DeepSeek-R1, l’émergence d’un dialogue interne
Le 20 janvier dernier, la startup chinoise DeepSeek annonçait la sortie de son nouveau modèle Deepseek-R1, spécialisé dans les tâches de raisonnement. Au-delà de ses performances remarquables sur les différents benchmarks habituels, c’est son coût d’entraînement qui impressionne : moins de 6 millions de dollars, très loin des milliards investis par OpenAI et autres Anthropic.
Ces annonces ont provoqué un petit mouvement de panique dans la Silicon Valley et les indices boursiers de grandes entreprises de la tech américaine ont dévissé. Tentons, au travers de cet article, de comprendre ce qui rend DeepSeek-R1 si performant.
Vous avez sans doute remarqué que depuis quelques mois, a fait son apparition dans vos diverses interfaces de vos modèles de langues préférés, l’apparition d’un bouton « Raisonner ». (Voir Figure 1). Cliquer sur ce bouton active l’utilisation d’un autre modèle, spécialisé dans les tâches de raisonnement. Concrètement, ce modèle a la possibilité de « réfléchir », c’est-à-dire, écrire un brouillon pour s’aider avant de répondre à la question.
Alors qu’est-ce qu’une tâche de raisonnement ? Si l’on s’en tient aux définitions académiques [1] c’est une tâche qui consiste à tirer des conclusions à partir d’un ensemble d’informations. Plus spécifiquement, sa résolution nécessite (1) des capacités d’analyse et de synthèse (extraction des éléments pertinents) (2) des capacités d’inférence (établissement de liens logiques entre les informations) et (3) de capacité de planification (organiser séquentiellement les étapes pour parvenir à une conclusion). Si vous ne devez retenir qu’une chose d’une tâche de raisonnement c’est une question à laquelle on ne peut pas répondre en 1 phrase et pour laquelle il faut « assembler des briques ». Parmi les exemples classiques de tâches de raisonnement on retrouve les problèmes de mathématiques ou de code. La Figure 2 montre un exemple de tâche de mathématiques.

Cette capacité à raisonner, jusqu’ici propre aux humains, devient une propriété émergente des LLMs. Montrons comment l’entraînement du modèle DeepSeek-R1 a permis de favoriser l’apparition d’une telle capacité.
Ce qu’il est important de noter dès maintenant c’est que ce modèle DeepSeek-R1 est le premier modèle dit de « raisonnement » qui nous laisse entrer, au moins partiellement, dans le cœur du réacteur de l’entrainement. Ses concurrents o1 d’OpenAI ou Google Gemini Flash Thinking de Google ne sont pas open-source. Le rapport technique de R1 [2] sur lequel nous nous appuyons, constitue donc une ressource précieuse, dans la quête d’une compréhension approfondie de nos chatbots préférés. On exposera d’abord un point de vue global sur les méthodes d’entrainement avant de plonger en détail dans la recette de cuisine pour obtenir un DeepSeek-R1.
