Augmenter les IA génératives sur étagère à l’aide de services et de connaissances contextuels
Si les aptitudes d’agents conversationnels généralistes tels que ChatGPT ou Bard sont désormais largement reconnues, les techniques disponibles pour construire des applications d’IA génératives adaptées au contexte d’une organisation demeurent encore largement confidentielles. L’objectif de cet article est de proposer un tour d’horizon des techniques disponibles pour contextualiser une IA générative par l’intégration de données externes et de services spécialisés dans son modèle de langue.
Le défi de la customisation des LLM
Que vous cherchiez une suggestion d’itinéraire pour votre prochaine escapade en Toscane, un résumé du rôle des principaux personnages de la Comédie humaine ou une explication succincte des concepts de l’informatique quantique, ChatGPT sera pour vous le compagnon idéal. Quel autre interlocuteur pourrait se targuer d’être tout à la fois omniscient, synthétique dans ses réponses et d’une patience à toute épreuve ? Bien sûr, comme chacun le sait, il vous faudra faire preuve d’un peu de discernement et ne pas prendre systématiquement toutes ses réponses au pied de la lettre.
Si vous envisagiez en revanche d’automatiser le service après-vente de votre entreprise, ni ChatGPT, ni ses challengers ne seront hélas d’une grande utilité pour vous. Pire, l’utilisation d’une IA générative sur étagère pourrait même porter préjudice à sa crédibilité ou à son image. Entrainé fin 2021, ChatGPT n’aura par exemple qu’une connaissance obsolète de votre catalogue produits si celui-ci a été mis à jour ultérieurement. Par ailleurs, la tonalité dominante de ses conversations, celle d’un étudiant modèle qui adopte une neutralité didactique un peu obséquieuse, pourrait mal refléter l’image de marque que vous souhaitez promouvoir. Enfin, de temps en temps ChatGPT pourrait se prendre à inventer des produits qui n’existent pas dans votre catalogue ou estimer le prix d’un service de manière fantaisiste.
L’idéal pour automatiser votre SAV serait naturellement de parvenir à concilier les aptitudes conversationnelles de ChatGPT (ou celles de tout autre LLM) avec la précision factuelle que sont en droit d’attendre vos clients. Le ton des conversations devrait aussi être adapté pour établir une relation en harmonie avec les valeurs de votre entreprise. De même le vocabulaire métier utilisé devrait être précis afin de véhiculer une image de compétence. Enfin, lorsqu’un client sollicite une estimation de prix, celle-ci devra impérativement être correcte et si possible même être interprétable. Pour cela et pour prendre en compte une multiplicité d’options le LLM devrait avoir accès d’une part à la dernière version du catalogue produits ainsi qu’à un module de calcul de prix . Il devrait d’autre part être capable de s’inspirer d’exemples de conversations de références entre un expert métier de votre entreprise et un panel de clients.
La problématique générale, on le voit, est celle de l’intégration de données et de services propres à une organisation dans un LLM généraliste. On parle parfois d’Augmented Language Model (ALM) pour désigner de tels systèmes [1,2,3]. Les motivations pour procéder à cette augmentation sont multiples :
L’intégration de données externes peut en effet contribuer comme on le verra à :
- améliorer la précision factuelle des réponses et en particulier bannir les hallucinations dont sont coutumiers les LLM,
- alléger le poids (=nombre de paramètres) des LLM en les dispensant d’avoir à incruster dans leurs paramètres une liste des connaissances factuelles comme résultat d’une longue et coûteuse phase d’entraînement,
- faciliter la mise à jour sans délai de connaissances externes au LLM,
- identifier des sources pertinentes pour se conformer à une règlementation qui exige la mention de références précises,
- ajuster le style et le vocabulaire d’une conversation ou le format de sortie d’une réponse,
- protéger la confidentialité pour autant que l’on choisisse de confier toutes les données sensibles à un LLM privé.
L’intégration d’outils externes peut quant à elle contribuer à :
- expliciter le raisonnement logique qui a mené à une réponse en offrant la possibilité d’examiner la trace des outils invoqués, là encore pour satisfaire des contraintes règlementaires de traçabilité des traitements,
- garantir l’exactitude d’un calcul ou d’une estimation en les déléguant à des services au comportement déterministe,
- intégrer des données externes !
Dans les deux sections qui suivent nous examinerons les principales stratégies qui autorisent l’un ou l’autre type d’intégration. Nous décrirons ensuite LangChain, un framework récent qui permet de modulariser et d’industrialiser la conception d’applications d’IA générative. Enfin, nous conclurons sur quelques remarques de prospective.
Quelles options pour intégrer des connaissances externes ?
En les classant par ordre croissant de coût de calcul on peut distinguer trois approches pour intégrer des données externes dans un système d’IA générative basé sur un LLM. Pour simplifier la discussion nous considérons dans la suite que des connaissances ne sont que des données mises en contexte, typiquement par un corpus de documents.
Le Retrieval Augmented Generation
Imaginons un client interrogeant un SAV pour obtenir des informations sur un certain type de produits. Pour augmenter les chances qu’un LLM génère une réponse factuelle, l’approche dite par Retrieval Augmented Generation (RAG) [4,5] préconise de construire le prompt soumis au LLM en concaténant une liste de documents pertinents (des fiches produits tirées d’un catalogue p.ex) à la requête du client. On peut donc envisager RAG comme une forme de prompt engineering automatisé.
