Machine Learning : comment industrialiser vos modèles ?
La Data Science, domaine prometteur qui continue de séduire de plus en plus d’entreprises, peine à être intégré dans des processus d’industrialisation. La combinaison entre donnée, algorithme, mathématiques, infrastructure technique, devOps, API, entre autres, fait appel à de nouvelles compétences et au besoin d’une sensibilisation transverse, pour mener à bien la mise en production de modèles de Machine Learning. Nous allons aborder tous les points critiques pour industrialiser un modèle de Machine Learning.
Une phase d’expérimentation éprouvée
Ce n’est plus une surprise pour personne, la donnée va continuer à croître en volume dans les entreprises. Toutes ces données, véhiculant des informations toujours plus précises et toujours plus riches, sont un catalyseur aux champs des possibles, tant pour les Métiers que pour l’IT. De nouveaux besoins se font sentir. Parmi eux, un sujet se distingue comme une priorité pour tous types d’entreprises : l’exploitation des données avec des algorithmes de Machine Learning. Pour ne citer que quelques grands exemples :- La détection de fraude dans des signaux faibles
- La gestion d’alertes corrélées à des changements d’état des données
- La détection de changement de tendances et également de comportements suspects
- La mise en production de modèles de Machine Learning
- L’apport des données aux modèles
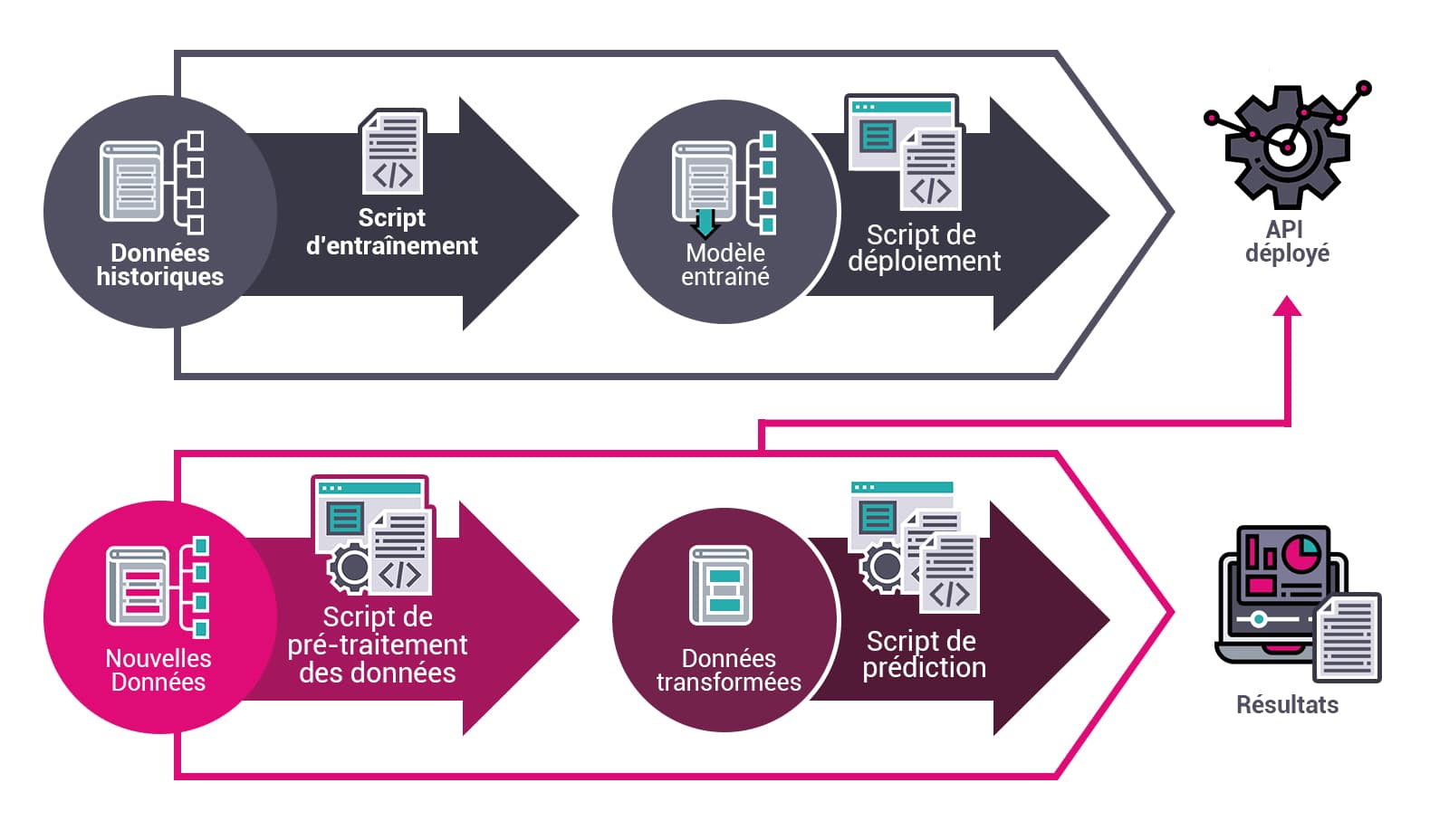
Ce schéma représente un modèle de Machine Learning déployé et accessible via une API avec un pipeline de traitement qui récupère les données et les injecte directement dans ce modèle pour en extraire les résultats.