Les modèles de raisonnement
Des données de qualité en grande quantité : le nerf de la guerre
On le sait maintenant depuis quelques temps, les données avec lesquelles sont entrainés les modèles sont l’élément crucial pour obtenir d’excellentes performances. Traditionnellement, on opte pour un finetuning supervisé, c’est-à-dire faire apprendre à ces modèles à recopier des données que l’on sait correctes. Ces modèles de raisonnement n’y échappent pas, il faut un grand nombre de données, usuellement élaborées par des experts, qui contiennent une question et un ou plusieurs cheminements possibles pour générer une réponse (une démonstration). Et vous ne serez pas étonné si je vous dis que plus le problème est complexe, plus la réponse est longue, et plus l’annotation, par des experts est coûteuse, en temps et donc en argent. L’idée est de générer automatiquement ces données, non plus par des humains, mais par un modèle de langue, réduisant ainsi drastiquement les coûts et augmentant le nombre potentiel de données annotées. Bien que ce concept ne soit pas nouveau [13], c’est l’utilisation d’un entraînement par Reinforcement Learning qui représente la véritable avancée, en ouvrant la voie à la création autonome de ces données, en quantité potentiellement infinie.Un passage à l’échelle via le Reinforcement Learning
Parfois décrié [5] mais largement adopté [6,7], Le Reinforcement Learning (RL), ou apprentissage par renforcement en français, est une branche de l’intelligence artificielle qui vise à apprendre des stratégies permettant à un agent d’atteindre un objectif dans un environnement donné. Cet apprentissage repose sur un mécanisme d’essai-erreur, où l’agent interagit avec son environnement en prenant une succession d’actions qui lui valent des récompenses positives, négatives ou nulles. Par exemple, une voiture autonome apprend à rester sur la route en ajustant son volant : une bonne trajectoire est récompensée, tandis qu’une sortie de route ou un accident est pénalisé. Le but du RL est d’optimiser ces décisions pour maximiser la récompense cumulée. Un LLM peut être considéré comme un agent dont les actions sont les réponses textuelles qu’il génère et qui est récompensé pendant son entraînement si ces réponses sont correctes, tant sur le fond que sur la forme, et pénalisées sinon. Ce cadre a donné naissance au RLHF (Reinforcement Learning from Human Feedback), qui consiste à aligner les réponses des LLM avec les préférences des utilisateurs. Contrairement au RLHF, qui se contente majoritairement de réordonner des solutions existantes, nous nous intéressons ici au pur apprentissage par renforcement, visant à faire émerger de nouvelles solutions. En effet, il existe un grand nombre de tâches de raisonnement pour lesquelles il est très simple de vérifier si une réponse est bonne ou pas sans pour autant avoir besoin de sa démonstration. Ceci définit notre signal de récompense, qui est observé uniquement à la fin de la génération de la réponse. Exemple en est dans la Figure 2, imaginons que notre LLM après un long raisonnement nous propose comme solutions 0 et 4, on peut facilement vérifier que 0 est une solution à la question et que 4 ne n’est pas une. On peut donc présenter un grand nombre de problèmes de raisonnement au LLM, le faisant donc interagir avec l’environnement textuel et recevant une récompense positive lorsqu’il répond correctement aux questions (lorsqu’il trouve la réponse au problème de maths) et négative sinon. Le modèle apprend ainsi par essai-erreur sans que l’on ait besoin de lui présenter des solutions aux problèmes – coûteuses à produire – comme on le ferait dans un cadre dit ‘supervisé’. Alors bien-sûr, sur le papier c’est très alléchant, un modèle qui apprend tout seul et de fait, une littérature garnie existe déjà sur le sujet [4, 