Le nombre de documents qu’il est possible d’inclure dans un prompt est bien sûr limité par la taille maximale de la fenêtre en entrée du LLM. Pour cette raison on intègre rarement des documents dans leur totalité mais uniquement certaines parties que l’on appelle des chunks. Ce découpage a aussi l’avantage de permettre une localisation plus fine de l’information.

Le composant principal d’un système RAG est une « vector database ». Pour constituer cette base, chaque chunk de chaque document est préalablement converti en une représentation numérique, appelé un embedding, par un encodeur sémantique (comme un Transformer). Chaque chunk est alors associé dans la vector database à son embedding conçu comme une clé d’accès. Lorsqu’une requête parvient au système elle est également convertie, par le même encodeur, en un embedding. Les chunks les plus pertinents, ceux que l’on va ajouter au prompt, sont ceux dont la similarité sémantique avec celle de la requête est la plus importante. Techniquement cette similarité coïncide avec l’angle entre la représentation de la requête et celle d’un chunk. Le lecteur qui souhaiterait une compréhension approfondie et opérationnelle de l’approche RAG pourra consulter cet exemple de code commenté.
Cette approche RAG est particulièrement indiquée lorsqu’il s’agit d’intégrer une base de connaissance dans les réponses générées par un LLM et ainsi limiter ses hallucinations. Un autre atout est qu’elle autorise la mise à jour de cette base de connaissances sans avoir à passer par une couteûse phase de réentraînement. Enfin, l’approche RAG favorise aussi l’interprétabilité dans la mesure où l’on peut citer explicitement la liste de documents ou des chunks que le modèle a sélectionnés pour élaborer sa réponse.
Le Fine-Tuning
La technique de Fine Tuning (FT) consiste à spécialiser un LLM généraliste en ajustant ses paramètres lors d’un entraînement supervisé consécutif à son entraînement initial (effectué, rappelons-le, sur la tâche de prédiction du prochain token [6]). La tâche utilisée pendant la phase de FT est typiquement une tâche spécifique (« downstream task ») dont on souhaite améliorer les performances. La traduction, le résumé ou la capacité à répondre à des questions ouvertes (Q&A) en sont les exemples les plus courants. L’expérience montre que le succès de cette phase d’ajustement est largement tributaire de l’utilisation d’un corpus de qualité. Celui-ci doit en particulier contenir une diversité d’exemples assez importante. Sa volumétrie reste cependant typiquement plusieurs ordres de grandeurs en-dessous de celle du corpus utilisé durant l’entraînement initial du LLM (qui est à l’échelle d’internet pour les plus gros modèles).
Rappelons au passage que les systèmes comme ChatGPT se fondent sur des LLM qui ont subi durant leur entraînement une phase de FT destinée à leur conférer un comportement conversationnel qui n’est pas acquis pour les LLM non ajustés [6].
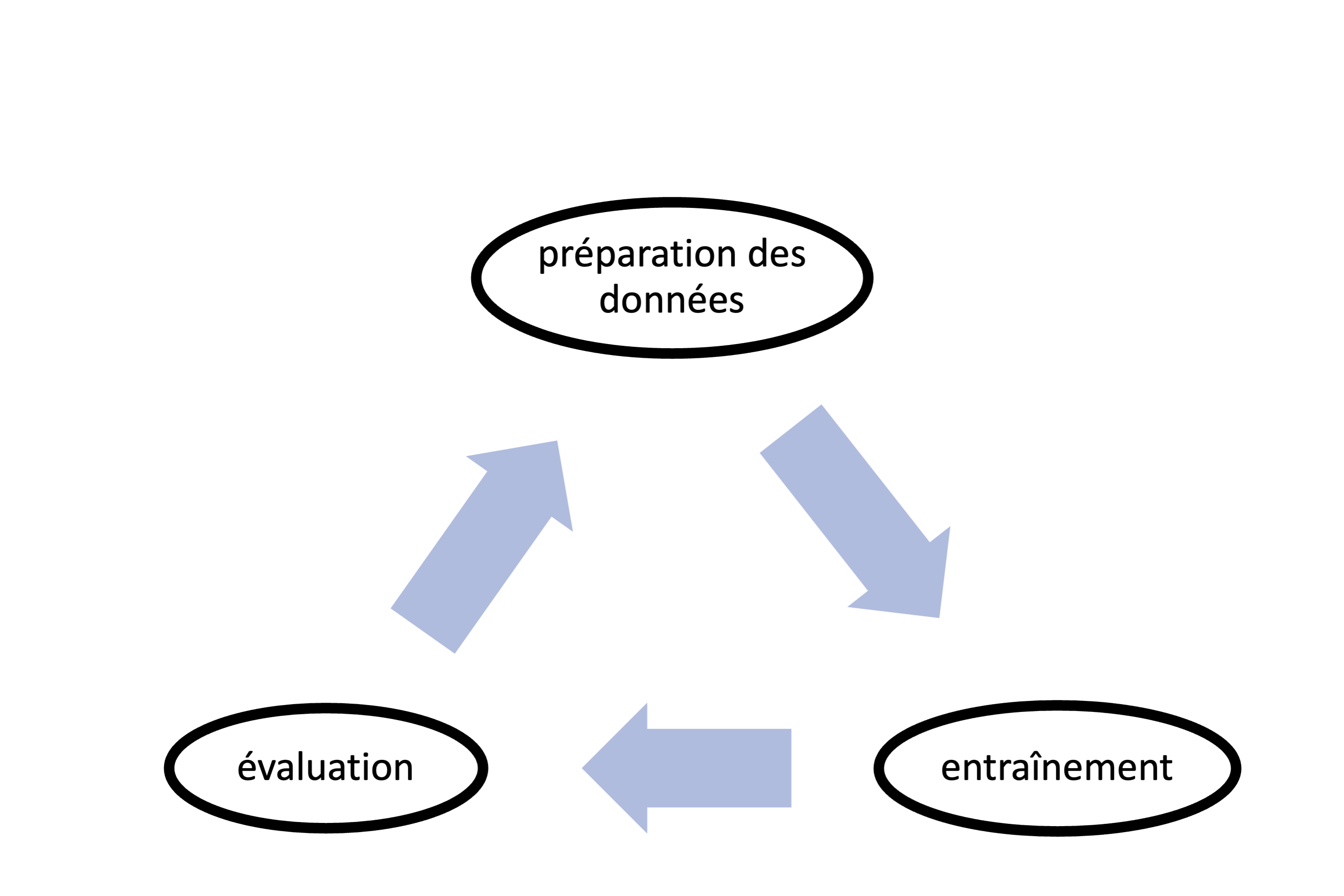
D’une étape de FT on peut attendre d’une part un ajustement du comportement d’un LLM, comme l’adoption d’un certain style rédactionnel, d’un format de sortie ou l’usage d’une terminologie précise, et d’autre part un enrichissement des connaissances par la mise en contexte de données.
