Kafka, pierre angulaire des Architectures Fast Data ?
Dans les projets Big Data, le Data Streaming s’impose de plus en plus comme un nouvel impératif. Bonne nouvelle, c’est aussi le terrain de jeu de prédilection de Kafka.
Big Data ou Big Mess ?
Comment éviter que le Big Data ne devienne un « Big Mess » ? C’est pour répondre à cette question qu’en 2009 les équipes de LinkedIn, confrontées à des problématiques d’intégration de données auxquelles les outils disponibles ne répondaient pas, élaborent un nouveau bus de messages distribué : Kafka. Placé en 2011 sous l’égide de la fondation Apache, ce broker de messages connaît depuis une adoption croissante. Pour une raison essentielle : Kafka est dans la pratique bien plus qu’un bus. Et sa nature profonde en fait une brique de choix pour outiller les projets Big Data et, plus précisément, les scénarios qui recourent au Data Streaming. Explications.Apache Kafka, bien plus qu’un bus
Quand les équipes de LinkedIn se penchent sur le cahier des charges de leur bus idéal, c’est notamment par comparaison avec les limites des solutions existantes. Voilà pourquoi elles se fixent notamment comme objectif de concevoir un bus qui :- Garantit le découplage entre producteurs de données et consommateurs
- Supporte des consommateurs multiples
- Permet une forte scalabilité horizontale via une Architecture distribuée
- Met en œuvre la persistance des données
Data Streaming, le terrain de prédilection de Kafka
Et, de fait, les usages actuels de Kafka confirment ce positionnement. Dans une étude menée l’an passé (350 organisations interrogées dans 47 pays), si 50% des interrogés mentionnent « le messaging » parmi les tâches confiées à Kafka, 66% évoquent le « streaming process ». Parmi les cas d’usages, se détachent les data pipelines (81% de mentions), les Microservices (50%), ou encore la supervision temps réel (43%).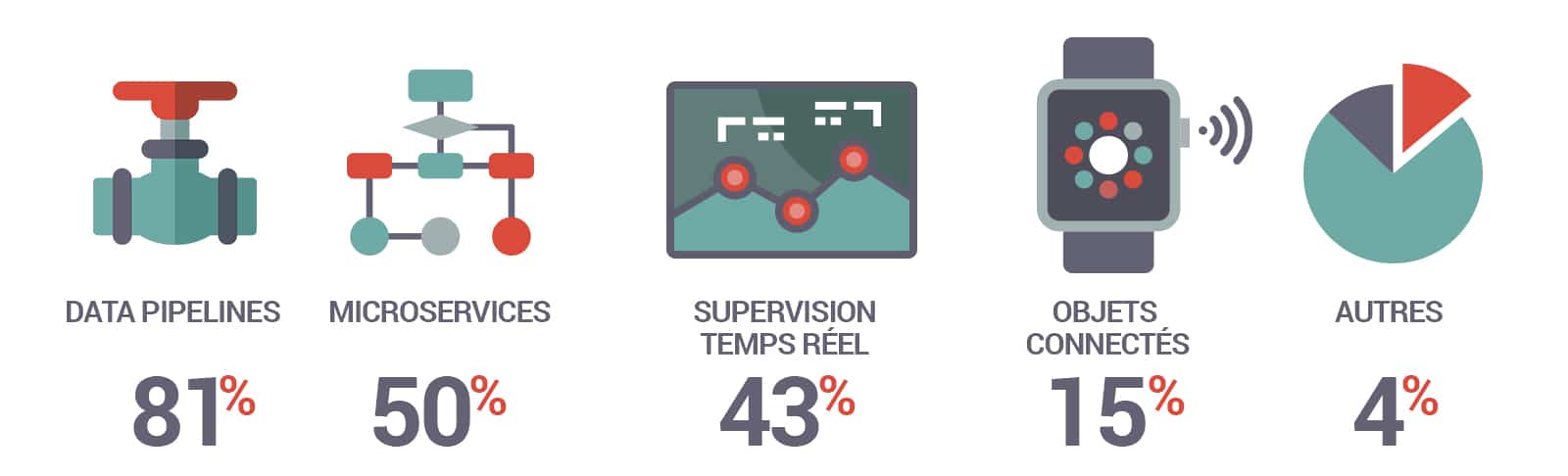
Cas d’usage les plus courants pour Apache Kafka (350 organisations interrogées dans 47 pays)
Parce que le Data Streaming désigne des données issues de sources variées et (surtout) générées de manière continue il est souvent associé à l’internet des objets (IoT). Dans la pratique, les traitements de ces données diffusées en continu se rencontrent dans bien d’autres cas d’usage : détection de fraudes dans le secteur de la finance, achats temps réel dans celui de la publicité digitale, supervision de la sécurité informatique. En fait, le Data Streaming s’impose dès qu’il s’agit de penser non plus « Big Data » mais « Fast Data », autrement dit, dès que la question de la vélocité des données prend le dessus.
Le temps réel, la nouvelle quête
« Le traitement temps réel de la donnée, c’est la quête des nouvelles plateformes Data, confirme Guillaume Drot, consultant Nexworld spécialiste des Architectures Big/Fast Data . Et Kafka permet de mettre en œuvre ce streaming pour traiter des événements au fil de l’eau, donc pour bâtir une chaîne de traitement en continu. L’Architecture hautement scalable s’avère particulièrement bien adaptée à ces usages ».Un « commit log » avant tout
Attention, Kafka n’est pas pour autant une baguette magique. « C’est un commit log, souligne Guillaume Drot, qui délègue plus de responsabilité aux applications qui consomment des messages. Il revient par exemple à ces applications de gérer des mécanismes d’accusé de réception là où d’autres brokers les intègrent plus nativement. »Attention aux formats des messages
Résultat, selon les scénarios, des bonnes pratiques s’imposent pour garder la maîtrise des flux de messages gérés via Kafka. Pour exploiter par exemple le streaming de données dans le cadre d’Architectures Microservices, une grande rigueur s’impose dans la définition des formats des messages. Objectif : sélectionner des IDs qui, injectés dans les messages, enrichissent les informations techniques ou métiers. « La bonne nouvelle, commente Guillaume Drot, c’est que la plateforme permet une gestion centralisée de ces formats ».Une « Single Source of Truth »
Au-delà de ces bonnes pratiques, de nombreuses librairies existent pour compléter l’outillage de Kafka. « Attention d’opter pour des librairies régulièrement maintenues et qui suivent au plus près les différentes évolutions de la plateforme », recommande Guillaume Drot. Des précautions à prendre pour tirer le meilleur parti de ce qui ressemble désormais plus à un système de stockage qu’à un bus. Avec une vocation clairement assumée : faire office de « Single Source of Truth » à l’ère du Big (et Fast) Data.Auteur
-

onepoint
beyond the obvious