8]. Mais plusieurs problèmes persistent : d’abord, le signal de récompense est rare : l’agent reçoit peu de retours positifs, ce qui ralentit son apprentissage. Ensuite, l’espace d’action est immense ce qui possibles rend impossible l’exploration exhaustive. Enfin, le RL est connu pour son instabilité, rendant l’optimisation encore plus complexe. C’est donc là la prouesse de DeepSeek, réussissant à faire passer à l’échelle cet entrainement en mode RL, faisant émerger, sans supervision aucune, des comportements de raisonnement. Un point notable est que le modèle, pour raisonner toujours mieux, s’autorise à produire des réponses toujours plus longues au cours desquelles il réalise son auto-critique et explore diverses manières d’aborder les problèmes à résoudre (cf. la figure 3 qui montre que la longueur des réponses du modèle ne cesse d’augmenter au cours de l’entrainement)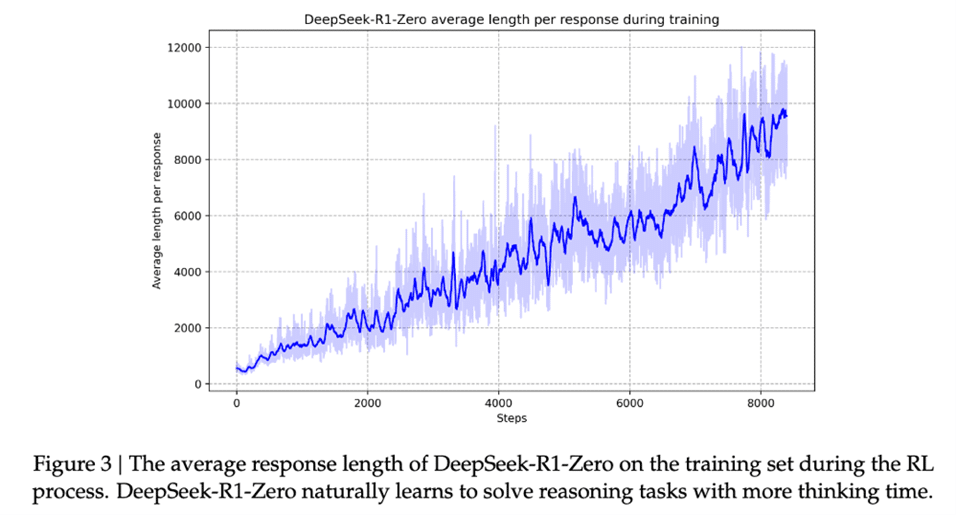
Il faut voir le modèle résultant de cet entrainement comme un savant qui a passé sa vie à explorer tout un tas de problèmes et qui a rédigé un grand nombre de brouillons, certains illisibles, certains mélangeant les langues, certains tout simplement faux, et certains bons, fournissant alors une démonstration détaillée à un problème de raisonnement.
Le RL : un moyen, pas une fin
L’étape suivante consiste donc à effectuer un tri parmi tous ces raisonnements. En sélectionnant les démonstrations à la fois vraies et lisibles on construit alors un gros jeu de données de raisonnement constitué d’un large corpus d’environ 600 000 exemples générés par ce modèle ayant appris à raisonner tout seul. Ces données constituent le cœur de l’entrainement de DeepSeek-R1, et la ressource cruciale qui lui permet de rivaliser sur tous les benchmarks de raisonnement avec le modèle o1 d’OpenAI, référence en la matière. Mieux encore, des plus petits modèles open-source (comme Llama, Qwen, etc.) ont été finetunés sur ce jeu de données, amenant à une amélioration significative de leurs performances. Cela a donc fait infuser la connaissance des gros modèles DeepSeek (disposant d’environ 700 milliards de paramètres) vers ces modèles plus frugaux, faisant ainsi profiter la communauté open-source et démontrant la qualité de ce jeu de données. Voilà qui conclut les grandes lignes de l’entraînement de R1. Les lecteurs pressés peuvent désormais passer directement à la section Discussion. Pour les plus curieux, entrons maintenant dans le détail des étapes d’entraînement de DeepSeek-R1.La recette de DeepSeek-R1
Pour démontrer l’utilité de l’entrainement en mode RL, le rapport technique [2] commence par proposer une version expérimentale de modèle de raisonnement nommé DeepSeek-R1-Zero. Avant toute chose, il faut savoir que l’on dispose du modèle pré-entrainé DeepSeek-V3-Base, qui est un modèle qui a suivi un pré-entrainement standard sur (presque) toutes les données textuelles du web et qui est déjà très performant sur des tâches classiques.Un “proof of concept” avec DeepSeek-R1-Zero
Partant du modèle DeepSeek-V3-Base, et au lieu de le finetuner sur des démonstrations de raisonnement comme l’usage le préconise, on fait le choix de lui faire suivre un entrainement à base uniquement de RL. Pour se faire, on lui présente un grand nombre de problèmes sous la forme d’un seul et unique prompt (voir Figure 4) (Toutes les figures sont issues de [3].)
Dans ce prompt, on demande explicitement au modèle de « réfléchir », entre des balises <think> et de donner une réponse finale entre les balises <answer>. Le signal de récompense est alors formé à partir de la véracité de la réponse et d’une récompense si le format utilisant les balises est respecté. L’algorithme de RL utilisé est GRPO (Group Relative Policy Optimization) [9], une variante du très utilisé PPO (Proximal Policy Optimisation) [10].