Les gros modèles commerciaux comme GPT-3.5 (et bientôt GPT-4) proposent la possibilité de fine-tuner leurs modèles via des API propriétaires. Le modèle lui-même, propriété de l’éditeur, demeurera cependant inaccessible. La facturation se fait par token, à l’entraînement comme à l’usage.
La communauté open source met à disposition quantité de LLM de toutes tailles que l’on peut soumettre à un FT, LLama 2 de Meta étant vraisemblablement le plus populaire. Techniquement et computationnellement plus exigeante que l’approche RAG, le FT ne sera pas nécessairement accessible à toutes les organisations. La constitution d’un bon jeu de données exige par exemple des compétences avancées en préparation de données (tokenisation) et l’ajustement des poids du RN ne peut pas se faire naïvement. Des techniques récentes comme LoRA (Low Rank Adaptation) [7,8] réduisent cependant de plusieurs ordres de grandeurs le nombre de paramètres à ajuster durant le FT. Pour les matheux, l’idée de LoRA part de l’hypothèse qu’il est suffisant d’ajuster chaque matrice de poids d’un RN en lui ajoutant une matrice de rang faible. Pour les non-matheux, cette technique est désormais disponible sur étagère via à l’API Parameter-Efficient Fine-Tuning (PEFT) de Hugginface.
En résumé l’approche par FT s’avère un bon choix lorsqu’il s’agit de modifier le comportement d’un LLM et que des données de qualités sont disponibles à moindre coût. Si le LLM ajusté est suffisamment léger et peut-être hébergé localement l’approche FT bénéficiera également à la confidentialité en évitant la dissémination de données d’entraînement sensibles. Elle minimisera aussi les coûts d’exploitation et évitant d’avoir à recourir à un LLM commercial facturé au token.
Enfin, rien n’empêche bien sûr de combiner FT, RAG et prompt engineering, l’expérience démontre même que c’est souvent la meilleure solution.
Le préentraînement sur des données spécifiques
Au vu de l’énormité des ressources matérielles nécessaires (on parle de milliers de GPU et de péta-octets de données), il n’est guère envisageable pour une majorité d’entreprises d’entraîner un LLM à partir de zéro. Il existe toutefois des modèles spécialisés, entraînés sur d’immenses corpus spécifiques. Citons BloombergGPT pour la finance et Med-PaLM 2 pour la médecine.
Quelles options pour intégrer des outils externes ?
Conditionnés par l’expérience de nos conversations avec ChatGPT ou avec Bard la plupart d’entre nous imagine les LLM comme de vastes bases de connaissances que l’on peut interroger en langage naturel. Une autre manière de voir cependant, plus féconde dans la perspective de les utiliser comme briques constitutives d’applications génératives, est de les concevoir comme des moteurs de raisonnement.
Malgré les défaillances inhérentes à leur nature probabiliste, les LLM sont dotés d’un remarquable sens commun qui en fait des composants extrêmement versatiles. Ces aptitudes au raisonnement peuvent par ailleurs être conditionnées et renforcées par différentes techniques de prompt engineering. Celles-ci sont aujourd’hui l’objet de nombreux travaux de recherche qui élaborent les techniques d’intégration d’outils externes qui nous intéressent ici. Le fine tuning peut également être mis à contribution. Nous examinerons l’un et l’autre dans cette section.
Sélectionner les bons outils
Commençons par énumérer quelques outils susceptibles d’augmenter la fiabilité et les aptitudes au raisonnement d’un LLM :
- les accès à une base de connaissance comme Wikipédia ou une base de données relationnelles,
- les modules de calcul arithmétique ou symbolique (p.ex. Mathematica),
- les moteurs d’inférence logique (p.ex. Prolog),
- les moteurs de recherche pour accéder à l’actualité (p.ex. Google, Wikipédia),
- les interpréteurs de code informatique (p.ex. Python, Javascript ou C++),
- les commandes de robots,
- et finalement n’importe quelle API !