Dans ce processus, il faut distinguer deux grands axes de travail :
- Le déploiement et l’accessibilité des modèles de Machine Learning
- L’apport des données, en temps réel ou en batch, pour réaliser les prédictions à partir de ces modèles
Le déploiement des modèles de Machine Learning
Quels sont les inputs ?
Le processus de déploiement de modèles de Machine Learning requiert plusieurs entrées :- Un accès à l’ensemble des données brutes nécessaires à l’entraînement du modèle
- Un script d’entraînement développé par des Data Scientists
- Une plateforme pour réaliser l’entraînement de modèles (On-premise ou Cloud)
- Un script pour déployer le modèle en production via une API
- Une plateforme cible pour déployer le modèle (On-premise ou Cloud)
- L’étape d’entraînement
- L’étape de déploiement
Vers une approche DevOps pour garantir la pérennité des modèles
Comme des projets IT, le déploiement de modèle de Machine Learning peut être intégré dans un déploiement continu DevOps. Contrairement à l’idée reçue, l’entraînement d’un modèle à un instant « T » ne garantit pas sa performance dans les jours/semaines/mois à venir. En effet, les performances d’un modèle de Machine Learning sont directement liées aux données avec lesquelles il a été entraîné. S’il reçoit des nouvelles données avec une nature différente de celles utilisées lors de son entraînement, alors, le modèle de Machine Learning fonctionnera très mal. Au regard de cela, il est intéressant de pouvoir ré-entraîner un modèle facilement et rapidement sur de nouvelles données. Lorsque l’on parle de ré-entraînement de modèle, il s’agit de la création d’un nouveau modèle qui n’a plus les mêmes caractéristiques que l’ancien. Dès lors, pour pouvoir profiter des nouvelles caractéristiques de ce modèle, il faut être en mesure de le redéployer. On pourra notamment citer cette entreprise française de ciblage publicitaire sur internet, prestigieuse et internationalement reconnue, qui réentraîne ses modèles toutes les 4 à 6 heures pour avoir la recommandation d’achat la plus précise possible à proposer aux internautes.Le load balancing pour assurer la scalabilité
La scalabilité est un enjeu fort pour les applications. Une des méthodes les plus connues pour y répondre est le load balancing. Or, l’utilisation du Machine Learning apporte des contraintes supplémentaires par rapport à un « load balancing classique ». La contrainte principale découle directement du temps de traitement nécessaire pour charger le modèle en mémoire, par les différentes instances lors de leur démarrage : plus la taille du modèle est importante plus le temps de chargement en mémoire est long. Par exemple, pour répondre à des cas d’usage présentant de forts pics de charge, il faut être en mesure de déployer de nouvelles instances à la demande. Néanmoins, déployer de nouvelles instances avec des modèles de plusieurs centaines de méga-octets voire plusieurs giga-octets peut s’avérer long, surtout lorsque l’on veut faire du traitement à la seconde (on parle ici de plusieurs minutes, voire dizaines de minutes de déploiement). Pour pallier ce problème, une première solution est de créer des instances « dormantes » et de répartir la charge sur ces instances en cas de pic d’activité. Cependant, cette solution entraîne des coûts supplémentaires, d’autant plus si la facture est un produit du nombre de machines instanciées. Une autre solution serait d’auto-scaler les instances en fonction de la charge, évitant ainsi d’avoir des machines utilisées uniquement en cas de pic de charge. Certaines solutions comme AWS Sagemaker proposent déjà ce type de service. Néanmoins, en cas de pics de charge brutaux, le temps que les nouvelles instances soient déployées, certains messages ne pourront pas être traités. L’article de blog sur l’apport des messages en temps réel décrit quel process adopter pour ne pas perdre de messages.Gérer la dérive des modèles
Comme précisé précédemment, un modèle de Machine Learning ne reste pas performant éternellement. Il faut donc être en mesure de détecter quand un modèle ne l’est plus et mener des actions en conséquence. Il y a ainsi un intérêt à définir des seuils de validation basés sur des métriques mathématiques définies avec les Métiers. Cependant, dans le cas d’un apprentissage supervisé, pour utiliser ces métriques, il est nécessaire d’avoir une « vérité » issue du terrain (ground truth). Or, il est courant que ces données ne soient pas générées en même temps que les prédictions. Il en découle une conséquence directe : ce seuil ne peut donc pas toujours être évalué en temps réel.Quel processus pour le déploiement d’un nouveau modèle ?