En lui donnant ce signal de récompense, le modèle apprend à raisonner seul, et comme précisé plus haut des comportements intéressants émergent, notamment la capacité à s’auto-évaluer ou à explorer de nouvelles solutions. Ce modèle est très performant mais n’est pas utilisable en pratique. On observe des problèmes de mise en forme, produisant des réponses souvent illisibles et ayant tendance à mélanger les langues. Le modèle a appris à raisonner, certes, mais pas dans les standards humains, il a sa propre langue. Cependant, c’est déjà une avancée en soit, un entrainement à si grande échelle avec du RL n’avait jamais été réalisé (de manière open-source) et constitue une base de travail pour le modèle suivant : DeepSeek-R1.
DeepSeek-R1
On est rassuré, on a réussi à faire émerger des capacités de raisonnement avec un prompt bien choisi et du RL à large échelle. Mais ce n’est pas parfait : le LLM ne produit pas toujours du contenu lisible. Reprenons tout depuis le début, avec un modèle qui ne sait pas raisonner. a. On commence par lui montrer quelques exemples bien choisis de raisonnements, c’est le « cold start ». Résultat : il a un point de départ, il sait un peu raisonner. b. On le met à l’épreuve avec du RL à grande échelle : il apprend par essai-erreur, cette fois en étant récompensé non seulement pour les bonnes réponses, mais aussi pour la lisibilité de son texte (ne faisons pas deux fois la même erreur). Résultat : un modèle qui raisonne bien et qui écrit correctement. c. Maintenant qu’il raisonne mieux, on lui demande de générer un grand nombre de démonstrations et on sélectionne les meilleures. Résultat : un corpus de raisonnements de haute qualité. d. Forts de ce corpus, on repart de zéro et on le modèle de base avec ces données. Résultat : un modèle qui sait vraiment bien raisonner. e. Dernière étape : on utilise le RL pour injecter des comportements souhaitables, alignés avec les préférences des utilisateurs, comme la helpfulness (réponses utiles) et la non-nocivité. Résultat : un modèle de raisonnement et qui, en plus, se comporte correctement. Détaillons à présent chacune de ces étapes.a. Des données « cold-start »