Il existe deux options pour inciter un LLM à sélectionner le meilleur outil à l’aide d’un prompt.
La première consiste à incorporer quelques exemples d’utilisations pertinentes dans le prompt, une technique qu’on désigne communément par les expressions few-shot learning ou in-context learning.

Chaque exemple d’invocation d’outil dans le prompt est désigné par le nom d’une méthode à utiliser et par la liste des paramètres à lui transmettre. L’utilisation d’un formatage rigoureux des exemples est recommandée pour faciliter la tâche des parseurs chargés d’analyser syntaxiquement la réponse produite. Une fois que les outils ont produit leurs réponses celles-ci sont incorporées à l’historique de la conversation qui sera retransmis au LLM qui poursuivra la génération jusqu’à la vérification d’un critère d’arrêt.
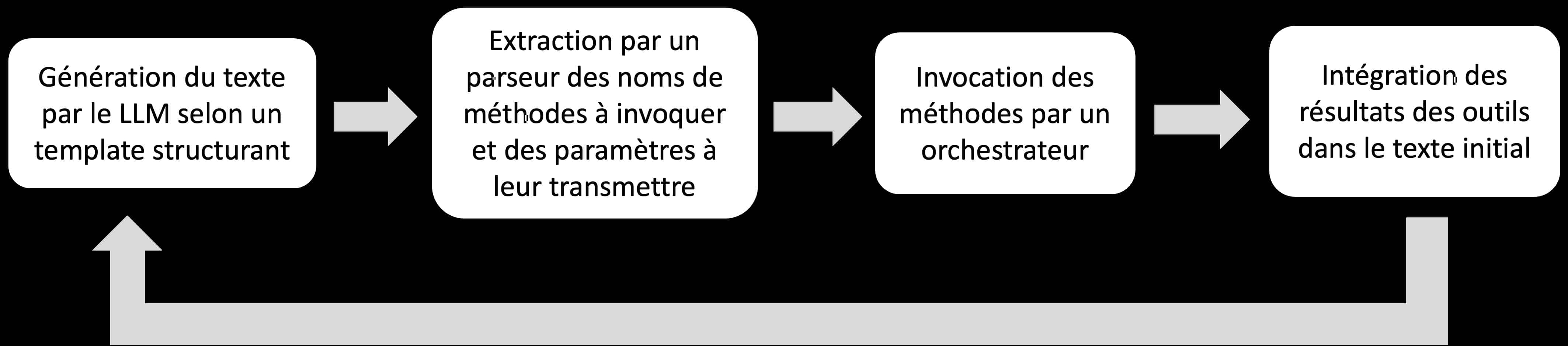
Le prompt engineering pour favoriser le raisonnement
Le paradigme dominant pour favoriser l’élaboration de chaînes de raisonnement par un LLM est, là encore, le prompt engineering. Rappelons pour commencer deux bonnes pratiques génériques dans la conception de prompts qu’il est utile d’avoir présent à l’esprit.
La première est de rédiger des instructions claires. Peu importe que ces instructions soient longues voire fastidieuses à décrypter pour un humain, l’essentiel est qu’elles soient dépourvues d’ambiguïté pour le LLM. La structuration se fait typiquement à l’aide de délimiteurs définis par des chaînes de caractères comme ‘‘ ‘‘ ‘‘ ou ###. L’utilisation de mots clés, p.ex encapsulés dans des balises <…>, est aussi encouragée.

La seconde bonne pratique est d’inciter un LLM à prendre son temps pour réfléchir. Sans une telle incitation un LLM aura tendance à générer des réponses dépourvues d’argumentation et faites, pour ainsi dire, à la volée. On peut par exemple spécifier explicitement les étapes d’un raisonnement qu’on souhaite le voir mener ou l’encourager à chercher sa propre solution à un problème avant de répondre à une question. Ces dernières remarques nous amènent naturellement à décrire deux techniques de prompt engineering conçues pour favoriser cette émergence de raisonnements logiques.
L’incitation au raisonnement avec la « Chain of Thought »
La première constatation à faire est que les aptitudes natives au raisonnement des LLM sont généralement assez limitées. S’ils parviennent sans trop de difficultés à résoudre des problèmes simples, ils achoppent souvent lorsqu’il s’agit d’enchaîner une longue séquence de déductions pour résoudre un problème complexe. Le cœur du challenge revient à surmonter ce qu’on appelle le compositionality gap. On désigne par cette expression la difficulté qu’ont les LLM (ou tout autre système d’IA) à décomposer dans un premier temps une tâche complexe en sous-tâches plus simples puis, dans un second temps, à élaborer une réponse à partir de ces réponses partielles. On peut considérer qu’il s’agit-là d’une des principales questions ouvertes de l’IA.
