrets plutôt que sur des réponses génériques.
Architecture d’agent ReAct : le combo le raisonnement et l’exécution de tâches
Enfin, l’architecture d’agent ReAct équipe les LLM pour alterner réflexion et action. Ils analysent une situation, testent des hypothèses, observent les résultats, puis ajustent leur comportement de façon autonome.
Text2Stories : une équipe agile pour les product owners et chercheur
Le pipeline de T2S s’articule, en effet, en quatre blocs distincts, chacun reproduisant un rôle bien précis d’une équipe agile.
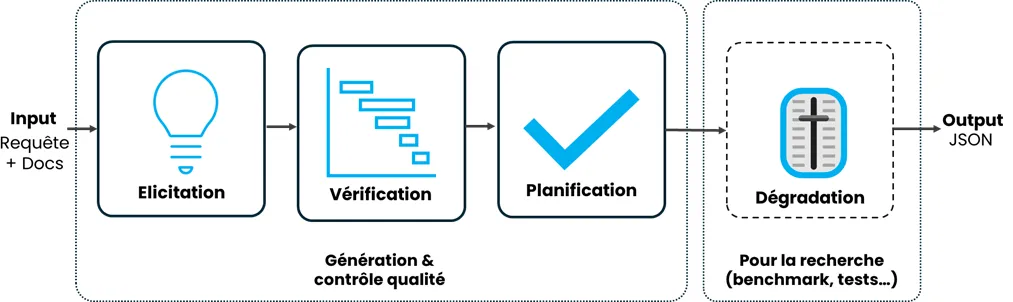
La pipeline Text2Stories reproduit la structure d’une équipe agile réelle. T2S combine raisonnement, collaboration, accès à la connaissance et exploration autonome pour fonctionner comme une véritable équipe Agile assistée par l’IA.
Elicitation : la phase de brainstorming
Tout commence par l’élicitation, une phase de brainstorming structuré. Un agent expert métier épluche la documentation du projet pour y débusquer des besoins potentiels. Un agent product manager prend ensuite le relais, filtre les idées et ne retient que l’essentiel.
Planification : amorce de la collaboration
Vient ensuite la planification (« scheduling »). Le product manager endosse alors son rôle de chef d’orchestre. Il regroupe les besoins en grands chantiers, les « epics ». Il confie ensuit leur rédaction à des agents product owner. Chaque Epic chapeaute ainsi un ensemble cohérent de récits utilisateurs.
Vérification : cérémonie des « Trois Amigos » simulée
Le troisième bloc, la vérification, recrée numériquement la cérémonie des « Trois Amigos ». Ce sont trois agents spécialisés, à savoir un product owner, un testeur qualité et un développeur.
Ces derniers passent chaque user story au crible selon le référentiel INVEST (Independant, Negotiable, Valuable, Estimable, Small, Testable).
Chacun l’examine avec son propre prisme d’expertise, tandis que le prompting par chaîne de pensées (« Chain-of-Thoughts ») facilite le maintien de la rigueur du raisonnement collectif.
Dégradation : une phase utile pour la recherche
Le quatrième bloc peut surprendre par son appellation. Baptisé « dégradation », il mobilise une sorte d’agent vandale, l’evil product owner.
Sa mission consiste à dégrader les user stories de manière contrôlée (selon un ou plusieurs critères INVEST).
L’intention est purement scientifique. En apprentissage automatique, un modèle apprend autant de ses erreurs que de ses succès.
En générant délibérément des exemples défectueux, T2S enrichit considérablement ses jeux de données. Elle forge, pour le meilleur des mondes, des benchmarks et des tests bien plus robustes pour évaluer les outils de demain.
Des user stories enfin claires, cohérentes et exploitables dès l’origine
En fin de compte, Text2Stories combine raisonnement, collaboration, accès à la connaissance et exploration autonome pour fonctionner comme une véritable équipe Agile assistée par l’IA. C’est tout l’enjeu.
Avec la solution Text2Stories, les récits utilisateurs cessent d’être approximatifs, dépendants des échanges oraux et des interprétations individuelles. Elles gagnent en clarté, en cohérence et en fiabilité, dès leur formulation.
Pour les équipes, le bénéfice est immédiat. Moins de zones grises, moins de reformulations successives, moins de débats sans fin lors des rituels agiles. Le temps libéré peut enfin être consacré à ce qui compte vraiment : concevoir, tester et livrer de la valeur.
Pour les product owner, T2S agit comme un copilote intelligent articulé autour de la réécriture automatique, la génération, et l’évaluation.
Pour le premier pivot, l’outil reformule toute exigence brute de manière standardisée, en cohérence avec le contexte global du projet.
Pour le second, une simple description suffit pour que T2S produise un ensemble cohérent d’user stories et de critères d’acceptation.
Enfin pour le dernier pivot, où l’évaluation s’appuie sur la grille INVEST, T2S détecte les faiblesses structurelles d’une story avant qu’elle n’atterrisse dans les mains des développeurs.