Pour encourager le modèle à raisonner comme un humain et afin d’augmenter la lisibilité du raisonnement, on va présenter au modèle DeepSeek-V3-Base un certain nombre de démonstrations, avant de lui faire faire un entrainement de RL à grande échelle. Ces quelques milliers de démonstrations sont générées par différentes méthodes de prompting ou sont extraites des quelques réponses lisibles de DeepSeek-R1-Zero. Dans tous les cas, elles sont sélectionnées par des annotateurs humains. On finetune ce modèle avec ces données (voir Figure 4). On nomme DeepSeek-V3-1 le modèle résultant de ce finetuning.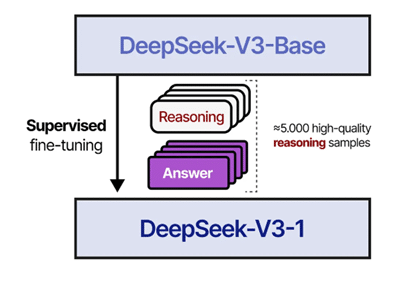
b. RL à grande échelle
Comme pour R1-Zero, on entraîne DeepSeek-V3-1 avec du RL en favorisant les démonstrations menant aux bonnes réponses. Cette fois, on tire les leçons de l’entraînement précédent : au-delà de la justesse des réponses et du format, on veille à ce que le modèle raisonne dans une seule langue pour éviter les dérives observées avec R1-Zero. On s’assure aussi que ses réponses restent lisibles pour un humain. Comme précédemment, une capacité de raisonnement impressionnante émerge. L’évolution de cet entraînement RL est illustrée en Figure 5. Le modèle ainsi finetuné est nommé DeepSeek-V3-2.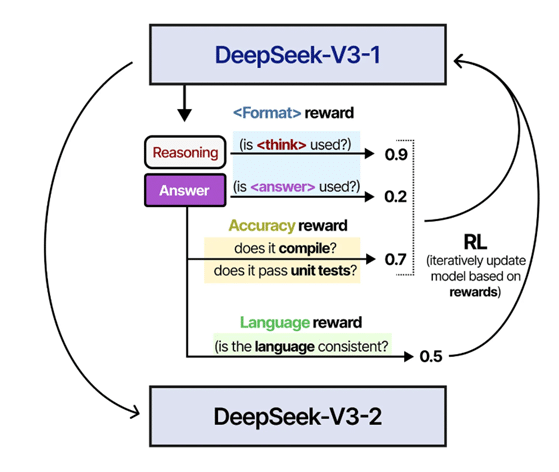
c. Curation des données et « Rejection sampling »
A partir de ce modèle entraîné par RL, on cherche à récupérer des démonstrations pour un grand nombre de nouveaux problèmes. Reprenons la métaphore faite plus haut : il faut voir ce modèle comme un savant ayant exploré tout un tas de problème de raisonnement. Lorsqu’on lui présente un nouveau problème, il va raisonner parfois correctement, parfois pas. Grâce à une technique de « rejection sampling » qui consiste à générer plusieurs démonstrations, pour un même problème, et sélectionner des démonstrations qui produisent une bonne réponse. Ici, une « bonne réponse » peut prendre plusieurs formes : soit une réponse qui génère un signal de récompense