L’approche empirique du prompt engineering est à ce jour la voie la mieux explorée pour tenter d’améliorer les performances déductives des LLM. Dans sa forme la plus rudimentaire l’incitation à produire une chaîne de raisonnement consiste simplement à ajouter une courte phrase incitative du genre « Let’s think step by step » après le texte de la question pour laquelle on souhaite obtenir une réponse argumentée. C’est la méthode dite du Chain of Thought, d’une simplicité biblique mais d’une efficacité surprenante. C’est la version zero-shot du CoT :
Dans la version few shot du CoT on donnera plutôt un ou plusieurs exemples du type de raisonnement que l’on souhaite voir générer par le LLM :
La création d’une synergie entre action et réflexion avec « ReAct »
Confrontée à une tâche complexe qui exige l’élaboration préalable d’une stratégie, l’intelligence humaine parvient à combiner des phases de dialogue intérieur avec des phases de recherche d’information dans l’environnement. Ceci lui permet d’enrichir progressivement ce dialogue [10] jusqu’à parvenir, dans le meilleur des cas, à une solution. Un pattern de prompt a été récemment proposé [11] pour inciter un LLM à adopter un comportement analogue, il s’agit de l’approche ReAct, (pour « Reason + Action »). Un prompt ReAct comportera plusieurs exemples illustrant chacun une succession judicieuse d’étapes de réflexion, d’action puis d’observation. Ces étapes sont identifiées respectivement par les mots clés « Thought n», « Act n» et « Obs n » dans l’exemple ci-dessous :
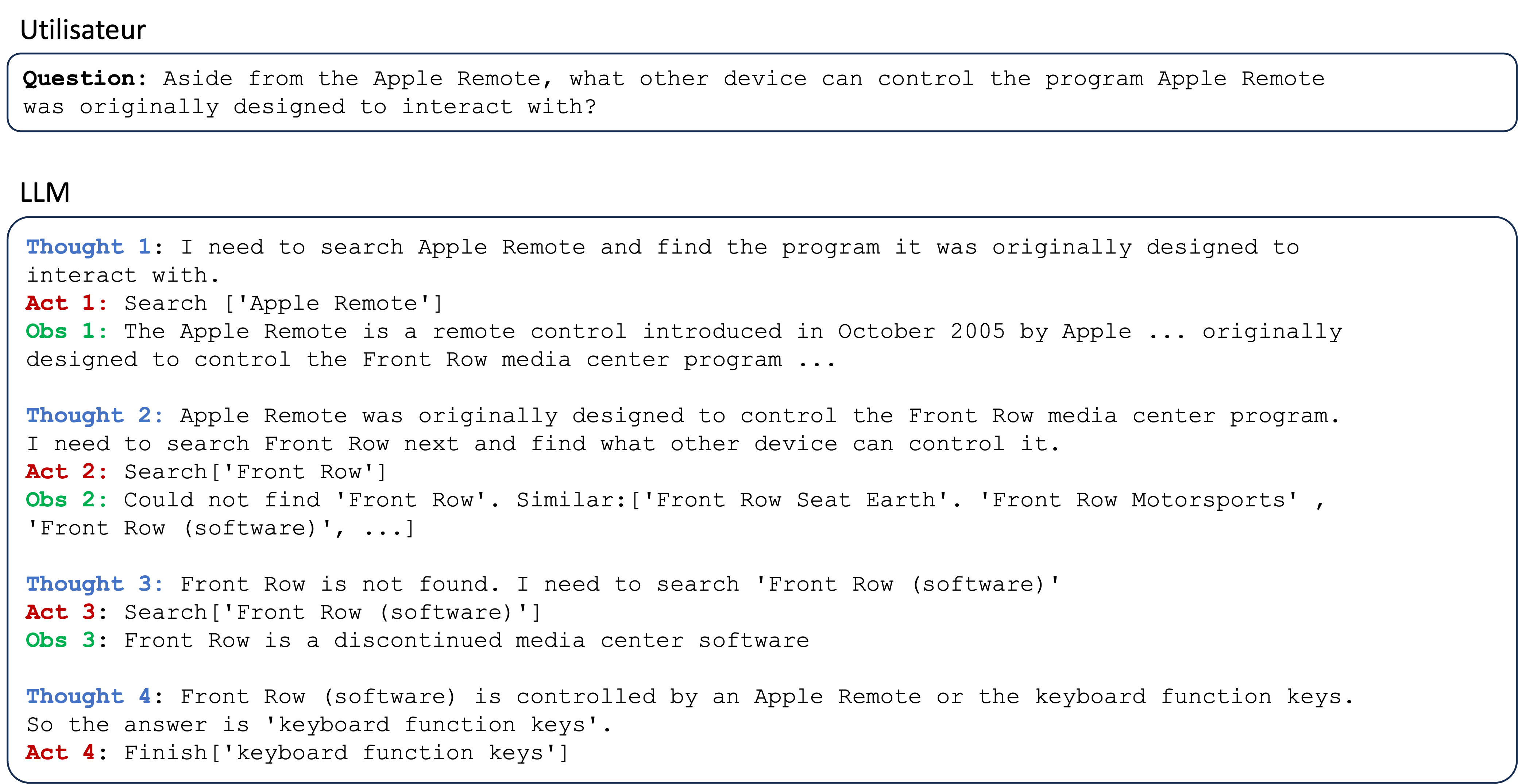
Un prompt de type ReAct comporte généralement entre un et dix exemples de tels enchaînements. Le lecteur averti remarquera au passage la similitude entre le pattern ReAct et l’apprentissage par renforcement (RL) [¹].
LangChain : une trousse à outils pour l’IA générative
Construire une application d’IA générative se résume pour l’essentiel en une démarche empirique et itérative durant laquelle sont mis au point des prompts qui incitent un LLM à adopter certains comportements avec une fiabilité acceptable. Le cycle de développement d’une application d’IA générative peut donc en principe être très court car aucune formalisation n’est requise. Le langage de programmation des prompts n’est autre que le langage naturel !