Sur le plan de la recherche, pour les chercheurs en ingénierie des exigences et du développement logiciel (Requirement et Software Engineering, RE/SE), Text2Stories lève le verrou de la pénurie de données. L’outil génère des jeux de données synthétiques de haute qualité, utiles pour entraîner et affiner des modèles d’IA comme les LLM.
Evaluation : T2S supérieur aux LLM standards
Nous avons évalué T2S sur trois benchmarks de projets informatiques reconnus, à savoir Trident2, Alfred3 et RETRO4. Face aux méthodes standard que sont le Chain-of-Thoughts et le RAG, T2S affiche des performances supérieures. Ses résultats s’alignent plus fidèlement avec le diagnostic des experts métier, aussi bien sur les métriques INVEST que sur le cadre d’évaluation QUS (Quality User Story Framework5).
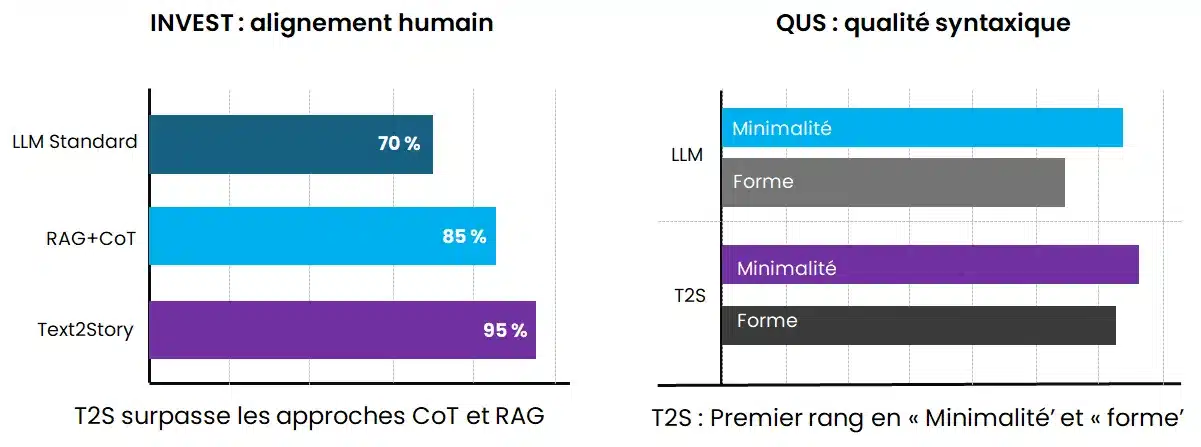
T2S face aux LLM standards : (évaluation menée par un pool de 20 consultants et experts) Le LLM simple s’avère meilleur pour une story isolée (génération courte), tandis que T2S est indispensable pour construire un backlog complet et diversifié.
Ajoutons, qu’en terme de performance, T2S, avec son architecture, se classe juste derrière le LLM simple en termes de qualité brute sur une seule story.
En termes de qualité syntaxique et de respect des règles de gestion, un LLM standard peut obtenir des scores très élevés, se classant parfois premier pour la forme.
Le hic, c’est que ce dernier affiche les pires performances en matière d’unicité. Les redondances foisonnent.
Ce n’est pas le cas pour la solution Text2Stories. Sa capacité à générer des user stories unique et diversifiée est incomparablement supérieure. Il ne se répète pas grâce à ses différents agents qui explore les problèmes sous des angles différents. Il produit un backlog varié complet.
Et ce, tout comme le ferait une équipe humaine complète.
Text2Storie : Un outils open-source pour la génération automatique d’User Stories
L’équipe agile, la cérémonie des trois amigos… T2S constitue une transposition de nos méthodes de travail dans le monde numérique.
Pour des tâches créatives ou complexes d’un logiciel, par exemple, l’IA la plus efficace n’est pas forcément la plus doué en littérature. C’est celle qui imite le mieux un processus de collaboration intelligent. Pour le dire autrement, à ce jeu, certes, T2S ne gagne pas en étant le meilleur écrivain. Il gagne en étant une meilleure équipe.
Vous officiez comme un product owner cherchant à gagner un temps précieux ? Vous êtes un chercheur en quête de jeux de données robustes pour l’avenir de l’ingénierie logicielle ? Alors Text2Stories constitue le pont idéal qui réconcilie enfin la documentation technique et l’agilité réelle.