Après avoir ré-entraîné un modèle et avant qu’il ne soit déployé en production en remplacement de la version précédente, il est important de vérifier qu’il fonctionne mieux que l’ancien. Pour cela, on utilise en général des méthodes d’A/B testing avant de dé-commissionner l’ancien modèle. Il est important de pouvoir intégrer ce type de test dans le pipeline DevOps.Dégradation des données d’entraînement
L’utilisation d’algorithmes de Machine Learning n’est pas anodine sur le comportement des applications et notamment sur les données que les applications vont continuer à stocker. Par exemple : dans le cas de la détection de fraude, tous les faux positifs (personnes prédites comme fraudeuses alors qu’elles n’allaient pas frauder) seront bloqués avant la fin du parcours d’achat. L’arrêt du parcours en cours (dû à la prédiction de la personne comme fraudeuse) empêchera le stockage de l’intégralité des données du parcours. Or, pour ne plus détecter ces faux positifs, il faudrait pouvoir ré-entraîner le modèle avec ces données qui auraient été mal classifiées. Cependant, puisque ces données ne sont plus stockées, il devient impossible d’améliorer le modèle. Une solution parmi d’autres pour pallier ce problème : créer un flux qui ne passerait pas par le modèle et irait directement alimenter la base d’apprentissage.Deal entre performance et taille du modèle
Lorsque l’on veut améliorer la performance d’un modèle, il n’est pas rare de lui fournir plus de données en entrée, ou de faire de l’apprentissage ensembliste (qui utilise plusieurs algorithmes d’apprentissage pour obtenir de meilleures prédictions). Ces méthodes impactent directement la taille du modèle, le rendant certes plus performant mais aussi bien plus volumineux (le sujet sera abordé plus en détail dans un article dédié). Il arrive que ces méthodes n’apportent que de faibles améliorations par rapport au modèle de base. Comme décrit dans le chapitre du load balancing, la taille du modèle impacte directement le temps de déploiement et le nombre de messages qui peuvent être prédis. Il est donc intéressant de faire une étude pour avoir le meilleur rapport entre la performance du modèle et sa taille. Dans cette démarche on pourra notamment citer Google qui a lancé des compétitions Kaggle, lors desquelles les compétiteurs avaient pour objectif de créer le modèle de prédiction d’image le plus performant, tout en gardant une taille inférieure à 1 Go.Quelles plateformes pour déployer des modèles ?
Les grands fournisseurs Cloud proposent aujourd’hui des services clés en main pour le déploiement et l’exposition de modèles dans le Cloud. Ces services couvrent toutes les étapes depuis l’entraînement du modèle jusqu’à son exposition via APIs. Les grands avantages de ces plateformes sont de :- Proposer un panel de machines avec des performances configurables pour entraîner des modèles et les déployer
- Faciliter une intégration DevOps
- Proposer une brique de sécurité pour l’exposition des modèles via APIs.
Pluralité des compétences, facteur principal de réussite
En résumé, le déploiement de modèle de Machine Learning est un processus complexe qui demande de bien comprendre tous les enjeux relatifs à l’utilisation et à l’exploitation du modèle de Machine Learning pour pouvoir être correctement réalisé. Il est très rare qu’une seule personne regroupe toutes les compétences pour :- Comprendre le besoin Métier
- Produire un ou plusieurs modèles de Machine Learning
- Industrialiser le ou les modèles
- Récupérer les données par batch ou en temps réel
- Utiliser le modèle déployé sur les données
Auteur
-

onepoint
beyond the obvious