Certaines tâches restent malgré tout fastidieuses. La conception de prompts réutilisables dans différents contextes et pour les différents LLM du marché en est un exemple. De même, la mise au point de parseurs capables de décortiquer sans broncher les textes générés par un LLM, le développement de connecteurs aux différentes sources de données ou l’orchestration des différents processus peuvent s’avérer laborieux.
C’est avec l’intention de faciliter la conception d’applications d’IA générative à l’aide de modules réutilisables qu’a été conçu le framework open source LangChain. Sa prise en main pourra paraître de prime abord un peu intimidante aux débutants car l’articulation détaillée des différentes abstractions ne saute pas forcément aux yeux. Ce framework pourrait cependant rapidement devenir aussi incontournable que l’était scikit-learn pour le machine learning à l’ère pré-ChatGPT. Pour permettre au lecteur de se faire une première idée rapidement, voici une description succincte des quelques concepts structurants définis par LangChain.
Tous les exemples ci-dessous sont tirés de l’excellente série de cours de DeepLearning.AI.
Les PromptTemplate
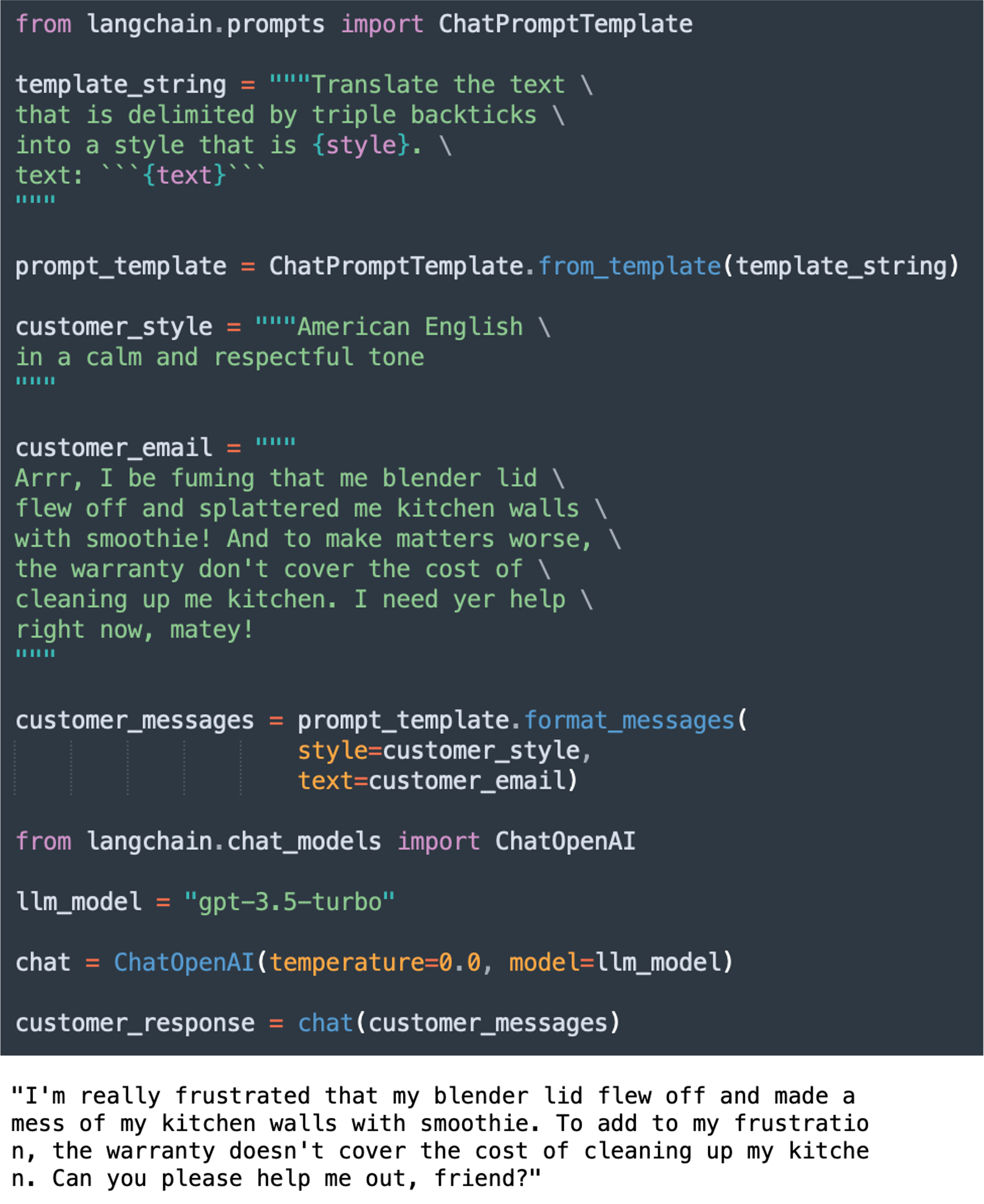
Les PromptTemplate de LangChain facilitent la construction de prompts paramétrables, adaptés à certaines tâches et à certains LLM. Ci-dessous l’exemple d’un template utilisé pour construire un chatbot à l’aide du LLM GPT-3.5-turbo d’OpenAI. On voit qu’il définit deux paramètres, l’un pour le texte en entrée, et l’autre pour le style à utiliser en sortie. Une fois le template instancié à l’aide une requête, on pourra le transmettre au LLM et obtenir la réponse du modèle :