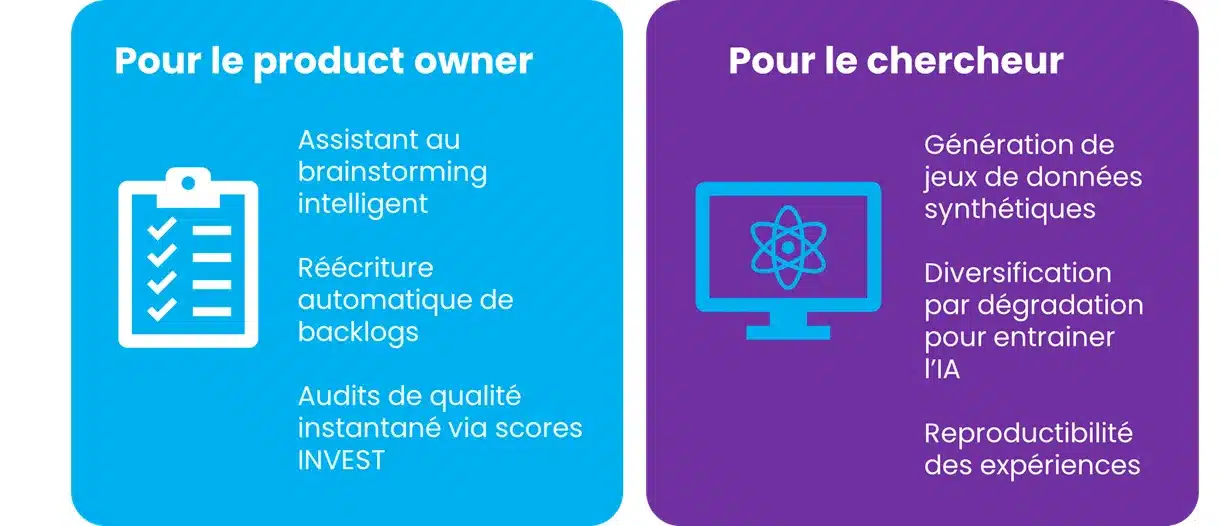
Cas d’usages pour l’industrie et la recherche
Notre outil (Text2Stories) est disponible sous licence open-source sur notre dépôt GitHub et supporte les products owners et les chercheurs en RE/SE et NLP
- Les Product Owners pour l’écriture réécriture ou la réécriture automatique d’US dans un contexte donné, ou encore évaluer la qualité des éléments existants.
- Les Chercheurs en RE/SE et NLP afin de générer des jeux de données synthétiques pour l’entraînement, l’évaluation, la reproductibilité, ou le Finetuning des LLM.
Contributeurs
Vulgarisation et rédaction du texte « Text2Stories : Extraction et Génération de User Stories à partir de Documentation Fonctionnelle et Non-Fonctionnelle » : Marius Ortega et Serge Bouvet.
Papier de démonstration présenté à la conférence EGC 2026 par Marius Ortega, Hassan Imhah, Vanande Khatchatrian, Nédra Mellouli, Christophe Rodrigues et Nicolas Travers.
Références
- 1. Sur l’explicabilité, se référer à l’étude : Antoine Saillenfest, « Explicabilité et machine learning : renforcer la confiance des utilisateurs », groupeonepoint.com, 2025. ↩︎
- 2. Trident désigne une chaîne de génération de données exploitées pour renforcer la sûreté des modèles de langage. Xiaorui Wu, Xiaofeng Mao, Fei Li, Xin Zhang, Xuanhong Li, Chong Teng, Donghong Ji, Zhuang Li. « TRIDENT: Enhancing Large Language Model Safety with Tri-Dimensional Diversified Red-Teaming Data Synthesis », harxiv.org, 30 May 2025. ↩︎
- 3. ALFRED est un benchmark de recherche en intelligence artificielle. Cela consiste à apprendre à relier des instructions en langage naturel à des séquences d’actions dans un environnement visuel interactif. Autrement dit, le modèle doit comprendre des phrases comme “Rince la tasse et place-la dans la machine à café” et produire une série d’actions correspondantes. C’est un jeu de test utilisé dans le domaine de l’IA pour mesurer la capacité d’un système à comprendre des consignes complexes intégrant langage et perception visuelle. « ALFRED : A Benchmark for Interpreting Grounded Instructions for Everyday Tasks », arxiv.org, 2019. ↩︎
- 4. Dans le contexte de l’IA et des LLM (modèles de langage), RETRO est un modèle de langage développé par DeepMind. Il est connu pour introduire une forme de génération à enrichissement contextuel. Il combine la génération de texte avec un mécanisme de recherche dans une grande base de passages. Il améliore ainsi la qualité des prédictions. « RETRO Model », nvidia.com, 2025. ↩︎
- 5. QUS (« Quality User Story Framework ») est un cadre d’évaluation dédié à la qualité des user stories, issu de la recherche en génie logiciel. Il sert à mesurer si un récit utilisateur est bien construit selon différents critères. Cette grille de lecture structurée s’est imposée comme une référence dans les publications académiques du domaine. Garm Lucassen, Fabiano Dalpiaz, Jan Martijn E. M. van der Werf, Sjaak Brinkkemper, « Improving agile requirements: the Quality User Story framework and tool », springer.com, 01 April 2016. ↩︎
Auteur
-

Marius Ortega
Doctorant en Intelligence Artificielle
-

CES 2026: Les 5 points à retenir
Article