positif lorsque la solution est facilement vérifiable (comme en mathématiques ou en code), soit, lorsqu’une vérification directe n’est pas possible, une réponse que juge appropriée un autre LLM (en l’occurrence DeepSeek-V3 ici). Cette curation des données nous conduit à obtenir 600 000 démonstrations de raisonnement. En plus de ces données de raisonnement, et pour conserver la capacité du modèle à répondre à des questions qui ne nécessite pas de raisonnement, on récupère 200 000 données supervisées issues de jeu de données précédents [11]. Le processus de sélection des données est visualisé en Figure 6.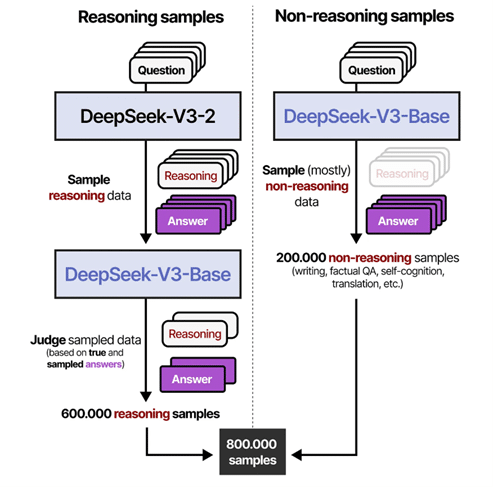
d. Entrainement supervisé
Maintenant qu’on a réussi à générer 800 000 exemples de qualité, on va faire ce qu’on sait le mieux faire : un entraînement supervisé. Ce finetuning est représenté en Figure 7.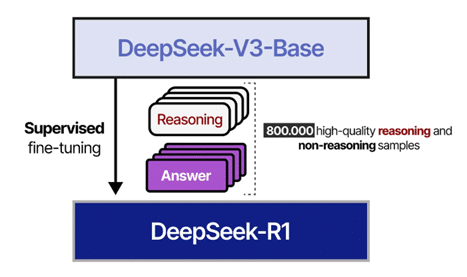
e. Reinforcement Learning pour tous les scenarios
Comme on ne change pas une équipe qui gagne, on va faire procéder à une étape d’entrainement de RL à ce modèle (qui rappelons-le, n’en a pas encore fait, lui). Cela va être fait de manière un peu différente que les entrainements à grande échelle des précédents modèles car à présent le signal de récompenses va se décomposer à la fois sur la réponse mais aussi sur l’alignement avec les préférences des utilisateurs, ainsi que la maximisation de sa serviabilité (helpfulness en anglais) et la minimisation de sa nocivité (harmfulness en anglais). Là encore, on visualise en Figure 8, cette partie de l’entrainement.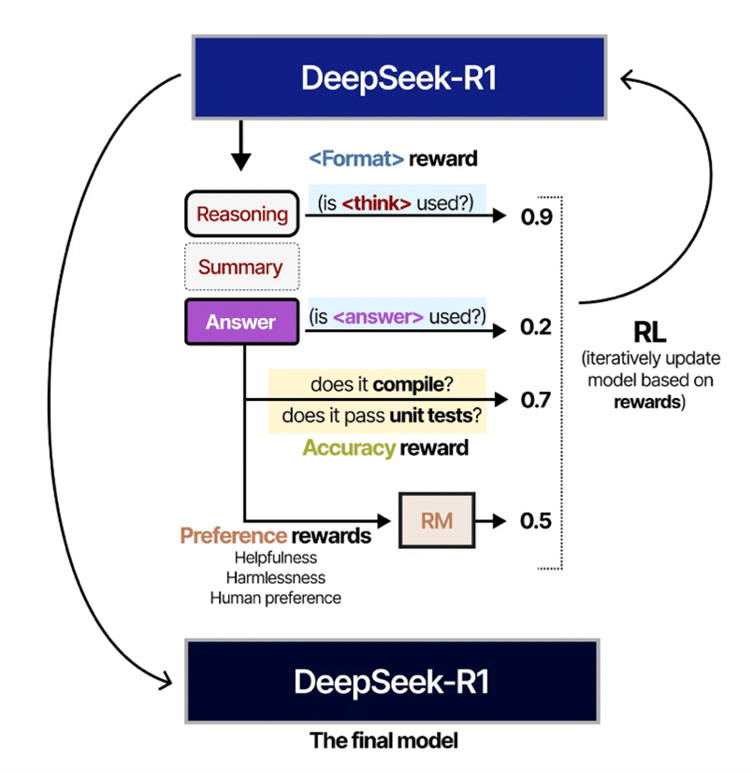
Et voilà le modèle final, DeepSeek-R1 ! Il n’est donc rien d’autre qu’un finetuning de DeepSeek-V3-Base de manière supervisée puis via du RL.
Résultats
Pour les courageux restés jusqu’ici, on montre ici rapidement quelques résultats quantitatifs sur les différents benchmarks de raisonnement usuels.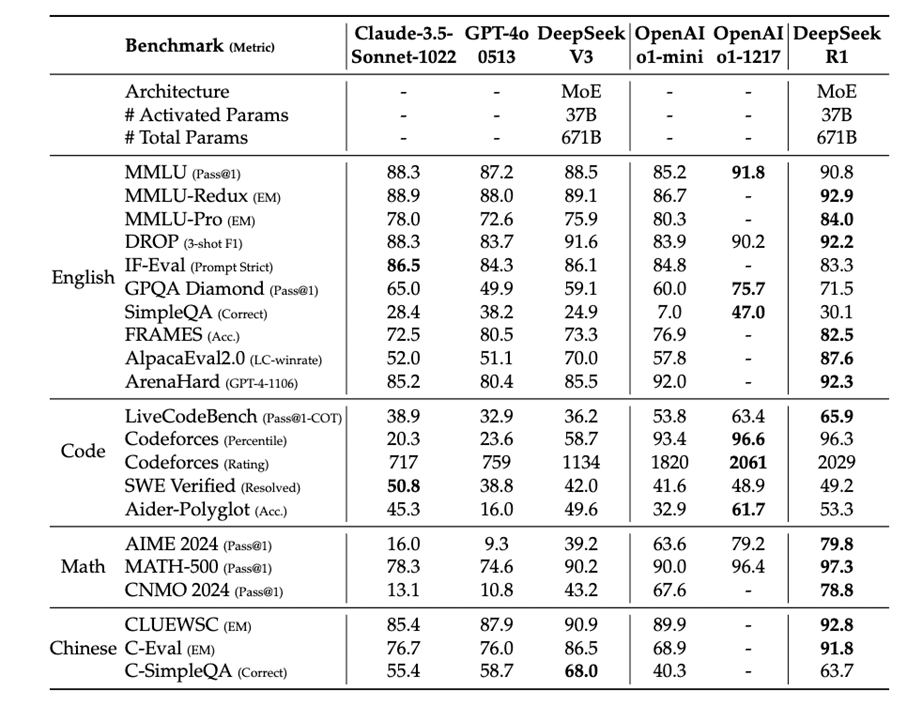
On observe en Table 1, la compétitivité de R1 avec les différentes versions de o1 et sa supériorité sur les autres modèles sélectionnés.