Les LLMChain
Le concept central de LangChain, comme son nom l’indique, est celle d’une Chain qui permet d’enchaîner des traitements de plusieurs modules. La Chain élémentaire est la LLMChain qui définit un LLM spécifique associé à un prompt paramétrable. Dans l’exemple ci-dessous la LLMChain est conçue pour imaginer le nom d’une entreprise à partir d’une description des produits qu’elle vend :
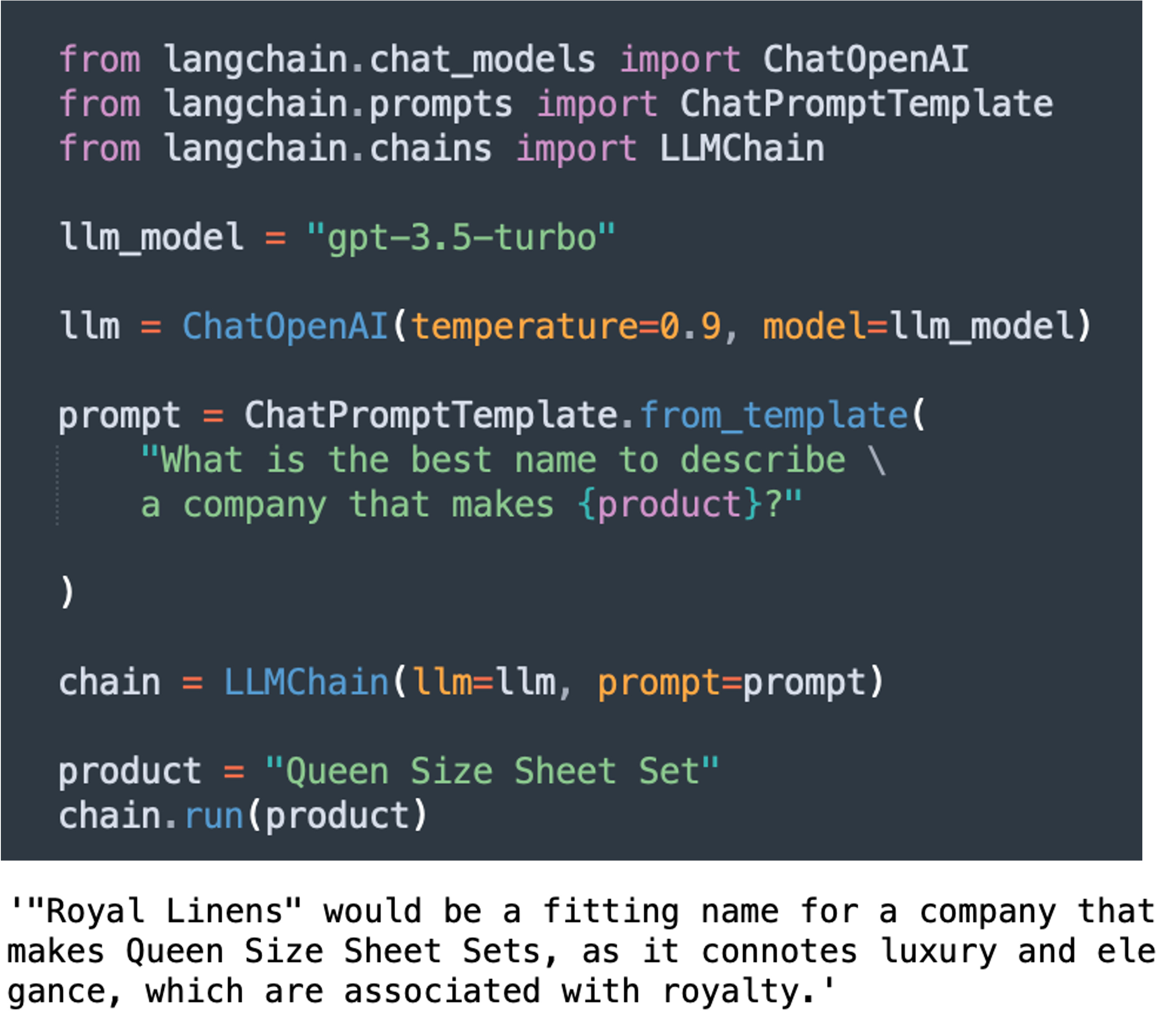
Les SimpleSequentialChain
La SimpleSequentialChain transmet la sortie d’un LLM (ou d’un autre module) à l’entrée du module suivant dans une séquence. Voici un exemple où le premier LLM est celui défini précédemment (qui imagine le nom d’une entreprise à partir d’un produit) et où le second est chargé de produire une courte description de l’entreprise à partir de son nom :
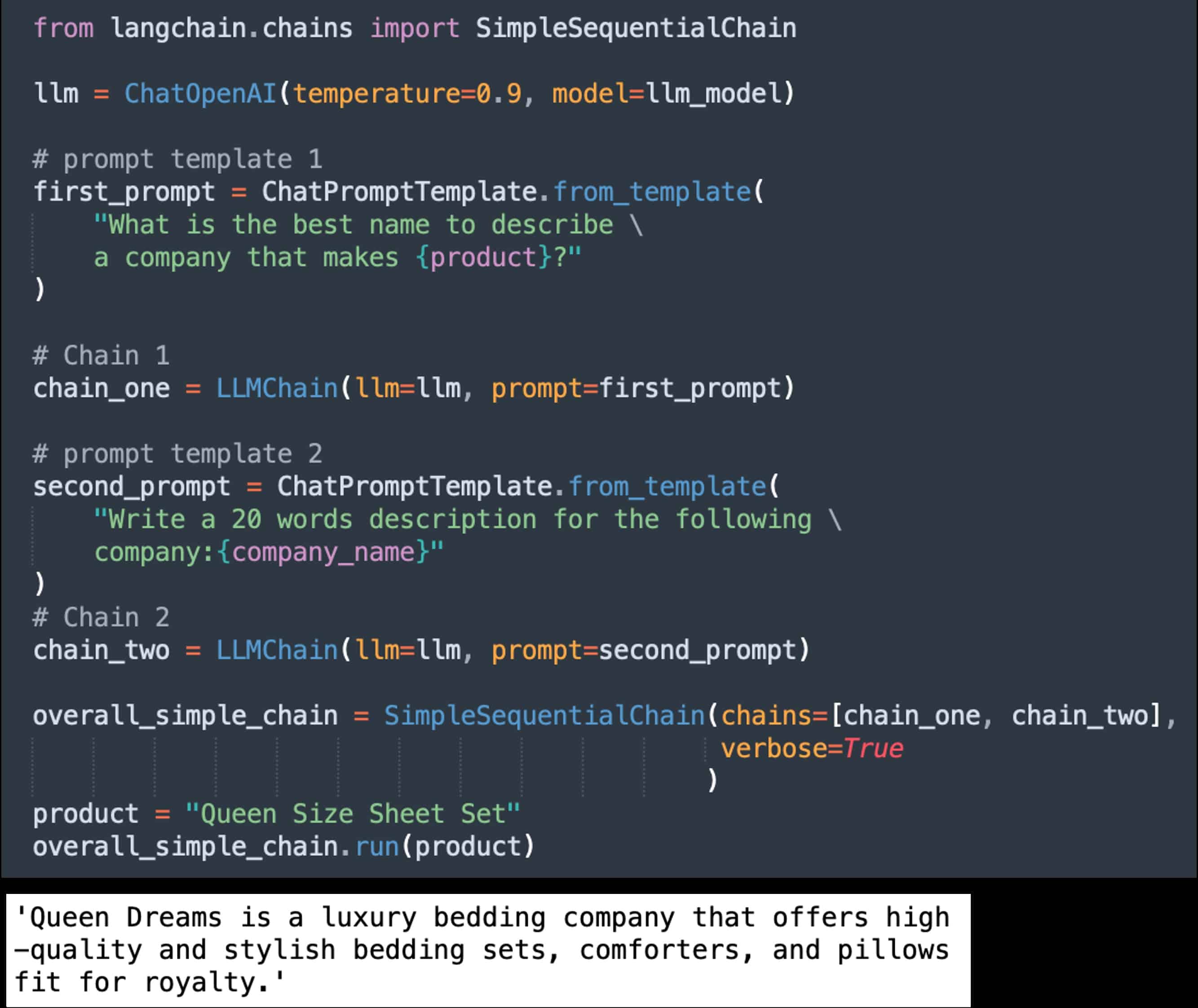
Les Agents
Les Agents sont les modules les plus sophistiqués de LangChain. Ce sont eux qui permettent entre autres d’intégrer des outils externes, appelés des tools. Voici un exemple simple d’intégration de deux outils prédéfinis, llm-math et wikipedia, où LangChain implémente en coulisse la mécanique ReAct décrite précédemment :

En mode verbose=True on peut observer le dialogue intérieur du LLM fait d’une succession d’étapes Thought, Action et Observation comme le définit le pattern ReAct :

La documentation de LangChain propose également des exemples d’applications génératives complètes pour les cas d’utilisations les plus courants des LLM comme la réponse à des questions (Q&A), le résumé automatique, l’analyse de code ou différents types de chatbots.
Ceci n’est que le début !
Les LLM sont tout à la fois des bases de connaissances généralistes interrogeables en langage naturel et des moteurs d’inférence dotés de sens commun. Ces caractéristiques en font des composants d’une grande polyvalence qui contribuent à redéfinir la manière de construire beaucoup d’applications prédictives. Les cycles de conception, d’expérimentation et de déploiement seront beaucoup plus courts, les jours pouvant se substituer aux semaines, du moins pour les cas d’usage classiques comme la classification de documents par exemple.
L’intégration de services et de connaissances externes promet, on l’a vu, de pallier certaines des faiblesses originelles des LLM comme leur manque de fiabilité factuelle, l’impossibilité dans laquelle ils sont de citer leurs sources ou le coût prohibitif qu’exige leur réentraînement pour mettre à jour certains faits. Pour autant, ces LLM, même ainsi augmentés, ont pour l’instant des limites qui coïncident souvent avec des questions fondamentales encore ouvertes de l’IA. Voici celles qui nous paraissent les plus importantes :
- Le compositionality gap que nous avons évoqué précédemment.
- Les capacités d’apprentissage des ALM sont limitées à chaque conversation et dépende
Auteur
-

Pirmin Lemberger
Docteur en physique théorique
-

CES 2026: Les 5 points à retenir
Article