Discussion
Au vu des performances impressionnantes obtenues grâce au RL, on peut se demander si cette approche est universelle. En d’autres termes, peut-on entraîner directement un plus petit modèle avec du RL pour lui apprendre à raisonner ? Le rapport apporte quelques éléments de réponse en comparant deux approches sur un modèle environ 20 fois plus petit que DeepSeek-R1. D’un côté, il est entraîné à grande échelle avec du RL ; de l’autre, il est simplement finetuné sur les 800 000 démonstrations issues de l’entraînement de R1. Les résultats sont sans appel : la distillation par finetuning donne de bien meilleurs résultats. Pire encore, l’entraînement RL de ce modèle plus petit n’améliore même pas ses performances.
Ces résultats, présentés en Table 2, montrent que si le RL fonctionne bien sur de très grands modèles (comme DeepSeek-R1 ou o1, qui comptent plusieurs centaines de milliards de paramètres), il ne semble pas adapté aux modèles plus petits.
Cela corrobore des résultats connus de la littérature [4]. Des études sur les scaling laws (loi d’échelles en français) de ces méthodes d’entrainements sont donc nécessaires pour se faire un avis définitif.
Synthèse
On résume ici quelques points clés à retenir de cet article DeepSeek-R1. On note d’abord qu’un entrainement du LLM avec du RL s’est révélé très pertinent pour effectuer un travail exploratoire, et pour faire émerger des capacités de raisonnement. Ensuite, de cet entrainement, découlent des modèles qui sont capable de produire un grand nombre des démonstrations de haute valeur qui peuvent être utilisées pour finetuner des modèles comme R1 ou d’autres modèles plus petits. DeepSeek-R1 constitue donc un premier modèle de raisonnement open-source compétitif avec des modèles propriétaires. Le détail de sa méthodologie d’entrainement est aussi une ressource d’une grande valeur pour la communauté scientifique à des fins de reproductibilité. Évidemment, la méthode proposée est une méthode parmi d’autres. On peut donc tout à fait s’attendre à voir émerger, dans les prochains mois, des modèles aussi performants que DeepSeek-R1 et s’appuyant sur une pipeline d’entrainement différente.
Bibliographie
[1] Mondorf, J., & Plank, B. (2024). Beyond Accuracy: Evaluating the Reasoning Behavior of Large Language Models – A Survey. arxiv:2404.01869
[2] DeepSeek-AI. (2025). DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning. arxiv:2501.12948
[3] Grootendorst, M. (2024). A Visual Guide to Reasoning LLMs. Newsletter
[4] Havrilla, A., et al. (2024). Teaching Large Language Models to Reason with Reinforcement Learning. arxiv:2403.04642
[5] LeCun, Y. (2022). Twitter post on RL. X (formerly Twitter)
[6] Mnih, V., et al. (2013). Playing Atari with Deep Reinforcement Learning. arxiv:1312.5602
[7] Silver, D., et al. (2017). Mastering Chess and Shogi by Self-Play with a General Reinforcement Learning Algorithm. arxiv:1712.01815
[8] Vassoyan, J., et al. (2025). Ignore the KL Penalty! Boosting Exploration on Critical Tokens to Enhance RL Fine-Tuning. arxiv:2502.06533
[9] Shao, Z., et al. (2024). DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models. arxiv:2402.03300
[10] Schulman, J., et al. (2017). Proximal Policy Optimization Algorithms. arxiv:1707.06347
[11] DeepSeek-AI. (2024). DeepSeek-V3 Technical Report. arxiv:2412.19437
[12] Alibaba Group. (2024). Qwen2.5-Coder Technical Report. arxiv:2409.12186
[13] Huang, Y., et al. (2023). Large Language Models Can Self-Improve. arxiv:2210.11610
Auteur
-

Roman Plaud
Doctorant en machine learning














